ceph的实践
Ceph是最近开源系统中很火的一个项目,提供分布式存储服务,包括块存储RBD,对象存储RADOSGW和CephFS三种,基本覆盖了所有对存储的需求,所以越来越多企业加入到使用Ceph的行列。在国内也有越来越多的个人和企业参与到Ceph的研发中,贡献自己的力量。
Ceph系统的整体架构如下图所示:
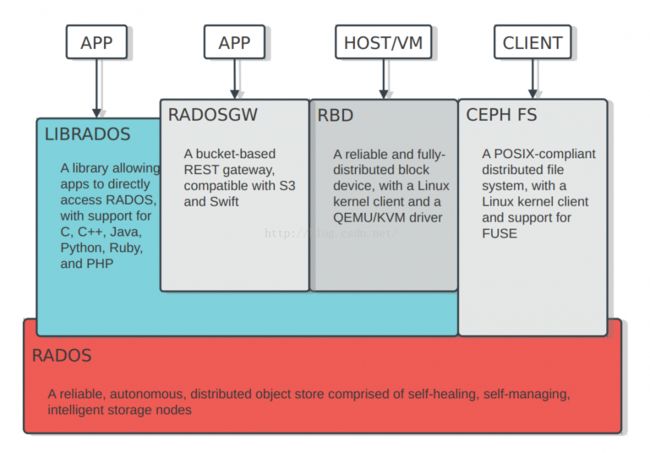
从设计最初,Ceph就考虑的比较周全,提供了一个分布式系统必须的三种特性:
1). 高扩展性
针对集群的扩容需求,Ceph通过两层Map机制来有效的隔离了集群扩容对上层client的影响,提供了很高的扩展性。我们可以利用大量的低配置设备轻松的搭建出PB甚至EB级的存储系统。
2). 高可靠性
针对数据的安全可靠,Ceph会在存储集群中同时存储同一数据的多个副本(或者其他类型的冗余,例如erasure code),来保证在某些设备故障后,用户存入的数据还可用,针对用户不同的高可用需求,Ceph可以很方便的设置Pool的数据冗余规则,另外通过Ceph Crushmap,用户也可以方便的设置各个备份之间存储位置的逻辑关系,比如达到多个副本跨机房、跨机架、跨机器等目的。
3). 高性能
Ceph中通过文件切分和CRUSH算法,保证数据chunk分布基本均衡,同时Ceph的无元数据信息的设计(CephFS除外),保证了Client可以通过固定算法确定数据的位置信息,提供了非常高的并行化IO性能。
总之,作为一个完善的分布式存储系统,Ceph给了用户足够多的配置选项来定制话自己的存储系统。
我们公司是一家专注于为创客和行业客户提供云计算服务的公司,技术上我们选择了openstack+ceph的架构,绝大部分openstack的数据都依靠Ceph系统提供存储服务,在应用实践中,针对我们自己的系统架构和机房部署,我们对Ceph也进行了部分调优和优化,达到了我们的应用需求。
Ceph存储在我们公司的应用可以分为如下几种:
- RBD服务
1) Glance镜像存储
2) Nova instance数据存储
3) Cinder volume存储
4) Backup服务
把Openstack的Glance组件image和Nova instance数据一起存储到Ceph集群中,可以很好的避免Openstack创建虚拟机时的image复制,并且利用Ceph RBD的snapshot功能,基本可以实现秒级创建Nova instance。
同样利用RBD的snapshot功能,可以有效的减少Cinder Volume,Nova instance的备份创建时间和空间占用。
整个应用场景如下图所示:
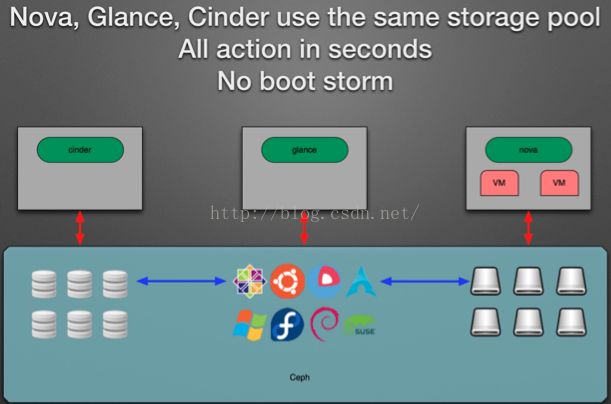
- CephFS提供服务器间数据共享
在我们的生产环境中,遇到过服务器间共享数据的需求。之前的思路可以通过NFS来实现,现在基于CephFS,可以轻松的满足需求。虽说我们用的版本Hammer中,Ceph官方没说CephFS完善到可用于生产环境,但也是经过大规模测试后的版本,据说在雅虎也有大规模使用的集群,另外我们共享的数据对可靠性没那么大要求,IO量也不是很大,所以CephFS已经能很好的满足我们的需求了。
