Spark学习笔记:程序设计
基本流程
- 创建SparkContext对象
封装了spark执行环境的上下文信息,必须有且只有一个; - 创建RDD
可从Scala集合或Hadoop数据集上创建,利用Context对象的API创建RDD,可以将HBase表、MySQL表、本地文件等数据映射成RDD; - 在RDD之上进行Transformation和Action
Spark提供了多种Transformation和Action函数 - 返回结果
结果保存到HDFS中,或直接打印出来
创建SparkContext
- 创建conf,封装Spark配置信息
val conf = new SparkConf().setAppName(appName)
conf.set(“spark.app.name”, “MyFirstProgram”)
conf.set(“spark.master”, “local[*]”)
conf.set(“spark.ui.enabled” , “false”)
conf.set(“spark.default.parallelism”, “200”)
conf.set(“spark.yarn.queue”, “infrastructure”)
- 创建SparkContext,封装了调度器等信息
val sc = new SparkContext(conf)
sc通过conf来初始化,conf里可以设置各种参数,包括设置名称、
运行模式(本地还是集群Yarn-Clint,Yarn-Clust)
Spark Shell创建Spark Context时自动创建conf对象,所以在Spark Shell中不需要创建conf对象。
配置参数可以通过三种方式设置,优先级依次为:
1)在程序中写入(优先级最高)
conf.set(“spark.master”, “local[*]”)
2)提交命令里包含参数设置(优先级次之)
spark-submit \
--master spark \
--conf spark.ui.enabled=true
3)在配置文件中添加(优先级最低)
默认参数设置conf/spark-default.conf
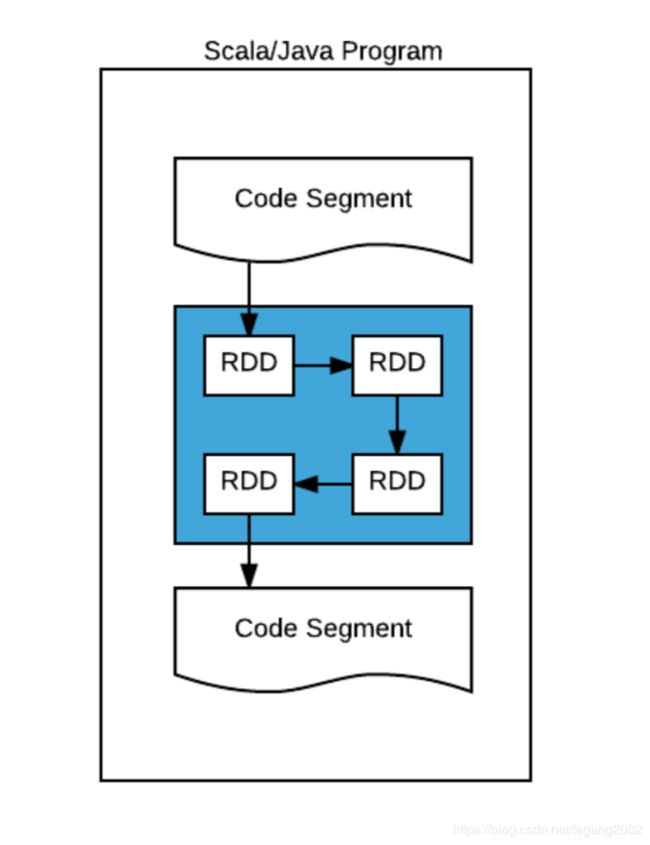 蓝色部分就是一个sc,可以把sc看做一个黑盒,里面运行RDD,RDD的转换完全由sc控制。
蓝色部分就是一个sc,可以把sc看做一个黑盒,里面运行RDD,RDD的转换完全由sc控制。
创建RDD
- Scala集合
sc.parallelize(List(1, 2, 3), 2)
// 把Scala集合映射成一个RDD,设置2个Partitions,1和2放一个Partition,3放一个Partition;
val slices = 10
//启动10个map task进行处理
