SpringBoot2 结合BeetlSQL开发
为什么是SpringBoot2:SpringBoot自从正式版发布以来,受到了众多的关注和追捧。在2.0出来之后,已经与1.X有了很多不同之处。当然也是为了追赶潮流,直接上了2.0作为本文基础框架,当然1.X的版本也是可以使用的。
为什么是BeetlSql:这是一个在国内还没有那么火的DAO工具,根据官网的说法:“ 它是一个超过MyBatis的全功能Java DAO工具,同时具有Hibernate 优点 & Mybatis优点功能,适用于承认以SQL为中心,同时又需求工具能自动能生成大量常用的SQL的应用。”。本人抱着试一试的想法用此框架进行Demo开发,感觉不错。并且已经用于公司的实战中。该框架与MyBatis以及Hibernate的 网上可以搜索到,本人就不赘述。
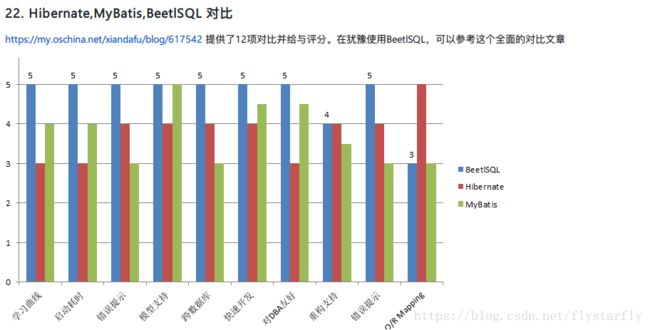
在SpringBoot已经出到2.0正式版之后,利用SpringBoot的特点,结合BeetlSQL的优势,可以快速的搭建一个实战级别的项目架构。
话不说多,我们开始吧!
首先开始照常,先搭建一个SpringBoot2的框架。可以新建一个maven project。在pom.xml中引入
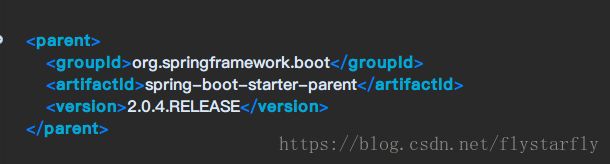
2.0.X, 不管X是几,只要是正式版都行。

引入spring-boot-starter-web。排除tomcat是为了打war包放入外部tomcat的时候少生成内嵌tomcat的包或者用其他内嵌容器(比如jetty或者undertow),当然可以直接用内嵌的tomcat来调试。

引入内嵌容器undertow。该容器经过大神的对比,据说是内嵌容器中性能优化的比较好的。并且引入mysql驱动。(BeetlSQL本身并没有mysql驱动,故需要引入)。

关键的来了,引入了beetl的Starter。这个依赖相对于 以前的spring boot结合beetlsql来说, 要方便许多。为什么这么说呢?以前的引入方式是这样的。

不仅是多个依赖,还要在类中加入各种代码。比如下面的 beetlsqlrepository所在路径配置
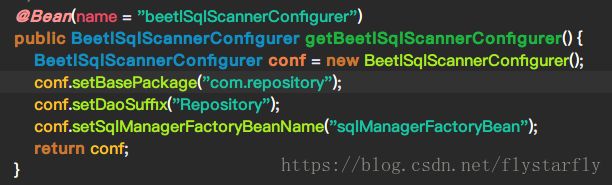
还有下面的qlManager工厂类配置,如数据库配置,加载SQL文件路径配置等
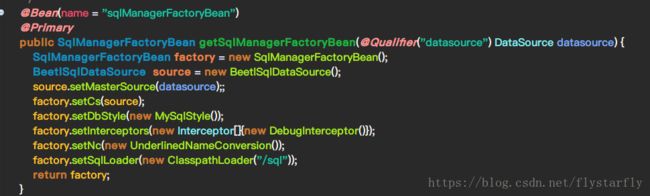
这些用了Starter之后,也可以放在application配置文件中了
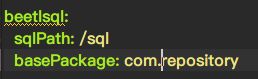
当然datasource还是要另外写配置类

好了。配置部分完成。开始代码实战。请原谅我借用下官网的实体类
为了快速尝试BeetlSQL,需要准备一个Mysql数据库或者其他任何beetlsql支持的数据库,然后执行如下sql脚本
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(64) DEFAULT NULL,
`age` int(4) DEFAULT NULL,
`userName` varchar(64) DEFAULT NULL COMMENT '用户名称',
`roleId` int(11) DEFAULT NULL COMMENT '用户角色',
`create_date` datetime NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;编写一个Pojo类,与数据库表对应(或者可以通过SQLManager的gen方法生成此类,参考一下节)
import java.math.*;
import java.util.Date;
/*
*
* gen by beetlsql 2016-01-06
*/
public class User {
private Integer id ;
private Integer age ;
//用户角色
private Integer roleId ;
private String name ;
//用户名称
private String userName ;
private Date createDate ;
}生成pojo 和 md文件
SQLManager sqlManager = new SQLManager(style,loader,cs,new DefaultNameConversion(), new Interceptor[]{new DebugInterceptor()});
//sql.genPojoCodeToConsole("userRole"); 快速生成,显示到控制台
// 或者直接生成java文件
GenConfig config = new GenConfig();
config.preferBigDecimal(true);
config.setBaseClass("com.test.User");
sqlManager.genPojoCode("UserRole","com.test",config);接下来。。。。。。当然是数据访问层的类了,强大的BeetlSQL发挥实力的地方到了

