Spark 2.3.0+Kubernetes应用程序部署
Spark2.3.0+Kubernetes应用程序部署
Spark可以运行在Kubernetes管理的集群中,利用Native Kubernetes调度的特点已经被加入Spark。目前Kubernetes调度是实验性的,在未来的版本中,Spark在配置、容器映像、入口可能会有行为上的变化。
(1) 先决条件。
- 运行在Spark 2.3 或更高版本上。
- 运行Kubernetes cluster 1.6以上版本,访问配置为使用kubectl。如果不止一个Kubernetes集群,可以使用minikube在本地设置一个测试集群。
- 建议使用DNS插件的minikube最新版本。
- 注意,默认minikube配置不够运行Spark的应用,推荐使用3 CPUs、4G内存的配置,能够启动包含一个Executor的Spark应用程序。
- 必须有适当的权限在集群中列表,创建,编辑和删除Pods,通过kubectl auth can-i
- 在集群配置Kubernetes DNS。
(2) 工作原理。Kubernetes工作原理如图2-1所示。
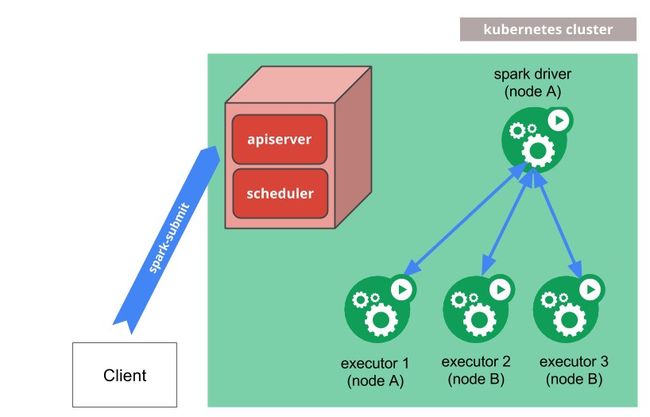
图 2- 1 Kubernetes原理图
Spark-Submit可直接提交Spark应用到Kubernetes集群,提交机制是:
l Spark创建Spark Driver,运行在一个Kubernetes pod。
l Driver创建Executors,运行在 Kubernetes pods,并执行应用程序代码。
l 当应用程序完成时,Executor pods将终止和清理,但Driver pod持久化到日志,在KubernetesAPI保留“完成”状态,直到最终垃圾回收或手动清理。注意:在完成状态,Driverpod没使用任何计算或内存资源。
Driver和Executor pod由Kubernetes调度。使用配置属性通过节点选择器在Driver和Executor节点的一个子集中调度是可能的。这将可能在未来的版本中使用更先进的调度提示,例如:node/podaffinities。
(3) 提交应用到Kubernetes。
Docker 镜像:Kubernetes要求用户提供的镜像可以部署到容器内的pods。镜像
是建立一个Kubernetes支持的容器运行时环境。Docker是一个Kubernetes经常使用的容器运行环境。Spark(从2.3版开始)使用Dockerfile,或定制个性化的应用,可以在目录kubernetes/dockerfiles/中发现。Spark还附带了一个bin/docker-image-tool.sh脚本,可以用来构建和发布Docker镜像,使用Kubernetes后端。
例如:
$ ./bin/docker-image-tool.sh -r
$ ./bin/docker-image-tool.sh -r
(4) 集群模式。
在集群模式提交Spark Pi程序。
$ bin/spark-submit \
--masterk8s://https://
--deploy-modecluster \
--name spark-pi\
--classorg.apache.spark.examples.SparkPi \
--confspark.executor.instances=5 \
--confspark.kubernetes.container.image=
local:///path/to/examples.jar
Spark Master,在Spark-Submit中指定--master命令行参数,或者在应用程序配置文件里面设置spark.master,必须是一个URL的格式k8s://
在Kubernetes模式中,通过spark.app.name或--name参数指定Spark的应用名称,Spark-Submit使用默认名称提交,Kubernetes创建的资源例如Drivers和Executors。应用程序名称必须由小写字母、"-"、和"."组成,开始和结束字符必须是一个字母数字字符。
如果有一个Kubernetes集群setup,发现服务器的API URL的方法之一是通过执行kubectl cluster-info查询集群信息。
$ kubectl cluster-info
Kubernetes master is running at http://127.0.0.1:6443
在上面的例子中,可以用Spark-Submit在Kubernetes集群提交程序,通过指定--masterk8s://http://127.0.0.1:6443提交。另外,也可以用认证代理kubectl proxy联系Kubernetes API。
本地代理启动:
$ kubectl proxy
如果本地代理是运行在localhost:8001,--master k8s://http://127.0.0.1:8001可以作为Spark-Submit参数提交应用。最后请注意,在上面的例子中,我们指定一个特定的URI方案local://, 这个URI例子的Jar包已经在Docker镜像中。
(5) 依赖管理。
如果应用程序的依赖关系都托管在HDFS或HTTP服务器的远程位置,可通过适当的远程URI引用。此外,应用程序依赖关系可以预先安装到定制的Docker镜像。依赖可以借鉴类路径添加到当地URI local://及/,或在Dockerfiles设置环境变量,设置SPARK_EXTRA_CLASSPATH。local://模式要求在依赖定制的Docker镜像。注意,目前还不支持使用从提交客户端的本地文件系统的依赖。
(6) 使用远程的依赖。
当应用程序依赖HDFS或HTTP服务器托管在远程位置,Driver和Executor pods
需要Kubernetes初始化容器下载依赖,这样Driver和Executor容器可以在本地使用。
初始化容器处理远程依赖需指定spark.jars(或Spark-Submit的--jars )、spark.files(或Spark-Submit的--files参数),处理远程托管主要应用资源。例如:主程序Jar,下面显示了Spark-Submit使用远程依赖的一个例子:
$ bin/spark-submit \
--masterk8s://https://
--deploy-modecluster \
--name spark-pi\
--classorg.apache.spark.examples.SparkPi \
--jarshttps://path/to/dependency1.jar,https://path/to/dependency2.jar
--fileshdfs://host:port/path/to/file1,hdfs://host:port/path/to/file2
--confspark.executor.instances=5 \
--confspark.kubernetes.container.image=
https://path/to/examples.jar
(7) 密钥管理。
Kubernetes密钥可以用来提供Spark应用访问安全服务证书。安装用户指定的密钥到Driver容器,用户可以使用配置属性spark.kubernetes.driver.secrets.[SecretName]=
--confspark.kubernetes.driver.secrets.spark-secret=/etc/secrets
--confspark.kubernetes.executor.secrets.spark-secret=/etc/secrets
注意,如果一个初始化容器被使用,任何密钥安装到Driver的容器也将被安装到Driver的初始化容器。同样,任何密钥安装到Executor的容器也将被安装到Executor的初始化容器。
(8) 自省与调试。
这些都是观测Spark应用程序运行、应用程序完成、进展监测的不同方法。
l 访问日志。可以使用Kubernetes API或kubectl CLI访问日志,当一个Spark 应用程序正在运行,应用可能记录流日志:
$ kubectl-n=
如果安装在集群,同样也可以通过Kubernetes仪表盘访问日志。
l 访问Driver UI的界面。与应用程序关联的用户界面,可以在本地使用kubectl port-forward进行访问。
$ kubectl port-forward