val n = 100000 * slices
//每个map task 迭代10w次,迭代次数越多,产生结果越精确
val count = sc.parallelize(1 to n, slices).map { i =>
val x=random*2-1
val y=random*2-1
if(x*x+y*y<1) 1 else 0
}.reduce(_ + _)
-
本地文件/HDFS
可以将文件、目录映射成RDD,图片可以用SequenceFile格式处理,Key和Value可以是任意的字符串,可以把图片内容设为Value。
1)文本文件(TextInputFormat)sc.textFile(“file.txt”) //将本地文本文件加载成RDD sc.textFile(“directory/*.txt”) //将某类文本文件加载成RDD sc.textFile(“/data/input”,100)//将本地目录加载成RDD,把这个路径下所有的文件都作为输入,100是分区数,指输入分成100份 sc.textFile(“hdfs://namenode:8020/data/input”) //hdfs文件或目录2)SequenceFile文件(SequenceFileInputFormat)
sc.sequenceFile(“file.txt”) //将本地二进制文件加载成RDD sc.sequenceFile[String, Int] (“hdfs://nn:9000/path/file”)3)使用任意自定义的Hadoop InputFormat
sc.hadoopFile(path, inputFmt, keyClass, valClass)原则上Spark可以处理任何数据系统里的数据,如Orical和MySQL,文件系统,等等
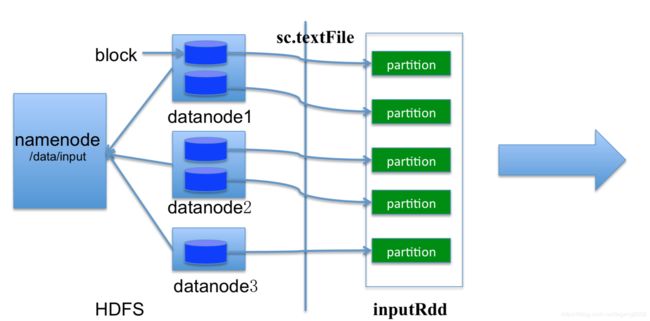 Partition的个数由Block数决定,Map Task的个数也默认和Block一致,Splite和Partition对应。
Partition的个数由Block数决定,Map Task的个数也默认和Block一致,Splite和Partition对应。
Transformation和Action
Transformation:将一个RDD通过一种规则,映射成另一种RDD;
Action:返回结果或者保存结果,只有Action才会触发程序的执行。

- RDD Transformation
//创建RDD
val listRdd = sc.parallelize(List(1, 2, 3), 3)
// 将RDD传入函数做Map映射,生成新的RDD,一一对应,输入RDD的元素个数和输出的RDD的元素个数一样
val squares = listRdd.map(x => x*x) // {1, 4, 9}
