Nginx限速模块初探
云栖君导读:Nginx限速模块分为哪几种?按请求速率限速的burst和nodelay参数是什么意思?漏桶算法和令牌桶算法究竟有什么不同?本文将带你一探究竟。我们会通过一些简单的示例展示Nginx限速模块是如何工作的,然后结合代码讲解其背后的算法和原理。
核心算法
在探究Nginx限速模块之前,我们先来看看网络传输中常用两个的流量控制算法:漏桶算法和令牌桶算法。这两只“桶”到底有什么异同呢?
漏桶算法(leaky bucket)
漏桶算法(leaky bucket)算法思想如图所示:
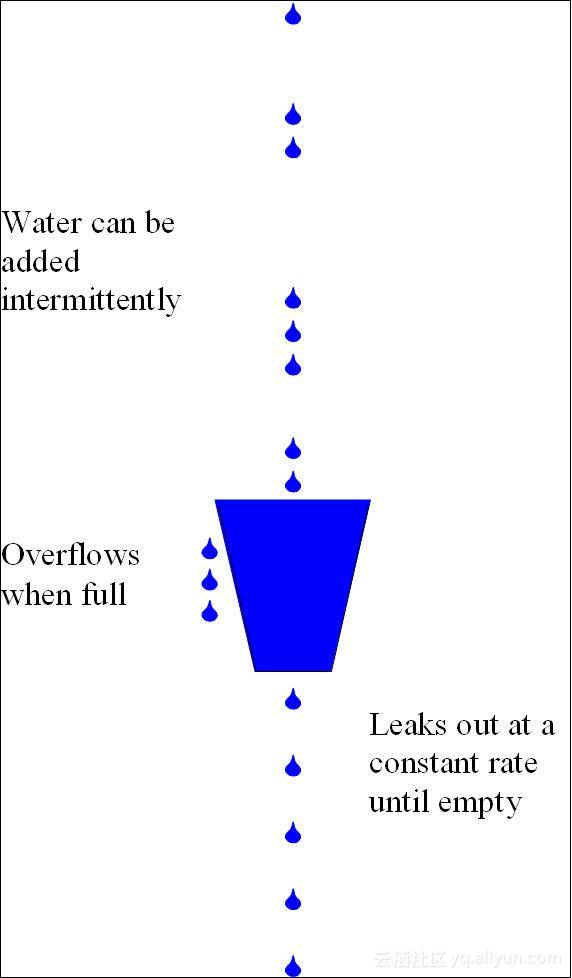
一个形象的解释是:
水(请求)从上方倒入水桶,从水桶下方流出(被处理);
来不及流出的水存在水桶中(缓冲),以固定速率流出;
水桶满后水溢出(丢弃)。
这个算法的核心是:缓存请求、匀速处理、多余的请求直接丢弃。
令牌桶算法(token bucket)
令牌桶(token bucket)算法思想如图所示:
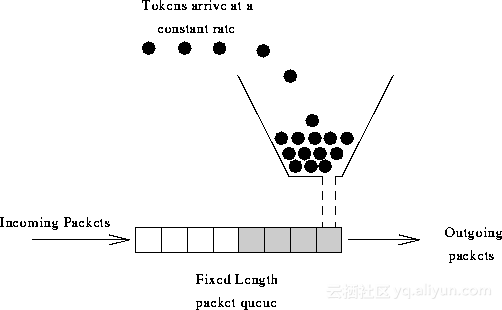
算法思想是:
令牌以固定速率产生,并缓存到令牌桶中;
令牌桶放满时,多余的令牌被丢弃;
请求要消耗等比例的令牌才能被处理;
令牌不够时,请求被缓存。
相比漏桶算法,令牌桶算法不同之处在于它不但有一只“桶”,还有个队列,这个桶是用来存放令牌的,队列才是用来存放请求的。
从作用上来说,漏桶和令牌桶算法最明显的区别就是是否允许突发流量(burst)的处理,漏桶算法能够强行限制数据的实时传输(处理)速率,对突发流量不做额外处理;而令牌桶算法能够在限制数据的平均传输速率的同时允许某种程度的突发传输。
Nginx按请求速率限速模块使用的是漏桶算法,即能够强行保证请求的实时处理速度不会超过设置的阈值。
Nginx限速模块
Nginx主要有两种限速方式:按连接数限速(ngx_http_limit_conn_module)、按请求速率限速(ngx_http_limit_req_module)。我们着重讲解按请求速率限速。
按连接数限速
按连接数限速是指限制单个IP(或者其他的key)同时发起的连接数,超出这个限制后,Nginx将直接拒绝更多的连接。这个模块的配置比较好理解,详见ngx_http_limit_conn_module官方文档。
按请求速率限速