l 调试。可能有几种故障:如果Kubernetes API服务器拒绝Spark-Submit提交,或一个不同的原因拒绝连接,提交逻辑应表明遇到的错误。然而,如果是正在运行的应用程序,最佳途径可能是通过KubernetesCLI。
得到一些在Driverpod调度决策的基本信息,可以运行:
$ kubectl describepod
如果Pod遇到运行时错误,状态可以进一步查证,可以使用:
$ kubectl logs
失败的Executor pods的状态和日志可以使用类似的方式检查。最后,删除Driverpod会清理整个Spark应用,包括所有的Executors,相关的服务等。Driverpod可以被认为是Spark应用在Kubernetes的表示。
(9) Kubernetes的特点。
l 命名空间。Kubernetes有命名空间的概念。命名空间是在多个用户之间(通过资源配额)划分集群资源的一种方式。Spark运行在Kubernetes,可以使用命名空间启动Spark的应用。这可以通过使用spark.kubernetes.namespace配置。Kubernetes允许使用ResourceQuota设置资源限制、对象的数量等对个体的命名空间。命名空间和ResourceQuota可以组合使用,管理员控制共享Spark应用在Kubernetes集群运行的资源分配。
l 基于角色的访问控制。Kubernetes集群基于角色的访问控制启用时,用户可以配置Kubernetes RBAC角色和服务帐户,由Spark运行在Kubernetes各种组件访问KubernetesAPI服务器。
Spark Driver pod采用Kubernetes服务帐户访问Kubernetes API服务器,创建和检查 Executor pods。Driver pod使用的服务帐户必须具有对 Driver操作的适当的权限。具体地说,至少服务帐户必须被授予Role或ClusterRole角色,运行Driverpods可以创建pods和服务。默认情况下,如果pod被创建没有服务指定帐户时,Driver pod自动分配默认的指定命名空间的服务帐户spark.kubernetes.namespace。
根据版本和Kubernetes部署设置,默认服务帐户可能有角色,在默认Kubernetes和基于角色的访问控制政策下,允许Driverpods 创建pods和服务。有时,用户可能需要指定一个自定义服务帐户有权授予角色。Spark运行在Kubernetes中,通过配置属性自定义服务帐户spark.kubernetes.authenticate.driver.serviceAccountName=
--confspark.kubernetes.authenticate.driver.serviceAccountName=spark
创建一个自定义的服务帐户,用户可以使用 kubectl create serviceaccount 命令。例如,下面的命令创建了一个名称为spark的服务帐户:
$ kubectl createserviceaccount spark
授予服务帐户Role或ClusterRole,一个RoleBinding或ClusterRoleBinding是必要的。创建一个RoleBinding 或ClusterRoleBinding,用户可以使用kubectl create rolebinding(或clusterrolebinding 为ClusterRoleBinding)命令。例如,下面的命令在默认命名空间创建了一个editClusterRole,授予到spark服务帐户:
$ kubectl createclusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark–
namespace=default
请注意,Role只能用于在一个单一的命名空间授予对资源的访问权限(如pods),而ClusterRole 可用于授予访问群集范围内的资源(如节点)以及所有的命名空间的命名空间资源(如pods)。Spark 运行在Kubernetes,因为Driver总是在相同的命名空间创建Executorpods,Role是足够的,虽然用户可以使用 ClusterRole。RBAC授权的更多信息以及如何配置Kubernetes 服务帐户,请参阅使用RBAC授权内容(https://kubernetes.io/docs/admin/authorization/rbac/)和pods配置服务帐户(https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account/)。
(10) 客户端模式。目前不支持客户端模式。
(11) 未来的工作。Spark运行在Kubernetes的功能,正在apache-spark-on-k8s/spark分支孵化(https://github.com/apache-spark-on-k8s/spark),最终将使它进入spark-kubernetes集成版本。
其中一些包括:
l PySpark
l R
l Dynamic Executor Scaling
l 本地文件的依赖关系管理
l Spark 的应用管理
l 工作队列和资源管理
可以参考的文档(https://apache-spark-on-k8s.github.io/userdocs/),可以尝试这些功能,并向开发团队提供反馈。
(12) 配置。
Spark的配置信息可以查看页面(http://spark.apache.org/docs/latest/configuration.html)。 Spark运行在Kubernetes的配置信息可以查看页面(http://spark.apache.org/docs/latest/running-on-kubernetes.html)。
Spark Properties
| Property Name | Default | Meaning |
|---|---|---|
spark.kubernetes.namespace |
default |
The namespace that will be used for running the driver and executor pods. |
spark.kubernetes.container.image |
(none) |
Container image to use for the Spark application. This is usually of the form example.com/repo/spark:v1.0.0. This configuration is required and must be provided by the user, unless explicit images are provided for each different container type. |
spark.kubernetes.driver.container.image |
(value of spark.kubernetes.container.image) |
Custom container image to use for the driver. |
spark.kubernetes.executor.container.image |
(value of spark.kubernetes.container.image) |
Custom container image to use for executors. |
spark.kubernetes.container.image.pullPolicy |
IfNotPresent |
Container image pull policy used when pulling images within Kubernetes. |
spark.kubernetes.allocation.batch.size |
5 |
Number of pods to launch at once in each round of executor pod allocation. |
spark.kubernetes.allocation.batch.delay |
1s |
Time to wait between each round of executor pod allocation. Specifying values less than 1 second may lead to excessive CPU usage on the spark driver. |