// 对RDD中元素进行过滤,生成新的RDD,Filter过滤返回值为True或False
val even = squares.filter(_ % 2 == 0) // {4}
// 将一个元素映射成多个,生成新的RDD,一对多的映射
nums.flatMap(x => 1 to x) // => {1, 1, 2, 1, 2, 3}
Map映射:
一一对应,输入RDD的元素个数和输出的RDD的元素个数一样
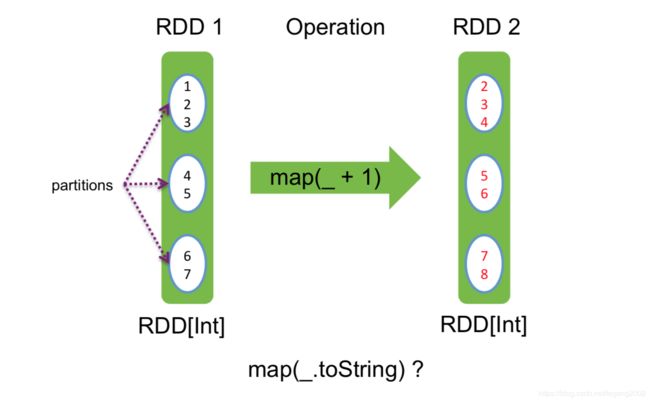 Filter过滤:
Filter过滤:
返回值为True或False
 Filter操作比较危险,把RDD中比较均等的Partiton变为不均等,这样会造成Task运算时间不均等,有些Task会拖后腿。
Filter操作比较危险,把RDD中比较均等的Partiton变为不均等,这样会造成Task运算时间不均等,有些Task会拖后腿。
FlatMap:
一对多的映射
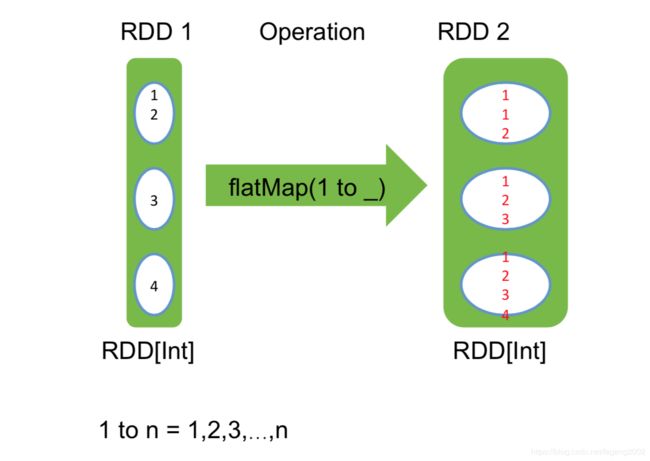
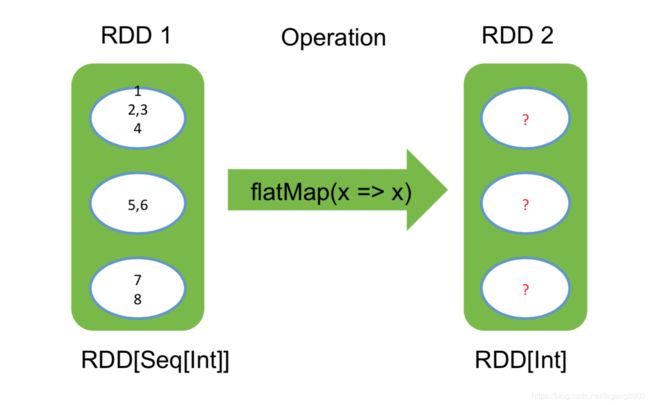 RDD是Seq[Int]类型,RDD2变成了Int类型,返回1、2、3、4、5、6、7、8八个整形数
RDD是Seq[Int]类型,RDD2变成了Int类型,返回1、2、3、4、5、6、7、8八个整形数
Glom
将RDD的元素按照分区聚合成为数组
val rdd = sc.makeRDD(1 to 6, 3)
rdd.glom.collect
返回
Array[Array[Int]]=Array(Array(1,2),Array(3,4),Array(5,6))
Union
将多个RDD合并为一个RDD
rdd1 = sc.makeRDD(1 to 6, 3)
rdd2 = sc.makeRDD(7 to 11, 2)
rdd3=rdd1.union(rdd2)
rdd3=rdd2 ++ rdd1
sc.union(rdd1, rdd2, rdd3)
合并之后的RDD包含合并之前的RDD,合并之后的RDD的分区是合并之前RDD的分区之和:
rdd3.glom.collect
Array[Array[Int]]=Array(Array(1,2),Array(3,4),Array(5,6),Array(7,8),Array(9,10,11))
Coalesce
合并一个RDD的分区,有时分区太多,太耗资源,需要用到这个函数减少分区。
rdd3 = rdd1 ++ rdd2 ++ sc.makeRDD(12 to 50, 1)
rdd3.coalesce(3)
返回
Array[Array[Int]]=Array(Array(1,2,3,4),Array(5,6,7,8),Array(9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50))