按请求速率限速是指限制单个IP(或者其他的key)发送请求的速率,超出指定速率后,Nginx将直接拒绝更多的请求。采用leaky bucket算法实现。为深入了解这个模块,我们先从实验现象说起。开始之前我们先简单介绍一下该模块的配置方式,以下面的配置为例:
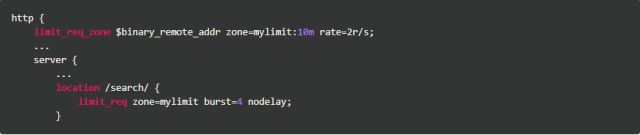
使用limit_req_zone关键字,我们定义了一个名为mylimit大小为10MB的共享内存区域(zone),用来存放限速相关的统计信息,限速的key值为二进制的IP地址($binary_remote_addr),限速上限(rate)为2r/s;接着我们使用limit_req关键字将上述规则作用到/search/上。burst和nodelay的作用稍后解释。
使用上述规则,对于/search/目录的访问,单个IP的访问速度被限制在了2请求/秒,超过这个限制的访问将直接被Nginx拒绝。
实验1——毫秒级统计
我们有如下配置:
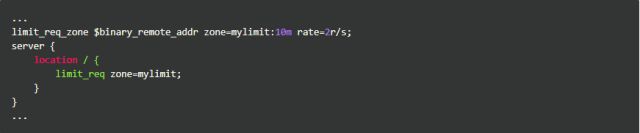
上述规则限制了每个IP访问的速度为2r/s,并将该规则作用于跟目录。如果单个IP在非常短的时间内并发发送多个请求,结果会怎样呢?
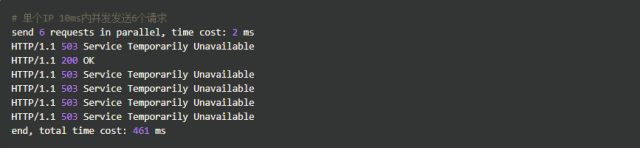
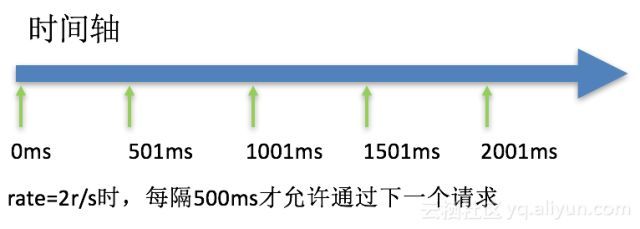
我们使用单个IP在10ms内发并发送了6个请求,只有1个成功,剩下的5个都被拒绝。我们设置的速度是2r/s,为什么只有1个成功呢,是不是Nginx限制错了?当然不是,是因为Nginx的限流统计是基于毫秒的,我们设置的速度是2r/s,转换一下就是500ms内单个IP只允许通过1个请求,从501ms开始才允许通过第二个请求。
实验2——burst允许缓存处理突发请求
实验1我们看到,我们短时间内发送了大量请求,Nginx按照毫秒级精度统计,超出限制的请求直接拒绝。这在实际场景中未免过于苛刻,真实网络环境中请求到来不是匀速的,很可能有请求“突发”的情况,也就是“一股子一股子”的。
Nginx考虑到了这种情况,可以通过burst关键字开启对突发请求的缓存处理,而不是直接拒绝。
来看我们的配置:
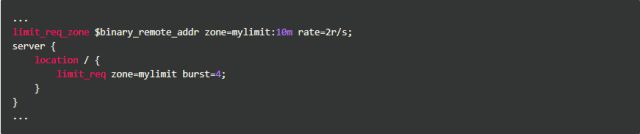
我们加入了burst=4,意思是每个key(此处是每个IP)最多允许4个突发请求的到来。如果单个IP在10ms内发送6个请求,结果会怎样呢?
