使用Eclipse IDE搭建Apache Spark的Java开发环境
前言
本文介绍如何使用Eclipse IDE搭建Apache Spark的Java开发环境。
由于本文不会涉及具体的软件安装过程以及Eclipse相关功能的说明,所以需要具备一定的使用Eclipse IDE开发Java应用的经验。
实验环境
| 操作系统 | CPU | 内存 | JDK | Eclipse |
|---|---|---|---|---|
| Windows 10 专业版 64位 | Intel Core i7 | 8G | 1.8.0_111 | Neon.1 |
软件安装
Apache Spark
从Apache Spark官网下载Spark 2.1.0安装包。
下载地址:http://spark.apache.org/downloads.html
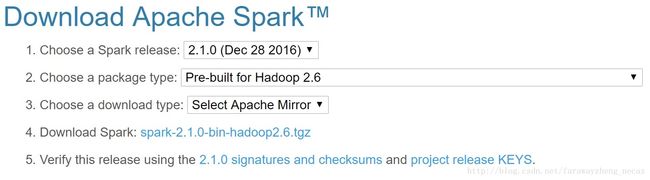
注1:在下载选项中“2. Choose a package type”我们选择“Pre-built for Hadoop 2.6”,是因为将来需要跟我的Spark 2.1.0 Docker运行环境进行对接实验。如果无此需求可以自由选择相应的选项。
注2:Spark 2.1.0 Docker运行环境请参照我的另一篇文章:《 创建Spark 2.1.0 Docker镜像》
将下载的压缩包解压到合适的目录下。(本例中解压至D:\)
D:\spark-2.1.0-bin-hadoop2.6> dir2017/01/15 23:32 <DIR> .
2017/01/15 23:32 <DIR> ..
2017/01/15 23:31 <DIR> bin
2017/01/15 23:31 <DIR> conf
2017/01/15 23:31 <DIR> data
2017/01/15 23:31 <DIR> examples
2017/01/15 23:31 <DIR> jars
2017/01/15 23:31 <DIR> licenses
2016/12/16 10:26 17,811 LICENSE
2016/12/16 10:26 24,645 NOTICE
2017/01/15 23:32 <DIR> python
2017/01/15 23:32 <DIR> R
2016/12/16 10:26 3,818 README.md
2016/12/16 10:26 128 RELEASE
2017/01/15 23:32 <DIR> sbin
2017/01/15 23:32 <DIR> yarn
4 个文件 46,402 字节
12 个目录 62,461,882,368 可用字节JDK 8
Java 8提供了对Lambda表达式的支持,推荐下载最新版本的JDK。
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
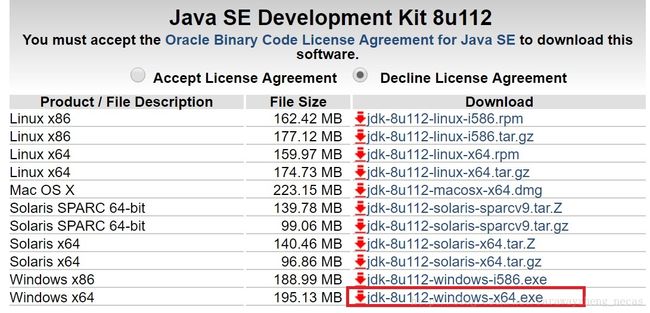
下载后运行安装包进行安装即可。
Eclipse IDE
最新的Eclipse IDE版本是Neon.2,推荐下载Eclipse IDE for Java EE Developers的发行版本,比 for Java Developers的多了一些必要的Package。不过两者都已经捆绑了Apache Maven Plugin,所以对于开发简单的Spark Java应用的来说,两者没有任何区别。

下载后运行安装包,根据提示安装Eclipse IDE。
winutils
Windows上运行Hadoop/Spark需要hadoop.dll和winutils.exe,但是官网提供的binary中并不包括这两个文件,利用源代码编译可以生成它们。如果感兴趣可以源代码编译试试,当然如果想省事的话,网上已经有其他人编译好的文件可供下载使用。
问题描述
http://stackoverflow.com/questions/35652665/java-io-ioexception-could-not-locate-executable-null-bin-winutils-exe-in-the-ha
http://stackoverflow.com/questions/19620642/failed-to-locate-the-winutils-binary-in-the-hadoop-binary-path从源代码编译请参考:
Windows 10编译Hadoop 2.6.0源码直接下载地址:
Hadoop 2.6.0 Windows 64-bit Binaries
Hadoop 2.6.0在Windows 10 64bit下的hadoop.dll和winutils.exe将下载的压缩包解压到合适的目录下。(本例中解压至D:\hadoop-2.6.0\bin)
D:\hadoop-2.6.0\bin> dir2017/01/16 12:03 .