spark.kubernetes.authenticate.submission.caCertFile |
(none) | Path to the CA cert file for connecting to the Kubernetes API server over TLS when starting the driver. This file must be located on the submitting machine's disk. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). |
spark.kubernetes.authenticate.submission.clientKeyFile |
(none) | Path to the client key file for authenticating against the Kubernetes API server when starting the driver. This file must be located on the submitting machine's disk. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). |
spark.kubernetes.authenticate.submission.clientCertFile |
(none) | Path to the client cert file for authenticating against the Kubernetes API server when starting the driver. This file must be located on the submitting machine's disk. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). |
spark.kubernetes.authenticate.submission.oauthToken |
(none) | OAuth token to use when authenticating against the Kubernetes API server when starting the driver. Note that unlike the other authentication options, this is expected to be the exact string value of the token to use for the authentication. |
spark.kubernetes.authenticate.submission.oauthTokenFile |
(none) | Path to the OAuth token file containing the token to use when authenticating against the Kubernetes API server when starting the driver. This file must be located on the submitting machine's disk. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). |
spark.kubernetes.authenticate.driver.caCertFile |
(none) | Path to the CA cert file for connecting to the Kubernetes API server over TLS from the driver pod when requesting executors. This file must be located on the submitting machine's disk, and will be uploaded to the driver pod. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). |
spark.kubernetes.authenticate.driver.clientKeyFile |
(none) | Path to the client key file for authenticating against the Kubernetes API server from the driver pod when requesting executors. This file must be located on the submitting machine's disk, and will be uploaded to the driver pod. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). If this is specified, it is highly recommended to set up TLS for the driver submission server, as this value is sensitive information that would be passed to the driver pod in plaintext otherwise. |
spark.kubernetes.authenticate.driver.clientCertFile |
(none) | Path to the client cert file for authenticating against the Kubernetes API server from the driver pod when requesting executors. This file must be located on the submitting machine's disk, and will be uploaded to the driver pod. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). |
spark.kubernetes.authenticate.driver.oauthToken |
(none) | OAuth token to use when authenticating against the Kubernetes API server from the driver pod when requesting executors. Note that unlike the other authentication options, this must be the exact string value of the token to use for the authentication. This token value is uploaded to the driver pod. If this is specified, it is highly recommended to set up TLS for the driver submission server, as this value is sensitive information that would be passed to the driver pod in plaintext otherwise. |
spark.kubernetes.authenticate.driver.oauthTokenFile |
(none) | Path to the OAuth token file containing the token to use when authenticating against the Kubernetes API server from the driver pod when requesting executors. Note that unlike the other authentication options, this file must contain the exact string value of the token to use for the authentication. This token value is uploaded to the driver pod. If this is specified, it is highly recommended to set up TLS for the driver submission server, as this value is sensitive information that would be passed to the driver pod in plaintext otherwise. |
