Hadoop, MapReduce,Hive, HBase, Storm, Spark, Flink, Kylin等大数据框架的角色和关系
各种大数据框架近几年发展得如火如荼,比如Hadoop, MapReduce,Hive, Hbase, Storm, Spark, Flink, Kylin 等,各个框架的角色是怎么样的?如何配合起来使用?本文将从时间顺序上逐个说明。
首先要介绍一下Hadoop,现在Hadoop分为3部分,分别是HDFS,Yarn和Mrv2
近几年大数据潮流的推进,是需求和技术相互促进的结果,对大数据需求最强烈公司非Google这个互联网巨头莫属,所以Google率先攻克了大数据处理的技术难题,满足了它自己的业务需要。Google采用的方法是“分布式计算”,用大量的普通服务器组成集群,并发处理数据;
Google总结自己的经验,发了3篇论文,被称为大数据的三大论文。开源社区基于论文中的设计思路,实现了Hadoop开源软件,让更多的中小公司可以低成本地运用大数据,然后进一步引出更多的大数据需求。
多机并行处理的思想由来已久,但是实现一个多机协同的并行处理程序难度非常高,Hadoop开源软件拆除了这个障碍。目前Hadoop被称为一个“生态”,相关的软件项目繁多,通常情况下,大家说的Hadoop,指的是提供海量数据存储能力的HDFS,管理大量机器运算资源的Yarn以及一个编程框架MapReduce。有了这些工具,普通水平的程序员也可以轻松处理TB级别的数据。
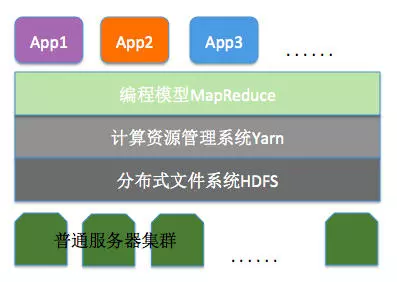
上图的App指的是一个具体的任务,比如运行一个word count,在大数据集上对某个列进行排序等。
HDFS:
HDFS的设计思路主要有三点:一是普通服务器的硬性故障是常态,而不是“异常”,所以分布式文件系统要有自动化的容错性;二是和Linux或者Windows的文件系统相比,分布式文件系统存储的文件要大得多,所以存储粒度大;三是存储的大文件,很少需要修改其中的某一小部分,通常情况下只需要在尾部追加内容。有了HDFS,TB、PB基本的数据存取很容易了,不但如此,HDFS还要多并行处理提供支持,并行处理需要并发地读和写文件。
Yarn:
Yarn由一个ResourceManager和每台机器上的一个NodeManager组成。ResourceManage拥有为系统中所有应用分配资源的绝对权力。NodeManager作为每个机器上的容器,管理系统资源(cpu,memory,disk,network)的使用情况,并向ResourceManager或者Scheduler报告。
在Yarn上运行分布式应用,是通过ApplicationsMaster进行的,这里的应用指一个MapR job或者构成DAG图的多个job,应用运行结束相应的ApplicationsMaster就关闭退出了。
有些持续运行的框架,比如Hbase比较特殊,可以部署在yarn上,也可以不部署在yarn上。还有flink在yarn上运行,有两种部署方式: 一是long-running Flink cluster on YARN;另一种是 run a Flink job on YARN。
Mesos也是一个分布式集群的资源管理框架,相比较yarn它更底层,使用mesos需要它上面计算框架实现更多东西。使用Hadoop组件有这样一种部署方式,是先启动mesos,然后再在上面部署hdfs,yarn,这样就可以运行mapreduce了。Spark,flink这种计算框架都支持直接部署到mesos上(需要用到hdfs的话,需要在mesos上部署hdfs)。
Mrv2:
再了解了解ApplicationsMaster
Yarn支持不同的计算框架是通过ApplicationsMaster来实现的,不同的计算框架实现各自的类库,然后由ApplicationsMaster运行,比如Mrv2,Spark,Flink都可以通过这种方式在Yarn上运行。
