Hadoop伪分布式部署之历史服务与日志聚集
前言
在做完 Hadoop伪分布式部署之hdfs和Hadoop伪分布式部署之yarn和mapreduce之后,我们来做一下历史服务和日志聚集的部署。
相关环境如下:
操作系统:CentOS6.4
Java版本:Oracle jdk1.7
Hadoop版本:Hadoop2.5.0
主机hostname:hadoop01.datacenter.com
hadoop目录:/opt/modules/hadoop-2.5.0
1、历史服务配置
启动hdfs和yarn服务
[hadoop@hadoop01 ~]$ cd /opt/modules/hadoop-2.5.0/
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/modules/hadoop-2.5.0/logs/hadoop-hadoop-namenode-hadoop01.datacenter.com.out
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/modules/hadoop-2.5.0/logs/hadoop-hadoop-datanode-hadoop01.datacenter.com.out
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/modules/hadoop-2.5.0/logs/yarn-hadoop-resourcemanager-hadoop01.datacenter.com.out
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/modules/hadoop-2.5.0/logs/yarn-hadoop-nodemanager-hadoop01.datacenter.com.out
[hadoop@hadoop01 hadoop-2.5.0]$ jps
3543 Jps
2971 NameNode
3160 ResourceManager
3411 NodeManager
3031 DataNode
[hadoop@hadoop01 hadoop-2.5.0]$ 执行mapreduce程序
[hadoop@hadoop01 hadoop-2.5.0]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount mapreduce/wordcount/input mapreduce/wordcount/output2
...
[hadoop@hadoop01 hadoop-2.5.0]$ 通过yarn的webapp服务查看一下作业情况,网址为http://hadoop01.datacenter.com:8088,结果如下图所示:
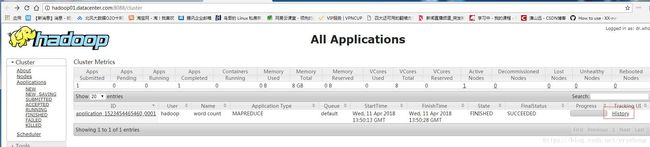
点击右下角的History,出现如下界面:
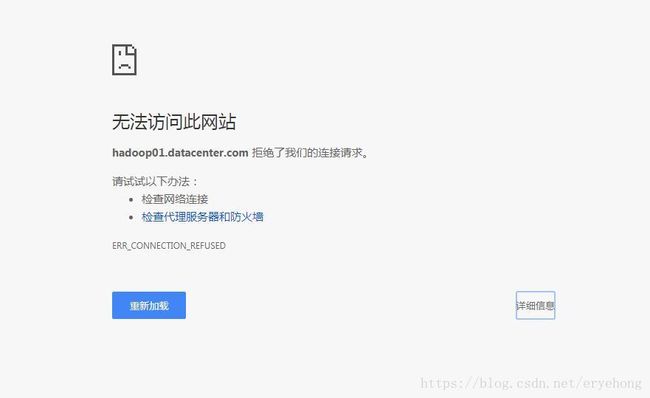
这是因为我们没有配置历史服务,接下来我们进行历史服务的配置
[hadoop@hadoop01 hadoop-2.5.0]$ vim etc/hadoop/mapred-site.xml
...
mapreduce.jobhistory.address
hadoop01.datacenter.com:10020
mapreduce.jobhistory.webapp.address
hadoop01.datacenter.com:19888
...
[hadoop@hadoop01 hadoop-2.5.0]$ 启动历史服务
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/modules/hadoop-2.5.0/logs/mapred-hadoop-historyserver-hadoop01.datacenter.com.out
[hadoop@hadoop01 hadoop-2.5.0]$ jps
4232 JobHistoryServer
3422 NodeManager
3041 DataNode
4274 Jps
3170 ResourceManager
2979 NameNode
[hadoop@hadoop01 hadoop-2.5.0]$ 然后重新点击yarn的web界面的“History”标签,弹出下面的窗口,我们可以看到这个wordcount程序一共使用了一个map和一个reduce计算。
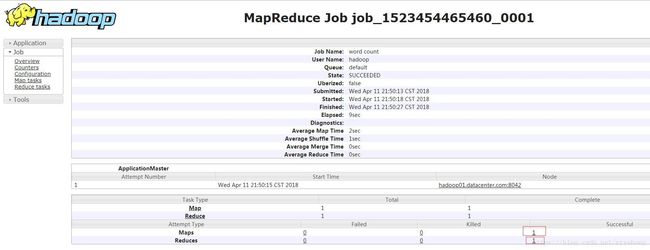
点击上图右下角标红的标签,我们可以查看map任务和reduce任务的详细信息,现在我们已map任务为例,将会跳转到新的界面:

日志聚集配置
前面我们讲到,可以通过历史服务查看具体的map和reduce任务信息,但是当我们点击单个任务的日志时,也会报错。
首先我们点击单个任务的日志(如下图,点击标红的“logs”标签)

跳转至新的界面(如下图所示),提醒我们日志聚集不可用

接下来我们在yarn-site.xml文件中配置日志聚集功能,设定日志保留7天
[hadoop@hadoop01 hadoop-2.5.0]$ vim etc/hadoop/yarn-site.xml
...
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
...
[hadoop@hadoop01 hadoop-2.5.0]$ 然后重启yarn和历史服务
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/yarn-daemon.sh stop resourcemanager
stopping resourcemanager
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/yarn-daemon.sh stop nodemanager
stopping nodemanager
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/mr-jobhistory-daemon.sh stop historyserver
stopping historyserver
[hadoop@hadoop01 hadoop-2.5.0]$ jps
3041 DataNode
4548 Jps
2979 NameNode
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/modules/hadoop-2.5.0/logs/yarn-hadoop-resourcemanager-hadoop01.datacenter.com.out
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/modules/hadoop-2.5.0/logs/yarn-hadoop-nodemanager-hadoop01.datacenter.com.out
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/modules/hadoop-2.5.0/logs/mapred-hadoop-historyserver-hadoop01.datacenter.com.out
[hadoop@hadoop01 hadoop-2.5.0]$ jps
5037 Jps
4840 NodeManager
4587 ResourceManager
3041 DataNode
4999 JobHistoryServer
2979 NameNode
[hadoop@hadoop01 hadoop-2.5.0]$ 此时之前的任务在yarn上已经无法看到,所以我们重新跑一个wordcount程序
[hadoop@hadoop01 hadoop-2.5.0]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount mapreduce/wordcount/input mapreduce/wordcount/output3
...
[hadoop@hadoop01 hadoop-2.5.0]$ 再次点击历史服务中的“logs”标签,跳转至日志信息界面

说明此时成功将nodemanager产生的日志聚集到hdfs上,并且将保留7天。
最后关闭相关服务:
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh stop namenode
stopping namenode
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh stop datanode
stopping datanode
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/yarn-daemon.sh stop resourcemanager
stopping resourcemanager
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/yarn-daemon.sh stop nodemanager
stopping nodemanager
[hadoop@hadoop01 hadoop-2.5.0]$ sbin/mr-jobhistory-daemon.sh stop historyserver
stopping historyserver
[hadoop@hadoop01 hadoop-2.5.0]$ jps
5782 Jps
[hadoop@hadoop01 hadoop-2.5.0]$ 总结
1、可以通过配置历史服务,查看已经完成的任务信息。
2、可以配置日志聚集,把nodemanager上的任务日志聚集到hdfs上。