最近Ceph发布的JEWEL版本是官方声称的第一个CephFS稳定版本,如果对CephFS有强烈需求的话,可以部署最新的JEWEL版本。
- RADOSGW提供RDS数据备份存储
RDS服务是我们公司提供的一项MySQL服务,我们保证了MySQL的高可用和性能,用户只需创建自己的RDS服务即可使用,而不用麻烦的自己搭建MySQL服务并配置其高可用等特性。
在RDS服务中,用户会有创建MySQL备份的需求,而这种备份是最适合对象存储的,我们自己实现了RDS的S3备份接口,把RDS的备份数据上传到兼容S3的RADOSGW中。这样使用统一的Ceph系统,我们就不需要再搭建一套Swift对象存储系统了,简化了公司的运维成本。
- Ceph的优化
我们前面说过,Ceph提供了很多的配置参数来允许用户订制自己的分布式存储系统,在赋予用户这个便利性的同时,也意味着如果用户想获取自己系统的最大性能时,必须自己进行分析调优。
Ceph是一个复杂的系统,官方的默认配置能保证系统基本运行,但是不能贴合用户实际需求,达到最大化用户物理系统性能的要求。虽说现在也已经有了一些朋友分享Ceph的配置参考和调优,但对每个用户来说都不是拿来主义。他们只是提供了一种优化的参考,具体的效果如何还需要用户贴合自己的实际测试结果来调整。
对于我们公司来说,我们的物理机配置是相当前卫的,所以在参考网上朋友的Ceph配置和调优参数后,我们也做了自己的独特优化,对比各种调优项后,很好的达到我们的要求。
依据我们的经验,可以在以下几个方面做Ceph的性能调优:
1). BIOS设置:Hyper-Threading,关闭节能
2). Linux参数调优,包括manx pid,SATA/SSD IO Scheduler,read ahead
3). fd cache,omap header cache
4). filestore queue,object size
5). osd theread,journal queue
6). crushmap优化
7). xfs mount option
- Ceph的监控
对于一个大型系统来说,完善的监控很重要,我们不可能时刻靠人工来发现系统的问题。针对Ceph系统,我们调研了很多种方案,最后选择了适合我们的,方便我们扩展的一种。即:Diamond + Graphite + Grafana
1). Diamond是一个客户端性能收集工具,Python编写,易与扩展。
2). Graphite是一个Python编写的企业级开源监控工具,采用django框架。
3). Grafana是功能齐全的度量仪表盘和图形编辑器,支持Graphite,InfluxDB和OpenTSDB。
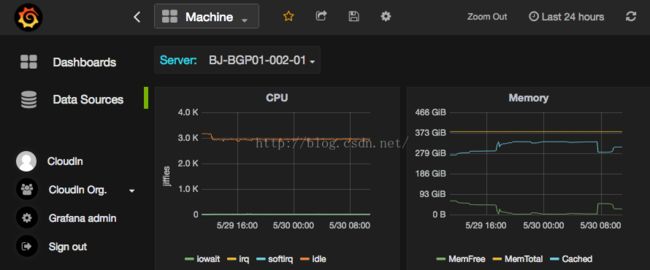
部署后,我们可以在Grafana的前端订制我们自己的监控项,类似下图:
总之,Ceph是一个大型的完善的分布式系统,对它的研究和优化是一个持续的过程,在后续我们会继续深入研究Ceph系统,学习其精髓,优化其应用,也会继续分享我们的心得。