Mrv2运行时,首先作为ApplicationsMaster向Yarn的ResourceManager请求所需的资源,然后通过和NodeManager配合启动这些资源,监控它们的执行情况,直到任务运行结束,然后这个ApplicationsMaster实例退出。
Hive
Hive的出现是为了自动化编写MapReduce程序。根据上面的介绍,基于Mrv2的计算框架,我们实现相应的Mapper,Reducer后就可以提交运行,然后通过Yarn的调度,执行完这个MapReduce程序。
但是一个Mapper、一个Reducer的能力有限,完成一个实际业务目的可能需要很多个步骤,比如对一个大的数据集,首先通过某个字段筛选出想要的行,然后根据另一个字段分组统计,最后再对结果进行排序。这些功能逐个通过Mapreduce实现就比较繁琐了,并且对不同的数据集,处理方式可能类似,都是筛选、分组统计、排序等相似的功能。我们可以通过熟悉的SQL语句来描述需要对数据进行的处理,然后通过hive里的引擎把sql转换成一个或多个mapreduce任务并调度执行,这就大大减少了相似的mapreduce编写工作,提高了效率。
HBase
HBase是一个分布式noSql数据库,是google的bigtable论文的开源实现。
HBase可以被理解成一个打的Map数据结构,类似Map
HBase也是Hadoop家族的成员,所以它对Mrv2,Hive的支持很好,可以作为它们的数据源或者结果存储位置;作为Mrv2数据源的时候,Hbase可以提供在HDFS上的位置信息,实现高效的并行计算。
Spark
Spark被认为是第二代大数据处理框架。第一代框架是基于简单的Map Reduce模型的,第一代计算框架和运算的基础,也就是分布式文件系统和分布式资源管理系统一起被创建出来。Spark沿用现有的分布式文件系统和分布式资源管理系统,在计算模型方面有很大的创新。
上面提到Hive可以把sql语句转成多个Mapreduce任务并执行,这和逐个实现Mapper Reducer相比有很大的效率提升;Spark是改进了Mrv2运算模型,首先向上层用户提供更多的算子来表达业务逻辑,底层则把每次任务转换成DAG图,对DAG图进行物理运算的时候,更多地利用内存来缓存,减少JVM的启停次数等,通过这些方法大大提高了数据处理速度。
Spark的生态也很完善,比如Spark Sql,Spark Streaming,Spark MLlib等。
Flink
Flink很长一段时间被Spark的光环掩盖,Flink的特点是实时流计算(Spark Streaming可以轻松做到秒级别的实时计算),把实时计算提到了更高的优先级。
Flink充分考虑事件的时间属性,通过WaterMark等机制,可以实时准确地完成完成流式计算,轻松实现CEP等功能,把批计算当成流计算的一种特例。
Flink像Spark一样,也可以部署到Yarn上,可以用HDFS作为分布式存储。
Kylin
大部分的大数据处理结果,是生成了报表供业务人员分析查阅,快速高效地生成报表就比较重要了。无论是hive还是Spark sql,通过计算生成报表的时间都在分钟级以上,Kylin对输入的hive表(组织成维度/度量的星形模型),预先通过MR进行计算,把计算结果以cube元数据的形式存到HBase里,然后用户可以通过JDBC Driver以sql的方式对数据进行快速查询。
Storm,Zookeeper,Pig,TiDB
Storm是第一代流处理框架,目前逐渐被spark streaming和Flink取代.
Zookeeper提供分布式协同服务,可以被用来做分布式服务的leader选取,主从自动切换等,大部分分布式集群框架都依赖ZooKeeper。
Pig类似Hive,使用Pig Latin语言写逻辑,翻译成MapReduce任务执行.
TiDB对标google的f1和spanner,支持acid,支持CAP理论中的C、P支持,但是也有高可用性。TIDB的使用场景是OLTP,也就是要替换传统的rdbms,比如Mysql。