python爬取微信小程序数据,python爬取小程序数据
大家好,小编来为大家解答以下问题,python爬取微信小程序数据,python爬取小程序数据,现在让我们一起来看看吧!
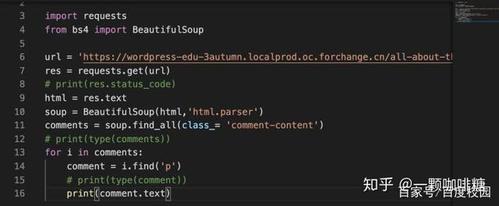
Python爬虫系列之微信小程序实战
基于Scrapy爬虫框架实现对微信小程序数据的爬取
首先,你得需要安装抓包工具,这里推荐使用Charles,至于怎么使用后期有时间我会出一个事例
- 最重要的步骤之一就是分析接口,理清楚每一个接口功能,然后连接起来形成接口串思路,再通过Spider的回调函数一次次去分析数据
- 抓包分析接口过程不做演示了,主要是分析请求头和query参数
- 以下为代码部分,代码未写详细注释,但是流程写的还是挺清晰的
- 如需测试请自行抓包更换请求头的token与session,以下测试头已做修改,不能直接使用
代码仅供学习交流,请勿用于非法用途
小程序爬虫接单、app爬虫接单、网页爬虫接单、接口定制、网站开发、小程序开发 > 点击这里联系我们 <
微信请扫描下方二维码

# -*- coding:utf-8 -*-
import scrapy
'''
@Author :王磊
@Date :2018/12/3
@Deion:美家优享微信小程序全国商品数据爬取
'''
class MeiJiaSpider(scrapy.spiders.Spider):
name = "MeiJiaSpider"
def __init__(self):
self.headers = {
"x-bell-token": "ef4d705aabf4909db847b6de6068605c-4",
"x-session-key": "ab7f2b8673429d5e779c7f5c8b4a8524",
"User-Agent": "Mozilla/5.0 (Linux; Android 8.0.0; MI 5 Build/OPR1.170623.032; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/68.0.3440.91 Mobile Safari/537.36 MicroMessenger/6.7.3.1360(0x26070333) NetType/WIFI Language/zh_CN Process/appbrand0"
}
def start_requests(self):
'''
获取城市列表
:return:
'''
url = 'https://bell-mall.yunshanmeicai.com/mall/gis/get-city-list'
yield scrapy.FormRequest(
url=url,
headers=self.headers,
dont_filter=True,
callback=self.getCityChild
)
def getCityChild(self, response):
'''
通过城市列表获取城市子列表,获取子列表经纬度数据
:param response:
:return:
'''
datas = eval(response.text)
if datas['ret']:
url = 'https://bell-mall.yunshanmeicai.com/mall/gis/address-search'
for _ in datas['data']:
name = _['name']
data = {
"key_words": name,
"city": name
}
yield scrapy.FormRequest(
url=url,
headers=self.headers,
formdata=data,
dont_filter=True,
callback=self.sellerParse
)
def sellerParse(self, response):
'''
通过经纬度获取该位置附近商家列表
:param response:
:return:
'''
res = eval(response.text)
if res['ret']:
datas = res['data']
for _ in datas:
locationData = {"lat": str(_['location']['lat']), "lng": str(_['location']['lng'])}
urlNearby = 'https://bell-mall.yunshanmeicai.com/mall/gis/get-nearby-team'
yield scrapy.FormRequest(
url=urlNearby,
headers=self.headers,
formdata=locationData,
dont_filter=True,
callback=self.sellerInfoParse
)
def sellerInfoParse(self, response):
'''
获取商家详细信息,包含店铺id,手机号,地区等等(若不需要店铺id以外的其他数据,此过程可省略,因为店铺id在商家列表中以id的形式展示了)
:param response:
:return:
'''
res = eval(response.text)
if res['ret']:
datas = res['data']
urlClass = 'https://bell-mall.yunshanmeicai.com/cart/cart/get-list'
for _ in datas:
query = {}
headers = {
"x-bell-token": "0b5e5bcf70c973b080f39cb7b4ec2306-4",
"x-session-key": "3e76463e81d9551826fc132b10c27794",
"x-group-token": _['id'],
"User-Agent": "Mozilla/5.0 (Linux; Android 8.0.0; MI 5 Build/OPR1.170623.032; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/68.0.3440.91 Mobile Safari/537.36 MicroMessenger/6.7.3.1360(0x26070333) NetType/WIFI Language/zh_CN Process/appbrand0"
}
yield scrapy.FormRequest(
url=urlClass,
headers=headers,
formdata=query,
dont_filter=True,
callback=self.storeClassParse
)
def storeClassParse(self, response):
'''
通过店铺id获取店铺类目
:param response:
:return:
'''
res = eval(response.text)
if res['ret']:
urlClass = 'https://bell-mall.yunshanmeicai.com/mall/home/get-home-class'
version = {"version": "1.0.0"}
headers = {
"x-bell-token": "0b5e5bcf70c973b080f39cb7b4ec2306-4",
"x-session-key": "3e76463e81d9551826fc132b10c27794",
"x-group-token": str(res['data']['store_id']),