2017/01/16 12:03 ..
2016/08/23 13:24 5,479 hadoop
2016/08/23 13:24 8,298 hadoop.cmd
2016/08/23 13:24 96,256 hadoop.dll
2016/08/23 13:24 21,457 hadoop.exp
2016/08/23 13:24 541,112 hadoop.iobj
2016/08/23 13:24 158,272 hadoop.ipdb
2016/08/23 13:24 35,954 hadoop.lib
2016/08/23 13:24 782,336 hadoop.pdb
2016/08/23 13:24 11,142 hdfs
2016/08/23 13:24 6,923 hdfs.cmd
2016/08/23 13:24 13,312 hdfs.dll
2016/08/23 13:24 224,220 hdfs.lib
2016/08/23 13:24 1,452,126 libwinutils.lib
2016/08/23 13:25 5,205 mapred
2016/08/23 13:25 5,949 mapred.cmd
2016/08/23 13:24 1,776 rcc
2016/08/23 13:24 114,176 winutils.exe
2016/08/23 13:24 510,194 winutils.iobj
2016/08/23 13:24 199,872 winutils.ipdb
2016/08/23 13:24 1,265,664 winutils.pdb
2016/08/23 13:25 11,380 yarn
2016/08/23 13:25 10,895 yarn.cmd
22 个文件 5,481,998 字节
2 个目录 62,457,643,008 可用字节 配置Spark运行环境
设置环境变量
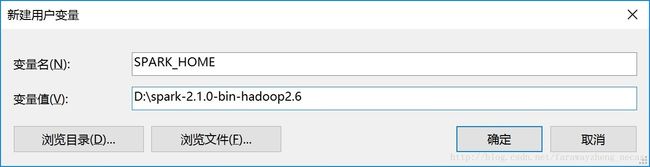
配置SPARK_HOME环境变量
系统属性->环境变量…->新建
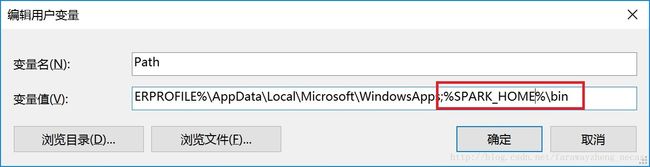
将Spark运行文件加入到系统环境变量Path中
系统属性->环境变量…->双击”Path”环境变量
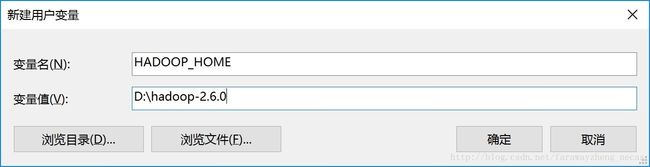
配置HADOOP_HOME环境变量
系统属性->环境变量…->新建
测试Spark运行环境
D:\run-example SparkPiUsing Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/01/17 12:48:37 INFO SparkContext: Running Spark version 2.1.0
......
