随机森林如何做特征提取
转载自:https://www.cnblogs.com/xieb1994/p/9895450.html
随机森林做特征提取主要是根据:OOB(out of bag)原则去做的。
出发点:如果某个特征是重要的,那么当在此特征的数据分布式引入一定的噪声,那么用仅对此特征进行变化之后的数据进行RF训练,模型的性能应当会有较大的变化(较明显地变差);反之,如果某个特征是不重要的,则重新训练后的模型性能变化不大。
(1)计算每个特征的重要性程度
要进行特征选择,得有一个对特征好坏的度量,RF对于特征好坏的度量是基于
特征重要性: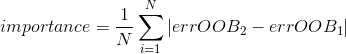
A. 对每一颗决策树,选择相应的袋外数据(out of bag,OOB)计算袋外数据误差,记为![]()
B. 随机对袋外数据OOB所有样本的特征X加入噪声干扰(可以随机改变样本在特征X处的值),再次计算袋外数据误差,记为![]() 。
。
C. 假设森林中有N棵树,则特征X的重要性为。
这个数值之所以能够说明特征的重要性是因为,如果加入随机噪声后,袋外数据准确率大幅度下降(即![]() 上升),说明这个特征对于样本的预测结果有很大影响,进而说明重要程度比较高。
上升),说明这个特征对于样本的预测结果有很大影响,进而说明重要程度比较高。
(2)特征选择过程
A. 计算每个特征的重要性,并按降序排序
B. 确定要剔除的比例,依据特征重要性剔除相应比例的特征,得到一个新的特征集
C. 用新的特征集重复上述过程,直到剩下m个特征(m为提前设定的值)
D. 根据上述过程中得到的各个特征集和特征集对应的袋外误差率,选择袋外误差率最低的特征集