spark.kubernetes.authenticate.driver.mounted.caCertFile |
(none) | Path to the CA cert file for connecting to the Kubernetes API server over TLS from the driver pod when requesting executors. This path must be accessible from the driver pod. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). |
spark.kubernetes.authenticate.driver.mounted.clientKeyFile |
(none) | Path to the client key file for authenticating against the Kubernetes API server from the driver pod when requesting executors. This path must be accessible from the driver pod. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). |
spark.kubernetes.authenticate.driver.mounted.clientCertFile |
(none) | Path to the client cert file for authenticating against the Kubernetes API server from the driver pod when requesting executors. This path must be accessible from the driver pod. Specify this as a path as opposed to a URI (i.e. do not provide a scheme). |
spark.kubernetes.authenticate.driver.mounted.oauthTokenFile |
(none) | Path to the file containing the OAuth token to use when authenticating against the Kubernetes API server from the driver pod when requesting executors. This path must be accessible from the driver pod. Note that unlike the other authentication options, this file must contain the exact string value of the token to use for the authentication. |
spark.kubernetes.authenticate.driver.serviceAccountName |
default |
Service account that is used when running the driver pod. The driver pod uses this service account when requesting executor pods from the API server. Note that this cannot be specified alongside a CA cert file, client key file, client cert file, and/or OAuth token. |
spark.kubernetes.driver.label.[LabelName] |
(none) | Add the label specified by LabelName to the driver pod. For example, spark.kubernetes.driver.label.something=true. Note that Spark also adds its own labels to the driver pod for bookkeeping purposes. |
spark.kubernetes.driver.annotation.[AnnotationName] |
(none) | Add the annotation specified by AnnotationName to the driver pod. For example, spark.kubernetes.driver.annotation.something=true. |
spark.kubernetes.executor.label.[LabelName] |
(none) | Add the label specified by LabelName to the executor pods. For example, spark.kubernetes.executor.label.something=true. Note that Spark also adds its own labels to the driver pod for bookkeeping purposes. |
spark.kubernetes.executor.annotation.[AnnotationName] |
(none) | Add the annotation specified by AnnotationName to the executor pods. For example, spark.kubernetes.executor.annotation.something=true. |
spark.kubernetes.driver.pod.name |
(none) | Name of the driver pod. If not set, the driver pod name is set to "spark.app.name" suffixed by the current timestamp to avoid name conflicts. |
spark.kubernetes.executor.lostCheck.maxAttempts |
10 |
Number of times that the driver will try to ascertain the loss reason for a specific executor. The loss reason is used to ascertain whether the executor failure is due to a framework or an application error which in turn decides whether the executor is removed and replaced, or placed into a failed state for debugging. |
spark.kubernetes.submission.waitAppCompletion |
true |
In cluster mode, whether to wait for the application to finish before exiting the launcher process. When changed to false, the launcher has a "fire-and-forget" behavior when launching the Spark job. |