参数2为true是尽量均匀的合并分区,元素会重新排列。
rdd3.coalesce(3, true)
返回
Array[Array[Int]]=Array(Array(6,7,9,12,15,18,21,24,27,30,33,36,39,42,45,48),Array(1,3,8,10,13,16,19,22,25,28,31,34,37,40,43,46,49),Array(2,4,5,11,14,17,20,23,26,29,32,35,38,41,44,47,50))
Repartition
让RDD的元素在分区之间均匀分布,把少数分区尽量均匀的变为多数分区
有时并行度不够,计算效率低,需要用到这个函数。
rdd4=rdd3.repartition(12)
返回
rdd4.glom.collect
Array[Array[Int]]=Array(Array(12,24,36,48),Array(1,13,25,37,49),Array(2,14,26,38,50),Array(7,9,15,27,39),Array(8,10,16,28,40),Array(5,11,17,29,41),Array(6,18,30,42),Array(19,31,43),Array(28,32,44),Array(21,33,45),Array(3,22,34,46),Array(4,23,35,47))
rdd4.glom.collect.map(_.size)
Array[Int]=Array(4,5,5,5,5,5,4,3,3,3,4,4)
Zip
将两个RDD的元素进行一一映射
rdd1 = sc.makeRDD(Seq(’a’, ’b’, ‘c’, ‘d’, ‘e’))
rdd2 = sc.makeRDD(Seq(‘A’, ‘B’, ‘C’, ‘D’, ‘E’))
rdd3=rdd1.zip(rdd2)
返回
rdd3.collect
Array[(Char, Char)]=Array((a,A),(b,B),(c,C),(d,D),(e,E))
其他一些操作符
sample(): 从数据集中采样
cartesian(): 求笛卡尔积
pipe(): 传入一个外部程序
- RDD Action
//创建新的RDD
val nums = sc.parallelize(List(1, 2, 3), 2)
// 将RDD保存为本地集合(返回到driver端)
nums.collect() // => Array(1, 2, 3)
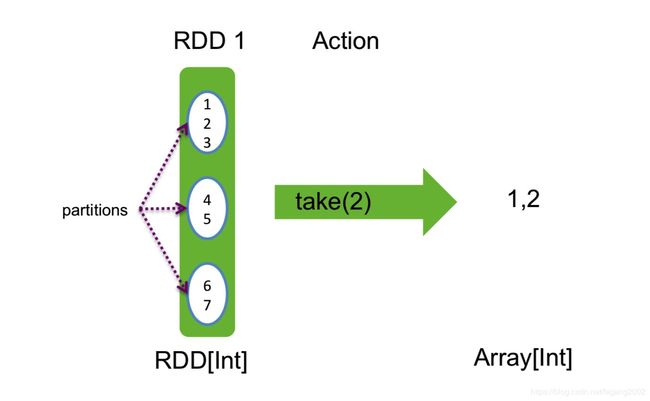
// 返回前K个元素
nums.take(2) // => Array(1, 2)
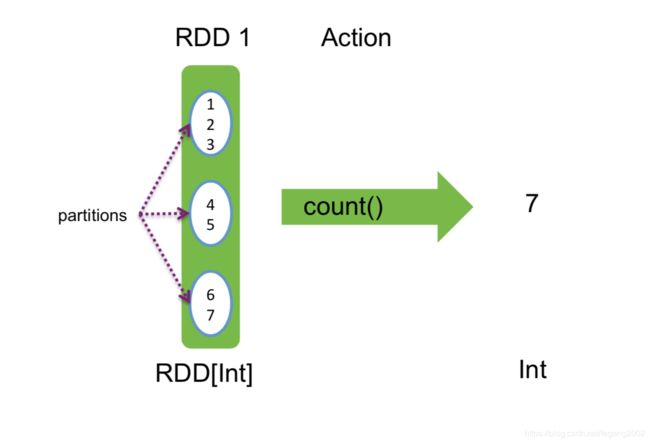