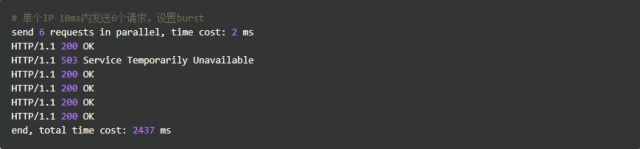
相比实验1成功数增加了4个,这个我们设置的burst数目是一致的。具体处理流程是:1个请求被立即处理,4个请求被放到burst队列里,另外一个请求被拒绝。通过burst参数,我们使得Nginx限流具备了缓存处理突发流量的能力。
但是请注意:burst的作用是让多余的请求可以先放到队列里,慢慢处理。如果不加nodelay参数,队列里的请求不会立即处理,而是按照rate设置的速度,以毫秒级精确的速度慢慢处理。
实验3——nodelay降低排队时间
实验2中我们看到,通过设置burst参数,我们可以允许Nginx缓存处理一定程度的突发,多余的请求可以先放到队列里,慢慢处理,这起到了平滑流量的作用。但是如果队列设置的比较大,请求排队的时间就会比较长,用户角度看来就是RT变长了,这对用户很不友好。有什么解决办法呢?nodelay参数允许请求在排队的时候就立即被处理,也就是说只要请求能够进入burst队列,就会立即被后台worker处理,请注意,这意味着burst设置了nodelay时,系统瞬间的QPS可能会超过rate设置的阈值。nodelay参数要跟burst一起使用才有作用。
延续实验2的配置,我们加入nodelay选项:

单个IP 10ms内并发发送6个请求,结果如下:
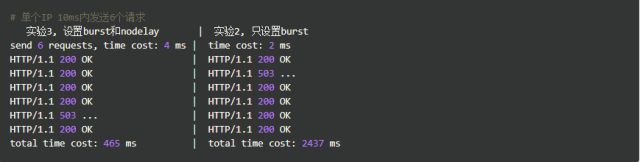
跟实验2相比,请求成功率没变化,但是总体耗时变短了。这怎么解释呢?实验2中,有4个请求被放到burst队列当中,工作进程每隔500ms(rate=2r/s)取一个请求进行处理,最后一个请求要排队2s才会被处理;实验3中,请求放入队列跟实验2是一样的,但不同的是,队列中的请求同时具有了被处理的资格,所以实验3中的5个请求可以说是同时开始被处理的,花费时间自然变短了。
但是请注意,虽然设置burst和nodelay能够降低突发请求的处理时间,但是长期来看并不会提高吞吐量的上限,长期吞吐量的上限是由rate决定的,因为nodelay只能保证burst的请求被立即处理,但Nginx会限制队列元素释放的速度,就像是限制了令牌桶中令牌产生的速度。
看到这里你可能会问,加入了nodelay参数之后的限速算法,到底算是哪一个“桶”,是漏桶算法还是令牌桶算法?当然还算是漏桶算法。考虑一种情况,令牌桶算法的token为耗尽时会怎么做呢?由于它有一个请求队列,所以会把接下来的请求缓存下来,缓存多少受限于队列大小。但此时缓存这些请求还有意义吗?如果server已经过载,缓存队列越来越长,RT越来越高,即使过了很久请求被处理了,对用户来说也没什么价值了。所以当token不够用时,最明智的做法就是直接拒绝用户的请求,这就成了漏桶算法,哈哈~
源码剖析
经过上面的示例,我们队请求限速模块有了一定的认识,现在我们深入剖析代码实现。按请求速率限流模块ngx_http_limit_req_module代码位于[src/http/modules/ngx_http_limit_req_module.c
],900多好代码可谓短小精悍。相关代码有两个核心数据结构:
红黑树:通过红黑树记录每个节点(按照声明时指定的key)的统计信息,方便查找;
LRU队列:将红黑树上的节点按照最近访问时间排序,时间近的放在队列头部,以便使用LRU队列淘汰旧的节点,避免内存溢出。
这两个关键对象存储在ngx_http_limit_req_shctx_t中:

其中除了rbtree和queue之外,还有一个叫做sentinel的变量,这个变量用作红黑树的NIL节点。
该模块的核心逻辑在函数ngx_http_limit_req_lookup()中,这个函数主要流程是怎样呢?对于每一个请求:
从根节点开始查找红黑树,找到key对应的节点;
找到后修改该点在LRU队列中的位置,表示该点最近被访问过;
执行漏桶算法;
没找到时根据LRU淘汰,腾出空间;
生成并插入新的红黑树节点;
执行下一条限流规则。
流程很清晰,但是代码中牵涉到红黑树、LRU队列等高级数据结构,是不是会写得很复杂?好在Nginx作者功力深厚,代码写得简洁易懂,哈哈~
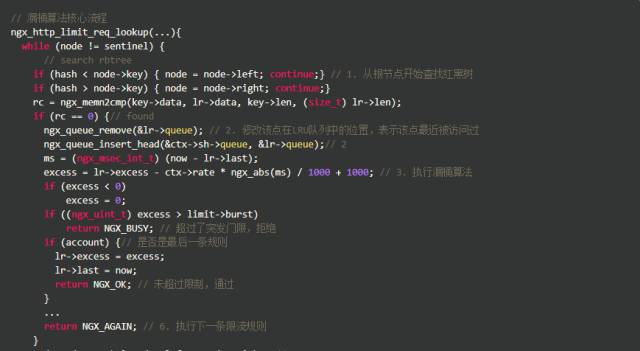

代码有三种返回值,它们的意思是:
NGX_BUSY 超过了突发门限,拒绝
NGX_OK 未超过限制,通过
NGX_AGAIN 未超过限制,但是还有规则未执行,需执行下一条限流规则
上述代码不难理解,但我们还有几个问题:
LRU是如何实现的?