spark.kubernetes.report.interval |
1s |
Interval between reports of the current Spark job status in cluster mode. |
spark.kubernetes.driver.limit.cores |
(none) | Specify the hard CPU [limit](https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/#resource-requests-and-limits-of-pod-and-container) for the driver pod. |
spark.kubernetes.executor.limit.cores |
(none) | Specify the hard CPU [limit](https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/#resource-requests-and-limits-of-pod-and-container) for each executor pod launched for the Spark Application. |
spark.kubernetes.node.selector.[labelKey] |
(none) | Adds to the node selector of the driver pod and executor pods, with key labelKey and the value as the configuration's value. For example, setting spark.kubernetes.node.selector.identifier to myIdentifier will result in the driver pod and executors having a node selector with key identifier and valuemyIdentifier. Multiple node selector keys can be added by setting multiple configurations with this prefix. |
spark.kubernetes.driverEnv.[EnvironmentVariableName] |
(none) | Add the environment variable specified by EnvironmentVariableName to the Driver process. The user can specify multiple of these to set multiple environment variables. |
spark.kubernetes.mountDependencies.jarsDownloadDir |
/var/spark-data/spark-jars |
Location to download jars to in the driver and executors. This directory must be empty and will be mounted as an empty directory volume on the driver and executor pods. |
spark.kubernetes.mountDependencies.filesDownloadDir |
/var/spark-data/spark-files |
Location to download jars to in the driver and executors. This directory must be empty and will be mounted as an empty directory volume on the driver and executor pods. |
spark.kubernetes.mountDependencies.timeout |
300s | Timeout in seconds before aborting the attempt to download and unpack dependencies from remote locations into the driver and executor pods. |
spark.kubernetes.mountDependencies.maxSimultaneousDownloads |
5 | Maximum number of remote dependencies to download simultaneously in a driver or executor pod. |
spark.kubernetes.initContainer.image |
(value of spark.kubernetes.container.image) |
Custom container image for the init container of both driver and executors. |
spark.kubernetes.driver.secrets.[SecretName] |
(none) | Add the Kubernetes Secret named SecretName to the driver pod on the path specified in the value. For example,spark.kubernetes.driver.secrets.spark-secret=/etc/secrets. Note that if an init-container is used, the secret will also be added to the init-container in the driver pod. |
spark.kubernetes.executor.secrets.[SecretName] |
(none) | Add the Kubernetes Secret named SecretName to the executor pod on the path specified in the value. For example, spark.kubernetes.executor.secrets.spark-secret=/etc/secrets. Note that if an init-container is used, the secret will also be added to the init-container in the executor pod. |
2018年新春报喜!热烈祝贺王家林大咖大数据经典传奇著作《SPARK大数据商业实战三部曲》畅销书籍 清华大学出版社发行上市!
本书基于Spark 2.2.0最新版本(2017年7月11日发布),以Spark商业案例实战和Spark在生产环境下几乎所有类型的性能调优为核心,以Spark内核解密为基石,分为上篇、中篇、下篇,对企业生产环境下的Spark商业案例与性能调优抽丝剥茧地进行剖析。上篇基于Spark源码,从一个动手实战案例入手,循序渐进地全面解析了Spark 2.2新特性及Spark内核源码;中篇选取Spark开发中最具有代表的经典学习案例,深入浅出地介绍,在案例中综合应用Spark的大数据技术;下篇性能调优内容基本完全覆盖了Spark在生产环境下的所有调优技术。
本书适合所有Spark学习者和从业人员使用。对于有分布式计算框架应用经验的人员,本书也可以作为Spark高手修炼的参考书籍。同时,本书也特别适合作为高等院校的大数据教材使用。
清华大学出版社官方旗舰店(天猫)、京东、当当网、亚马逊等网店已可购买!欢迎大家购买学习!( Spark 内核部分透彻讲解Spark 2.2.0的源代码;Spark 案例部分详细讲解案例代码,新书案例部分每章都专门有1节列出案例全部的代码。新书重印时,将在新书封底加上二维码,也可以在清华大学出版社官网上进行下载。 )
清华大学出版社官方旗舰店(天猫)、京东、当当网、亚马逊等网店已可购买!欢迎大家购买学习!
清华大学出版社官方旗舰店(天猫) 点击打开链接
京东网购地址:点击打开链接
当当网址:点击打开链接