// 计算元素总数
nums.count() // => 3
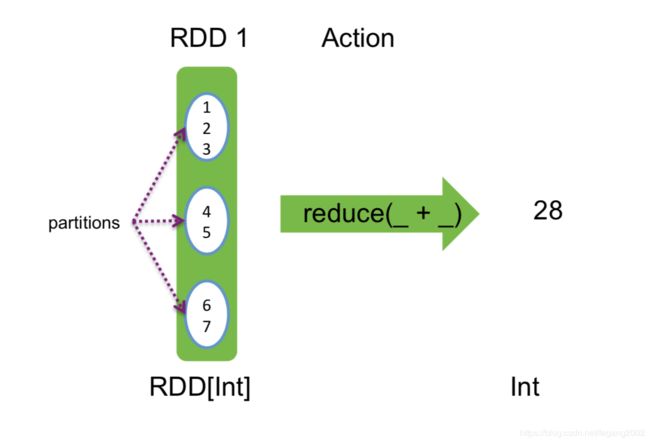
// 合并集合元素
nums.reduce(_ + _) // => 6
// 将RDD写到HDFS中
nums.saveAsTextFile(“hdfs://nn:8020/output”)
nums.saveAsSequenceFile(“hdfs://nn:8020/output”)
Collect

Take
Count
 Reduce
Reduce
 ForEach
ForEach

Key/Value类型的RDD处理
Key/Value类型的RDD,每个元素都是Key和Value。ByKey结尾的Transformation都是为Key/Value类型RDD准备的。
val pets = sc.parallelize(List((“cat”, 1), (“dog”, 1), (“cat”, 2)))
pets.reduceByKey(_ + _) // => {(cat, 3), (dog, 1)}
pets.groupByKey() // => {(cat, Seq(1, 2)), (dog, Seq(1)} ,Seq()是Scala的集合
pets.sortByKey() // => {(cat, 1), (cat, 2), (dog, 1)}
reduceByKey自动在Map端进行本地combine,groupByKey的Value相加就是reduceByKey。reduceByKey可以通过groupByKey实现,先做分组,然后再把Value相加。
MapValues
 reduceByKey
reduceByKey
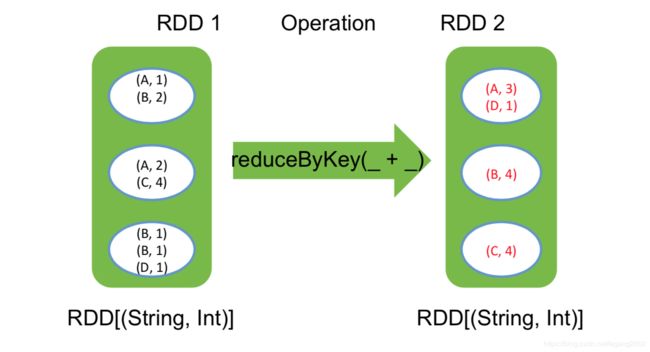
groupByKey
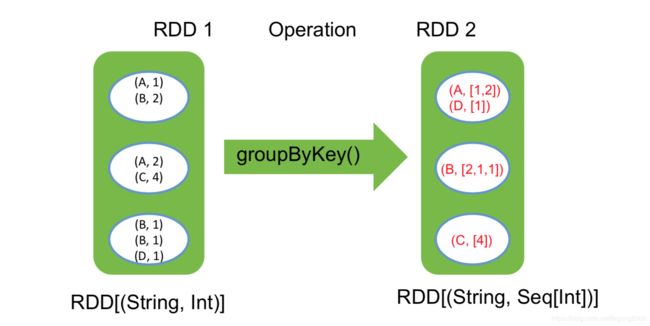
Join
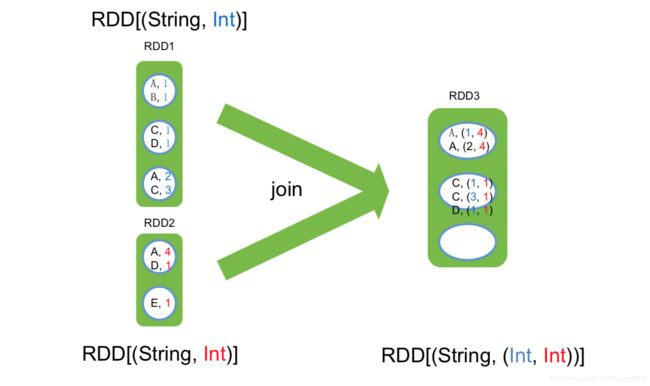
Union
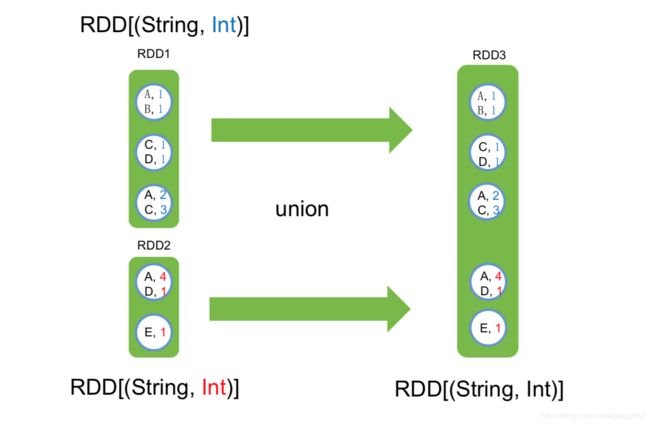
coGroup
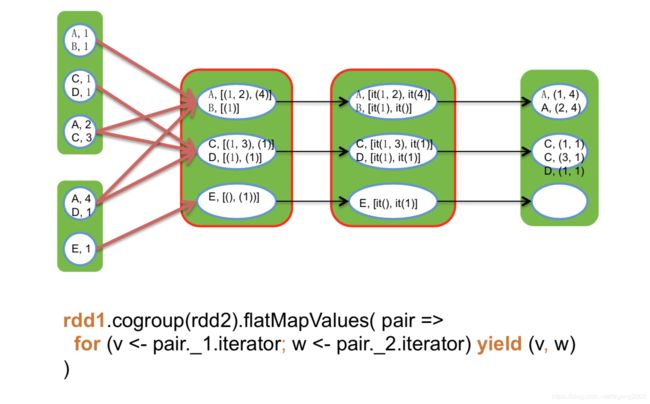
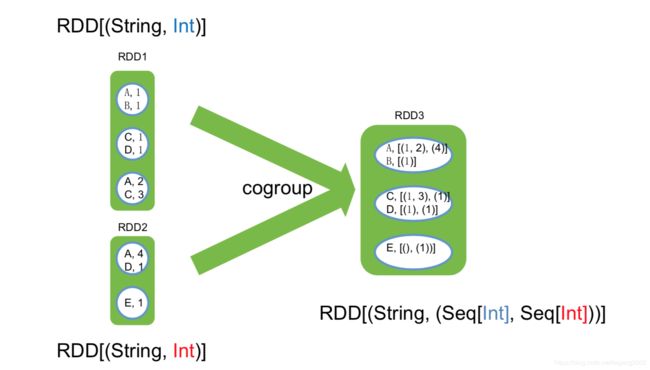 coGroup & Join
coGroup & Join
控制Reduce Task的数量
- 所有key/value RDD操作符均包含一个可选参数,表示Reduce Task并行度
1)words.reduceByKey(_ + _, 5)
2)words.groupByKey(5)