不需要实现类,为何,因为BaseMapper封装了增删改查。查看BaseMapper的源码可以看到:
/**
* BaseMapper.
*
* @param
* the generic type
*/
public interface BaseMapper
/**
* 通用插入,插入一个实体对象到数据库,所以字段将参与操作,除非你使用ColumnIgnore注解
* @param entity
*/
void insert(T entity);
/**
* (数据库表有自增主键调用此方法)如果实体对应的有自增主键,插入一个实体到数据库,设置assignKey为true的时候,将会获取此主键
* @param entity
* @param autDbAssignKey 是否获取自增主键
*/
void insert(T entity,boolean autDbAssignKey);
/**
* 插入实体到数据库,对于null值不做处理
* @param entity
*/
void insertTemplate(T entity);
/**
* 如果实体对应的有自增主键,插入实体到数据库,对于null值不做处理,设置assignKey为true的时候,将会获取此主键
* @param entity
* @param autDbAssignKey
*/
void insertTemplate(T entity,boolean autDbAssignKey);
/**
* 批量插入实体。此方法不会获取自增主键的值,如果需要,建议不适用批量插入,适用
*
* insert(T entity,true);
*
* @param list
*/
void insertBatch(List
/**
* (数据库表有自增主键调用此方法)如果实体对应的有自增主键,插入实体到数据库,自增主键值放到keyHolder里处理
* @param entity
* @return
*/
KeyHolder insertReturnKey(T entity);
/**
* 根据主键更新对象,所以属性都参与更新。也可以使用主键ColumnIgnore来控制更新的时候忽略此字段
* @param entity
* @return
*/
int updateById(T entity);
/**
* 根据主键更新对象,只有不为null的属性参与更新
* @param entity
* @return
*/
int updateTemplateById(T entity);
/**
* 根据主键删除对象,如果对象是复合主键,传入对象本生即可
* @param key
* @return
*/
int deleteById(Object key);
/**
* 根据主键获取对象,如果对象不存在,则会抛出一个Runtime异常
* @param key
* @return
*/
T unique(Object key);
/**
* 根据主键获取对象,如果对象不存在,返回null
* @param key
* @return
*/
T single(Object key);
/**
* 根据主键获取对象,如果在事物中执行会添加数据库行级锁(select * from table where id = ? for update),如果对象不存在,返回null
* @param key
* @return
*/
T lock(Object key);
/**
* 返回实体对应的所有数据库记录
* @return
*/
List
/**
* 返回实体对应的一个范围的记录
* @param start
* @param size
* @return
*/
List
/**
* 返回实体在数据库里的总数
* @return
*/
long allCount();
/**
* 模板查询,返回符合模板得所有结果。beetlsql将取出非null值(日期类型排除在外),从数据库找出完全匹配的结果集
* @param entity
* @return
*/
List
/**
* 模板查询,返回一条结果,如果没有,返回null
* @param entity
* @return
*/
List
void templatePage(PageQuery
/**
* 符合模板得个数
* @param entity
* @return
*/
long templateCount(T entity);
/**
* 执行一个jdbc sql模板查询
* @param sql
* @param args
* @return
*/
List
/**
* 执行一个更新的jdbc sql
* @param sql
* @param args
* @return
*/
int executeUpdate(String sql,Object... args );
SQLManager getSQLManager();
/**
* 返回一个Query对象
* @return
*/
Query
/**
* 返回一个LambdaQuery对象
* @return
*/
LambdaQuery
}
通用的方法全有,并且注释还是中文(毕竟是国人开发的)。具体可以看官方 文档。当然,一个项目不会只需要基础的增删改查,还有统计,分页,多表查询等等。不要急,一切都会有的。
复杂的sql可以写在md格式的Sql文件里面。放在application配置中间中的sqlPath属性指定的路径中。 比如我们已经指定了/sql这个路径。它具体会放在src/main/resources/sql中。
如图,我们先做一个查询的例子:
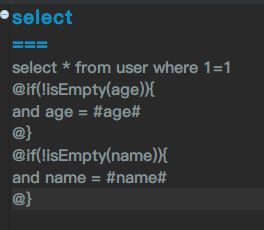
- 采用md格式,===上面是sql语句在本文件里的唯一标示,下面则是sql语句。
- @ 和回车符号是定界符号,可以在里面写beetl语句。
- "#" 是占位符号,生成sql语句得时候,将输出?,如果你想输出表达式值,需要用text函数,或者任何以db开头的函数,引擎则认为是直接输出文本。
- isEmpty是beetl的一个函数,用来判断变量是否为空或者是否不存在.
- 文件名约定为类名,首字母小写。
具体说明详见官方网站的文档。这个唯一标识则可以用过
public List select(String sqlId, Class clazz) 根据sqlid来查询,这些方法来使用。
BeetlSQL提供了使用page函数或者pageTag标签,这样才能同时获得查询结果集总数和当前查询的结果。这当然是放在/sql文件夹中的md文件里面、
queryNewUser
===
select
@pageTag(){
a.*,b.name role_name
@}
from user a left join b ...怎么样,使用原生sql的方式是不是一目了然?Sql放在md文件中也会比Mybatis的xml方式更加的简洁明了,也会比 注解方式写入Sql更加能够减少代码行数。
BeetlSQL还提供了Debug打印sql语句的能力
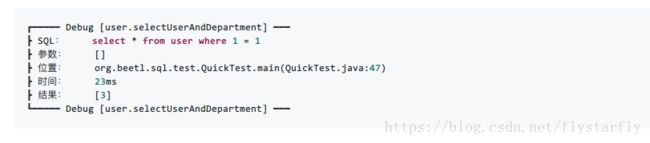
所有的sql都可以获取执行的语句和参数,执行时间,执行结果。不需要人为另外操作就可以轻松掌握自己写的sql语句是否有错误或者有优化的空间。
当然BeetlSQL还有更多强大的功能。