漏桶算法是如何实现的?
每个key相关的burst队列在哪里?
LRU是如何实现的
LRU算法的实现很简单,如果一个节点被访问了,那么就把它移到队列的头部,当空间不足需要淘汰节点时,就选出队列尾部的节点淘汰掉,主要体现在如下代码中:

漏桶算法是如何实现的
漏桶算法的实现也比我们想象的简单,其核心是这一行公式excess = lr->excess - ctx->rate * ngx_abs(ms) / 1000 + 1000,这样代码的意思是:excess表示当前key上遗留的请求数,本次遗留的请求数 = 上次遗留的请求数 - 预设速率 X 过去的时间 + 1。这个1表示当前这个请求,由于Nginx内部表示将单位缩小了1000倍,所以1个请求要转换成1000。
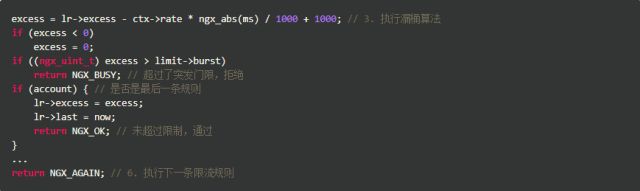
上述代码受限算出当前key上遗留的请求数,如果超过了burst,就直接拒绝;由于Nginx允许多条限速规则同时起作用,如果已是最后一条规则,则允许通过,否则执行下一条规则。
单个key相关的burst队列在哪里
没有单个key相关的burst队列。上面代码中我们看到当到达最后一条规则时,只要excess
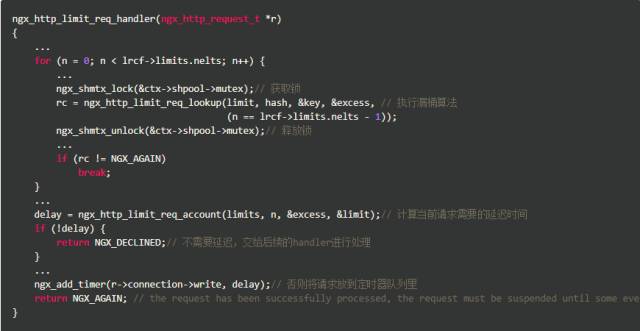
我们看到ngx_http_limit_req_handler()调用了函数ngx_http_limit_req_lookup(),并根据其返回值决定如何操作:或是拒绝,或是交给下一个handler处理,或是将请求放入定期器队列。当限速规则都通过后,该hanlder通过调用函数ngx_http_limit_req_account()得出当前请求需要的延迟时间,如果不需要延迟,就将请求交给后续的handler进行处理,否则将请求放到定时器队列里。注意这个定时器队列是共享的,并没有为单独的key(比如,每个IP地址)设置队列。关于handler模块背景知识的介绍,可参考Tengine团队撰写的Nginx开发从入门到精通。
关于按请求速率限速的原理讲解,可参考Rate Limiting with NGINX and NGINX Plus,关于源码更详细的解析可参考ngx_http_limit_req_module 源码分析以及y123456yz的Nginx源码分析的git项目。
结尾
本文主要讲解了Nginx按请求速率限速模块的用法和原理,其中burst和nodelay参数是容易引起误解的,虽然可通过burst允许缓存处理突发请求,结合nodelay能够降低突发请求的处理时间,但是长期来看他们并不会提高吞吐量的上限,长期吞吐量的上限是由rate决定的。需要特别注意的是,burst设置了nodelay时,系统瞬间的QPS可能会超过rate设置的阈值。
本文只是对Nginx管中窥豹,更多关于Nginx介绍的文章,可参考Tengine团队撰写的Nginx开发从入门到精通。
往期精彩文章
0. 如何基于MySQL做实时计算?
1. 阿里巴巴云化架构创新之路
2. AI在双11中的个性化搜索和决策实践
3.《2017中国开发者调查报告》重磅发布!代码谱写传奇,深度揭秘中国开发者现状!
4. 2017深度学习NLP进展与趋势
-END-![]()
云栖社区
ID:yunqiinsight
云计算丨互联网架构丨大数据丨机器学习丨运维