17/01/17 12:48:38 INFO SparkEnv: Registering OutputCommitCoordinator
17/01/17 12:48:38 INFO Utils: Successfully started service 'SparkUI' on port 4040.
17/01/17 12:48:38 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.10.104:4040
17/01/17 12:48:38 INFO SparkContext: Added JAR file:/D:/spark-2.1.0-bin-hadoop2.6/bin/../examples/jars/scopt_2.11-3.3.0.jar at spark://192.168.10.104:9476/jars/scopt_2.11-3.3.0.jar with timestamp 1484628518660
17/01/17 12:48:38 INFO SparkContext: Added JAR file:/D:/spark-2.1.0-bin-hadoop2.6/bin/../examples/jars/spark-examples_2.11-2.1.0.jar at spark://192.168.10.104:9476/jars/spark-examples_2.11-2.1.0.jar with timestamp 1484628518661
17/01/17 12:48:38 INFO Executor: Starting executor ID driver on host localhost
17/01/17 12:48:38 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 9497.
......
17/01/17 12:48:40 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1128 bytes result sent to driver
17/01/17 12:48:40 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1128 bytes result sent to driver
17/01/17 12:48:40 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 852 ms on localhost (executor driver) (1/2)
17/01/17 12:48:40 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 778 ms on localhost (executor driver) (2/2)
17/01/17 12:48:40 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
17/01/17 12:48:40 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 0.886 s
17/01/17 12:48:40 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 1.154531 s
......
Pi is roughly 3.139915699578498
......
17/01/17 12:48:40 INFO SparkUI: Stopped Spark web UI at http://192.168.10.104:4040
17/01/17 12:48:40 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
......设置Eclipse IDE
新建项目
1) File菜单->New->Other
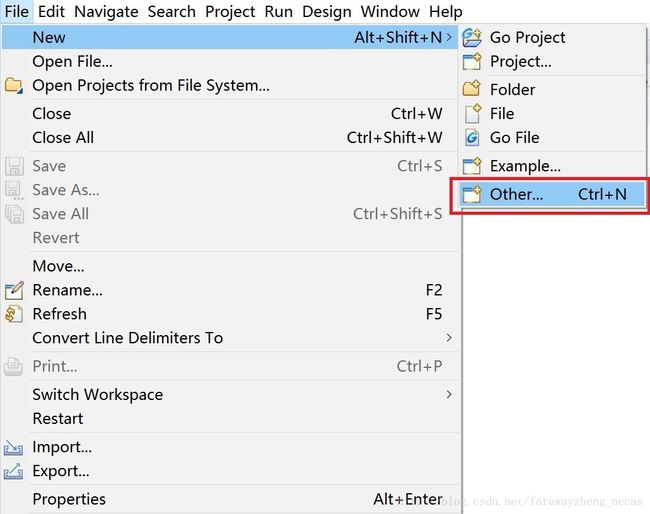
2) 新建Maven项目

3) 勾选”Create a simple project”
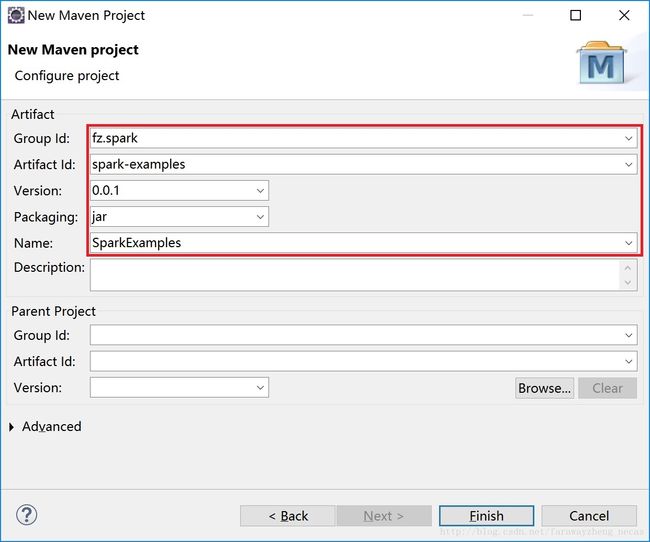
4) 填写Maven project的相关信息
5) 生成项目

编辑pom.xml
在Eclipse项目文件中双击pom.xml文件,选择“pom.xml”标签页。

将pom.xml替换为以下内容:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>fz.sparkgroupId>
<artifactId>spark-examplesartifactId>
<version>0.0.1version>
<name>SparkExamplesname>
<packaging>jarpackaging>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-launcher_2.11artifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>2.1.0version>
dependency>
dependencies>
project>保存pom.xml文件之后,Maven开始自动获取依赖包。依赖包保存的位置在“%USERPROFILE%.m2\repository”目录下。
注:Maven缺省从主站点(http://repo1.maven.org/maven2/)下载依赖包,由于我们的网络受到了良好的保护,所以基本上全程保持龟速。性子急的兄弟们请改用国内的镜像站点。
参考:
eclipse设置maven加载国内镜像
maven国内镜像(maven下载慢的解决方法)
测试在Eclipse中运行Spark应用
1) 新建Example1类
package fz.spark;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
public class Example1 {
/**
* @param args
*/
public static void main(String[] args) {
// Create the Java Spark Session by setting application name
// and master node "local".
try(final SparkSession spark = SparkSession
.builder()
.master("local")
.appName("JavaLocalWordCount")
.getOrCreate()) {
// Create list of content (the summary of apache spark's README.md)
final List content = Arrays.asList(
"Spark is a fast and general cluster computing system for Big Data. It provides",
"high-level APIs in Scala, Java, Python, and R, and an optimized engine that",
"supports general computation graphs for data analysis. It also supports a",
"rich set of higher-level tools including Spark SQL for SQL and DataFrames,",
"MLlib for machine learning, GraphX for graph processing,",
"and Spark Streaming for stream processing."
);
// Split the content into words, convert words to key, value with
// key as word and value 1, and finally count the occurrences of a word
@SuppressWarnings("resource")
final Map wordsCount = new JavaSparkContext(spark.sparkContext())
.parallelize(content)
.flatMap((x) -> Arrays.asList(x.split(" ")).iterator())
.mapToPair((x) -> new Tuple2(x, 1))
.countByKey();
System.out.println(wordsCount);
}
}
} 2) 运行Example1
在Eclipse项目文件中右键单击Example1.java文件,选择“Run As”->”Java Application”,或者快捷键“Alt + Shift + X, J”,运行Example1.class。
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/01/17 14:35:03 INFO SparkContext: Running Spark version 2.1.0
......
......
{GraphX=1, for=6, in=1, is=1, Data.=1, system=1, R,=1, Streaming=1, Scala,=1, processing,=1, data=1, set=1, optimized=1, a=2, provides=1, tools=1, rich=1, computing=1, APIs=1, MLlib=1, that=1, learning,=1, cluster=1, also=1, general=2, machine=1, processing.=1, supports=2, stream=1, Java,=1, high-level=1, Spark=3, It=2, fast=1, an=1, graph=1, Big=1, Python,=1, DataFrames,=1, graphs=1, analysis.=1, including=1, of=1, and=5, computation=1, higher-level=1, engine=1, SQL=2}
......
......
17/01/17 14:35:05 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
17/01/17 14:35:05 INFO SparkContext: Successfully stopped SparkContext
17/01/17 14:35:05 INFO ShutdownHookManager: Shutdown hook called
17/01/17 14:35:05 INFO ShutdownHookManager: Deleting directory C:\Users\farawayzheng\AppData\Local\Temp\spark-e9048a79-b48a-4f58-b8bc-4ce0fb65abd1
可以看到输出了WordCount结果,即表明单机运行Spark应用的环境配置成功。
(完)