"User-Agent": "Mozilla/5.0 (Linux; Android 8.0.0; MI 5 Build/OPR1.170623.032; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/68.0.3440.91 Mobile Safari/537.36 MicroMessenger/6.7.3.1360(0x26070333) NetType/WIFI Language/zh_CN Process/appbrand0"
}
yield scrapy.FormRequest(
url=urlClass,
headers=headers,
formdata=version,
dont_filter=True,
callback=self.goodsListParse,
meta={"store_id": str(res['data']['store_id'])}
)
def goodsListParse(self, response):
'''
通过店铺类目id获取商品列表
:param response:
:return:
'''
res = eval(str(response.text).replace('null', 'None'))
if res['ret']:
if res['data']['list']:
data = res['data']['list']
goodsUrl = 'https://bell-mall.yunshanmeicai.com/mall/home/index'
headers = {
"x-bell-token": "0b5e5bcf70c973b080f39cb7b4ec2306-4",
"x-session-key": "3e76463e81d9551826fc132b10c27794",
"x-group-token": str(response.meta['store_id']),
"User-Agent": "Mozilla/5.0 (Linux; Android 8.0.0; MI 5 Build/OPR1.170623.032; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/68.0.3440.91 Mobile Safari/537.36 MicroMessenger/6.7.3.1360(0x26070333) NetType/WIFI Language/zh_CN Process/appbrand0"
}
for _ in data:
query = {"page": "1", "class_id": str(_['id']), "version": "1.0.2"}
yield scrapy.FormRequest(
url=goodsUrl,
headers=headers,
formdata=query,
dont_filter=True,
callback=self.goodsParse
)
def goodsParse(self, response):
'''
解析最终商品数据
:param response:
:return:
'''
goodsList = eval(response.text)
if goodsList['ret']:
if goodsList['data']['list']:
lists = goodsList['data']['list']
for _ in lists:
start_time = str(_['start_time'])
end_time = str(_['end_time'])
product_id = str(_['product_id'])
product_name = _['product_name']
group_product_name = _['group_product_name']
group_id = str(_['group_id'])
group_type = str(_['group_type'])
product_short_desc = _['product_short_desc']
product_desc = _['product_desc']
product_format_id = str(_['product_format_id'])
already_txt = _['already_txt']
already_nums = str(_['already_nums'])
left_txt = _['left_txt']
left_num = str(_['left_num'])
real_left_num = str(_['real_left_num'])
group_price = str(_['group_price'])
line_price = str(_['line_price'])
product_sales_num = str(_['product_sales_num'])
identify = _['identify']
print(
"start_time: %s ,end_time: %s ,product_id: %s ,product_name: %s ,group_product_name: %s ,group_id: %s ,group_type: %s ,product_short_desc: %s ,product_format_id: %s ,already_txt: %s ,already_nums: %s ,real_left_num: %s ,group_price: %s ,line_price: %s ,product_sales_num: %s ,identify: %s " % (
start_time, end_time, product_id, product_name, group_product_name, group_id, group_type,
product_short_desc, product_format_id, already_txt, already_nums, real_left_num, group_price,
line_price, product_sales_num, identify)
)
'''
"text_label_list": [
{
"label_content": "#fe3113",
"label_name": "热销",
"label_id": 10
}
],
"pic_label_list": [
{
"label_content": "https:\\/\\/img-oss.yunshanmeicai.com\\/xfresh\\/product\\/69cf3401b000504ea33d9e8b80bfc467.png",
"label_name": "美家福利",
"label_id": 52
}
],
"loop_pics": [
"https:\\/\\/img-oss.yunshanmeicai.com\\/xfresh\\/product\\/03df45319b36070f67edf4562d6ec74f.jpg"
],
"new_loop_pics": "https:\\/\\/img-oss.yunshanmeicai.com\\/xfresh\\/product\\/03df45319b36070f67edf4562d6ec74f.jpg?x-oss-process=image\\/resize,w_360",
'''
☞点击这里与我探讨☚
♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪
♪♪后续会更新系列基于Python的爬虫小例子,欢迎关注。♪♪
♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪♪