《Python深度学习》——第一章 什么是深度学习
本章内容:
- 基本概念的定义
- 机器学习发展的时间线
- 深度学习日益流行的关键因素及其未来潜力
1.1 人工智能、机器学习与深度学习
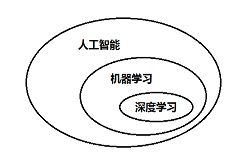
1.1.1 人工智能
人工智能定义:努力将通过由人类完成的智力任务自动化。
硬编码规则
符号主义人工智能(symbolic AI) 专家系统(expert system)
机器学习(machine learning)
1.1.2 机器学习


新的编程范式:输入数据和这些数据中预期得到的答案,输出规则。
机器学习与数理统计密切相关。
机器学习工程导向,理论较少。
1.1.3 从数据中学习表示
三个要素进行机器学习
- 输入数据点
- 预期输出的示例
- 衡量算法效果好坏的方法
深度学习和机器学习核心问题:有意义地变换数据。表征数据或将数据编码
机器学习中的学习:寻找更好数据表示的自动搜索过程。坐标变换、线性投影、平移、非线性操作。
机器学习的技术定义:在预先定义好的可能性空间中,利用反馈信号的指引来寻找输入数据的有用表示。
1.1.4 深度学习之“深度”
深度学习的深度指:一系列连续的表示层。
别称:分层表示学习(layered representations learning) ,层级表示学习(hierarchical representations learning)
浅层学习(shallow learning):其他机器学习,仅有一两层数据。
将深度网络看作多级信息蒸馏操作:信息穿过连续的过滤器,其纯度越来越高。
深度学习技术定义:学习数据表示的多级方法。
1.1.5 用三张图理解深度学习的工作原理
权重,参数化(parameterize),参数(parameter),学习
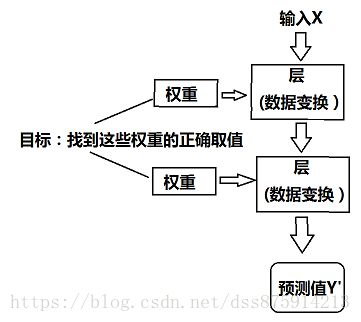
损失函数(loss function),目标任务(objective function)
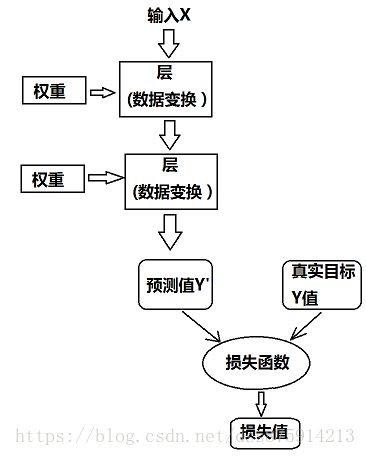
基本技巧:利用距离值作为反馈信号来对权重值进行微调。
优化器(optimizer),反向传播(backpropagation)
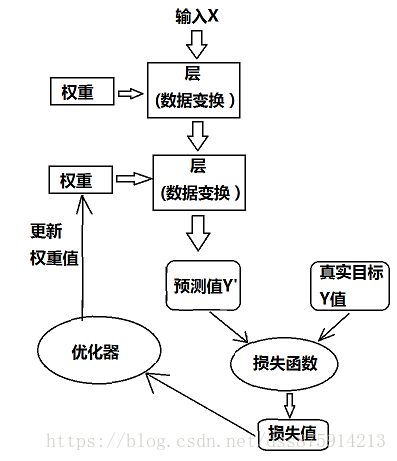
训练循环(training loop)
1.1.6 深度学习已经取得的进展
在视觉和听觉等感知问题取得很好的成果。
取得的突破
- 接近人类水平的图像分类
- 接近人类水平的语音识别
- 接近人类水平的手写文字转录
- 更好的机器翻译
- 更好的文本到语言转换
- 数字助理
- 接近人类水平的自动驾驶
- 更好的广告定向投放
- 更好的网络搜素结果
- 能够回答用自然语言提问的问题
- 在围棋上战胜人类
1.1.7 不要相信短期炒股
短期技术不能医用,可能投资资金会停止。
之前已经经历了2次人工智能冬天。
1.1.8 人工智能的未来
短期期望可能不切实际,但长远来看前景是光明的。
目前技术只是生活的陪衬。
1.2 深度学习之前:机器学习简史
1.2.1 概率模型(probabilistic modeling)
例:
朴素贝叶斯算法,假设:数据特征独立。
logistic回归:是分类算法。数据科学家首先会用这个算法,以便初步熟悉手头分类任务。
1.2.2 早期神经网络
1989年,卷积与反向传播算法相结合。
1.2.3 核方法(kernel method)
支持向量机(SVM,support vector machine):决策边界(decision boundary)
SVM通过两步来寻找决策边界
- 将数据映射到一个新的高维表示
- 让超平面与每个类别最近的数据点之间的距离最大化 间隔最大化(maximizing the margin)
核技巧(kernel trick)
核函数(kernel function)
需要先做:特征工程
SVM难扩展到大型数据集
1.2.4 决策树(decision tree)、随机森林与梯度提升机
随机森林(random forest):建立许多决策树,然后将他们的输出集成在一起。
梯度提升机(gradient boosting machine):目前处理非感知数据最好的算法。
1.2.5 回到神经网络
计算机视觉
图像分类挑战赛(ImageNet):2015:96.4%
1.2.6 深度学习有何不同
不需要设计特征工程
深度学习:模型可以在同一时间共同学习所有表示层,并不是依次连续学习(贪婪学习)
基本特征:
- 通过渐进的、逐层的方式形成越来越复杂的表示
- 对中间这些渐进的表示共同进行学习
1.2.7 机器学习现状
Kaggle
XGBoost
Keras
1.3 为什么是深度学习,为什么是现在
深度学习用于机器视觉,关键思想:卷积神经网络和反向传播。
长短期记忆(LSTM,long short-term memory)
主要推动力
- 硬件
- 数据集和基准
- 算法上的改进
1.3.1 硬件
深度学习网络主要由许多小矩阵乘法组成,具有高度并行化。
GPU,TPU
CUDA
1.3.2 数据
深度学习是蒸汽机车,数据是煤炭。
Flickr网络生成图像标签
YouTube视频
维基百科:自然语言处理
1.3.3 算法
之前,随着层数增加,神经网路反馈信号消失。
改进
- 激活函数(activation function)
- 权重初始化方案(weight-initialization scheme)
- 优化方案(optimization scheme)
- 批标准化、残差连接和深度可分离卷积
1.3.4 新的投资热潮
钱:1900万$ 到 3.94亿$不包括Google公司内部的现金流
1.3.5 深度学习的大众化
之前C++和CUDA
现在Python Theano Tensorflow Keras
1.3.6 这种趋势会持续吗
深度学习核心概念
- 简单
- 可扩展性
- 多功能与可复用
科学发展S形曲线。