3)visits.join(pageViews, 5) - 用户也可以通过修改spark.default.parallelism设置默认并行度
默认并行度为最初的RDD partition数目
广播机制
Spark可以通过广播机制,高效分发对象,比如字典(Map),集合(Set)等,每个Executor一份。通过广播,把RDD要引用的外部数据集合发送到Executor,然后在Executor运算时使用。广播的形式,让大数据集的读写次数等于Executor的个数,通过广播可以减少网络开销,提升效率。
val data = Set(1, 2, 4, 6, .....) // 大小为128MB
val bdata = sc.broadcast(data) // 将大小为128MB 的Set广播出去
val rdd = sc.parallelize(1to 1000000, 100)
val observedSizes= rdd.map(_ => bdata.value.size ....) //在各个Task中,通过bdata.value获取广播的集合

广播机制包括HttpBroadcast和TorrentBroadcast两种:
1)HttpBroadcast:Executor节点从Driver拉数据;
2)TorrentBroadcast:Executor可以从已经有了数据的其他Executor上拉取数据,可以避免网络都拥堵在Driver,现在默认使用TorrentBroadcast。
累加器
类似于MapReduce中的Counter,将数据从一个节点发送到其他各个节
点上去,通常用于监控,调试,记录符合某类特征的数据数目等。
import SparkContext._
val total_counter = sc.accumulator(0L, "total_counter")
val counter0 = sc.accumulator(0L, "counter0")
val counter1 = sc.accumulator(0L, "counter1")
// 定义两个累加器
val count = sc.parallelize(1 to n, slices).map { i =>
total_counter += 1
val x = random * 2 - 1
val y = random * 2 – 1
if (x*x + y*y < 1) {
counter1 += 1
//累加器counter1 加1
} else {
counter0 += 1
//累加器counter0 加1
}
if (x*x + y*y < 1) 1 else 0
}.reduce(_ + _)
Spark程序提交
export YARN_CONF_DIR=/opt/hadoop/yarn-client/etc/hadoop
bin/spark-submit \
