Word2vec与Golve词向量的区别?词向量的判别评价指标?
Glove模型首先基于语料库构建词的共现矩阵,然后基于共现矩阵学习词向量。设共现矩阵为X,其元素为Xi,j表示在整个语料库中,词i和词j共同出现在一个窗口中的次数。
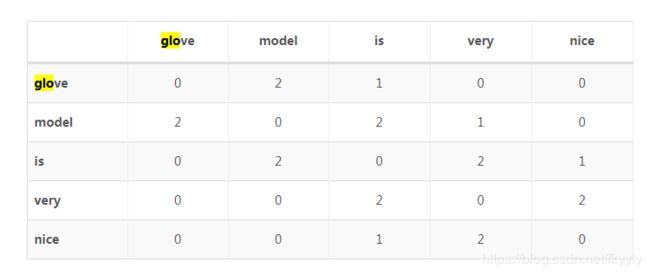
https://ilewseu.github.io/2018/07/08/%E8%AF%8D%E5%90%91%E9%87%8F/
http://licstar.net/archives/tag/%E8%AF%8D%E5%90%91%E9%87%8F
GloVe与word2vec,两个模型都可以根据词汇的“共现co-occurrence”信息,将词汇编码成一个向量(所谓共现,即语料中词汇一块出现的频率)。两者最直观的区别在于,word2vec是“predictive”的模型,而GloVe是“count-based”的模型。具体是什么意思呢?
Predictive的模型,如Word2vec,根据context预测中间的词汇,要么根据中间的词汇预测context,分别对应了word2vec的两种训练方式cbow和skip-gram。对于word2vec,采用三层神经网络就能训练,最后一层的输出要用一个Huffuman树进行词的预测(这一块有些大公司面试会问到,为什么用Huffuman树,大家可以思考一下)。
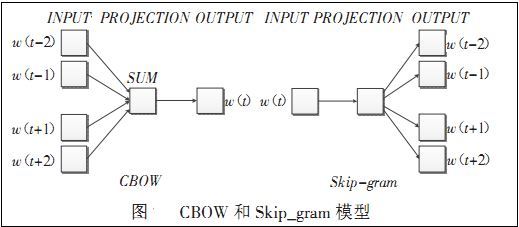
Count-based模型,如GloVe,本质上是对共现矩阵进行降维。首先,构建一个词汇的共现矩阵,每一行是一个word,每一列是context。共现矩阵就是计算每个word在每个context出现的频率。由于context是多种词汇的组合,其维度非常大,我们希望像network embedding一样,在context的维度上降维,学习word的低维表示。这一过程可以视为共现矩阵的重构问题,即reconstruction loss。(这里再插一句,降维或者重构的本质是什么?我们选择留下某个维度和丢掉某个维度的标准是什么?Find the lower-dimensional representations which can explain most of the variance in the high-dimensional data,这其实也是PCA的原理)。
两种方法都能学习词的向量表示,在real world application中,他们效果上有啥差别呢?
答案是performance上差别不大。
两个模型在并行化上有一些不同,即GloVe更容易并行化,所以对于较大的训练数据,GloVe更快。
在英文上,glove for GloVe 和 gensim for word2vec是常用的训练词向量的python package,完全可以使用自己的训练语料训练词向量。当然,他们都提供了google news(英文)上训练好的词向量,大家完全可以下载下来,直接使用。对于中文的训练语料,可以使用sogou中文新闻语料。
更多关于GloVe和word2vec的区别详见论文:
Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors
当然还是希望大家读一读原答案:https://www.quora.com/How-is-GloVe-different-from-word2vec
https://zhuanlan.zhihu.com/p/31023929
对于词向量的评价更多还是应该考虑对实际任务的收益,脱离的实际任务很难确定A模型就一定比B好,毕竟词向量方法更多是一种工具。
1、语义相关性任务
这个任务用来评价词向量模型在两个词之间的语义相关性,如:学生与作业,中国与北京等。
具体方法由监督模式实现,首先需要一份如下的标记文件,一般可以由人工标注:
学生 上课 0.78
教师 备课 0.8
上述文件代表了词语之间的语义相关性,我们利用标注文件与训练出来的词向量相似度进行比较,如:词向量之间的cos距离等,确定损失函数,便可以得到一个评价指标。
但这种方法首先需要人力标注,且标注的准确性对评价指标影响非常大。
2、语义类比任务
这个任务词向量来考察不同单词间的语义关系能力,一般给定三个词,如a、b、c,要求寻找a+b = c + ?任务中最相似的词,一般使用向量间距离来进行寻找,如:
queen-king+man=women
同样需要准备标记文件,根据寻找出来的词的正确率判断词向量的质量。
3、文本分类任务
这个任务利用词向量构成文本向量,一般采用求和平均的方式,之后利用构成的文本向量进行文本分类,根据分类的准备率等指标衡量词向量的质量。
https://blog.csdn.net/sinat_33741547/article/details/80983731