微信小程序:nodejs+百度语音识别开发实践
今天,终于成功使用nodejs研究出百度语音识别了。目前使用小程序最新录音管理api测试,小程序录音只支持aac,mp3格式,并且保持的是临时地址。而百度语音识别目前只支持pcm,wav,amr格式。因此服务端需要先存储好录音文件并经过一次音频转换。具体步骤如下:
1、安装ffmpeg插件。我使用的windows系统,具体安装方法看这里,该博主文章讲的非常详细,按照步骤走即可。这个插件是使用fluent-ffmpeg依赖的前提条件
2、使用express生成器生成项目开发接口。需要提前安装好几个个依赖:
npm install fluent-ffmpeg –save-dev//mp3转wav依赖
npm install multiparty –save-dev//获取multipart/form-data上传文件依赖
npm install baidu-aip-sdk –save-dev//百度AI依赖
上文提及的申请应用生成的appid和appkey和secretkey仍然需要,具体代码如下:
routes文件夹下创建AiSpeechRecognition.js::
var express=require('express');
var router=express.Router();
var fs=require('fs');
var Multiparty =require('multiparty');
var ffmpeg=require('fluent-ffmpeg');//创建一个ffmpeg命令
var AipSpeechServer=require('baidu-aip-sdk').speech;
//设置appid/appkey/appsecret
var APP_ID = "申请的应用appid";
var API_KEY = "申请的应用appkey";
var SECRET_KEY = "申请的应用secretkey";
// 新建一个对象,建议只保存一个对象调用服务接口
var client =new AipSpeechServer(APP_ID, API_KEY, SECRET_KEY);
router.post('/recognition', function(req, res, next){
//生成multiparty对象,并配置上传目标路径
var form =new Multiparty.Form({ uploadDir: './public/audio'});
//上传完成后处理
form.parse(req, function(err, fields, files){
var filesTemp=JSON.stringify(files, null, 2);
if(err){
//console.log('parse error: '+err);
res.json({
ret: -1,
data:{},
msg: '未知错误'
});
}else{
//console.log('parse files: '+filesTemp);
var inputFile=files.file[0];
var uploadedPath=inputFile.path;
var command=ffmpeg();
command.addInput(uploadedPath)
//.saveToFile('./public/audio/222.wav')//保存编码文件到文件夹 --保存成wav是可以的,但是pcm报错
.saveToFile('./public/audio/16k.wav')
.on('error', function(err){
console.log(err)
})
.on('end', function(){
//调用百度语音合成接口
var voice = fs.readFileSync('./public/audio/16k.wav');
var voiceBuffer=new Buffer(voice);
client.recognize(voiceBuffer, 'wav', 16000).then(function(result){
//console.log(result);
var data=[];
if(result.err_no===0){
data=result.result;
}
res.json({
ret: result.err_no,
data: {
data: data
},
msg: result.err_msg
});
}, function(err){
console.log(err);
});
//语音识别 end
//删除上传的临时音频文件
fs.unlink(uploadedPath, function(err){
if(err){
console.log(uploadedPath+'文件删除失败');
console.log(err);
}else{
console.log(uploadedPath+'文件删除成功');
}
});
//删除mp3转成wav格式的音频
fs.unlink('./public/audio/16k.wav', function(err){
if(err){
console.log('16k.wav文件删除失败');
console.log(err);
}else{
console.log('16k.wav文件删除成功');
}
});
});
}
});
});
module.exports=router;项目根目录app.js配置好访问接口:
var recognition=require('./routes/AiSpeechRecognition.js');
app.use('/baiduAI2', recognition);目前做的测试接口用,很多逻辑没有代码片都没有整合,直接写在一个接口上,如果是要拿到实际生产线,请自行封装下。然后执行npm start运行后端项目。
前端代码:
BDSpeechRecognition.js::
const recorderManager = wx.getRecorderManager();
Page({
data: {
result: '',//语音识别结果
recording: false//是否正在录音
},
//开始录制语音
startRecord(e){
this.setData({recording: true});
recorderManager.start({
duration: 60000,//百度最多支持60s语音
sampleRate: 16000,
//encodeBitRate: 48000,
numberOfChannels: 1,//必须指定录音通道数
format: 'mp3'
});
recorderManager.onStart(() => {
//console.log('recorder start')
});
},
//停止录音
stopRecord(e) {
let that=this;
this.setData({ recording: false });
recorderManager.stop();//停止录音
recorderManager.onStop((res)=>{
const { tempFilePath } = res;
//uploadfile start
wx.uploadFile({
url: 'http://你的ip:3000/baiduAI2/recognition',
filePath: tempFilePath,
name: 'file',
success(res){
//console.log(res);
let data=typeof res.data==='string'? JSON.parse(res.data) : res.data;
if(data.ret==0){
//console.log(data.data.data[0])
that.setData({
result: data.data.data[0]
});
}else{
that.setData({
result: '我不知道你在说什么'
});
}
},
fail(err){
console.log(err);
}
});
})
}
})BDSpeechRecognition.wxml::
<view class="title">语音识别view>
<view class="test" bindtap="startRecord" wx:if="{{!recording}}">开始录音view>
<view class="test" bindtap="stopRecord" wx:if="{{recording}}">停止录音view>
<view class="result" wx:if="{{result}}">
<view class="title">语音识别结果:view>
{{result}}
view>BDSpeechRecognition.wxss::
page{
background-color: #eee;
}
.title{
width: 100%;
height: 120rpx;
line-height: 120rpx;
font-size: 48rpx;
color: #333;
text-indent: 20rpx;
}
.test{
width: 100%;
height: 90rpx;
line-height: 90rpx;
font-size: 32rpx;
color: #00f;
border: solid 1px #999;
border-left: 0;
border-right: 0;
background-color: #fff;
text-indent: 20rpx;
}最后执行调试测试,演示结果如下:
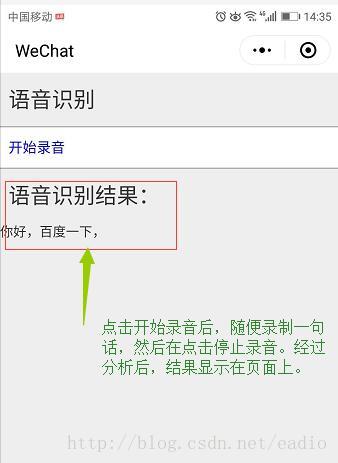
最后,我把后端测试代码整合到了码云上了。
目前发现使用ffmpeg命令将mp3音频转换为pcm文件是成功的,但是我用fflunt-ffmpeg转换失败,所以只能采用转为wav音频由百度内部自行在转换一次。会比较耗时,还没有解决方案。