--master yarn-cluster \ // 运行模式:local, yarn-clisnt, yarn-cluster
--class com.hulu.examples.SparkPi \ // 应用程序主类
--name sparkpi \ // 作业名称
--driver-memory 2g \ // Driver需要的内存
--executor-memory 3g \ //每个Executor需要的内存
--executor-cores 2 \ //每个Executor线程数
--num-executors 2 \ 需启动的Executor总数
--queue spark \ //提交到的队列名称
--conf spark.pi.iterators=500000 \ //用户自定义配置
--conf spark.pi.slices=10 \ $FWDIR/target/scala-2.10/spark-example-assembly-1.0.jar //用户应用程序所在jar包
提交Spark程序运行在Yarn上:
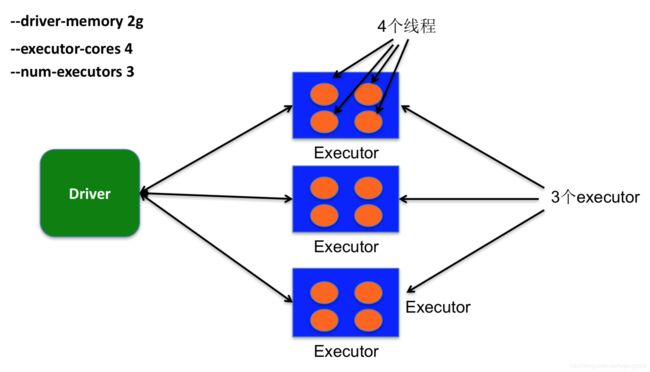
应用示例
- WordCount
val lines = sc.textFile("hamlet.txt")
val counts = lines.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_+_)

- Join
val visits = sc.parallelize(List(("index.html","1.2.3.4"),("about.html","3.4.5.6"),("index.html","1.3.3.1")) val pageNames = sc.parallelize(List(("index.html","Home"),("about.html","About")) visits.join(pageNames) // ("index.html",("1.2.3.4","Home")) // ("index.html",("1.3.3.1","Home")) // ("about.html",("3.4.5.4","About")) visits.cogroup(pageNames) // ("index.html",(Seq("1.2.3.4","1.3.3.1"),Seq("Home"))) // ("about.html",(Seq("3.4.5.6"),Seq("About")))
参考链接
www.spark-project.org/documentation.html
http://spark.apache.org/
https://github.com/apache/spark/tree/master/examples/src/main