EAST解读 —— An Efficient and Accurate Scene Text Detector
文章目录
- 简述
- 现有工作问题
- 数据集
- 网络结构
- 特征提取层
- 特征合并层
- 结果输出层
- 标签生成
- 损失函数
- 文本分割Loss
- RBOX边界偏移Loss
- RBOX偏移角度损失
- QUAD偏移Loss
- Locality-Aware NMS
- 实验结果
- References
简述
EAST是旷视科技CVPR 2017年的一篇场景文本检测算法,其特点有:结构简单,速度快,端到端等,Github上有很好的复现代码,是一种实用性很强的文本检测算法。
- paper:https://arxiv.org/abs/1704.03155
- code(tesorflow):https://github.com/argman/EAST
- code(pytorch):https://github.com/songdejia/EAST
EAST的名字取自“Efficient and Accurate Scene Text”,其可以用来检测任意大小,任意方向(水平和倾斜)的文本。其主要实现思路为:FCN网络 + Locality-Aware NMS。该算法抛弃了很多不必要的中间步骤,实现了端到端的训练和优化:FCN直接进行预测和回归,除了“Thresholding&NMS”外无其他后处理环节(如候选区域聚合和单词分割等)。
现有工作问题

如上图,本文总结了现有一些方法的工作流(a-d),大多数由多个阶段组成,而且一些结构产生中间结果,并不是端到端的,因此这些现有方法大多数速度不快,并且也没办法达到很好的精度(Sub-optimal)。本文设计了一种两阶段场景文本检测模型EAST(e),其主要贡献有:
- 提出一种基于FCN的模型EAST,该模型只需要两阶段(全卷积网络和NMS),就可以完成场景文本检测的任务,全程端到端结构;
- 该框架具有很好的灵活性,能够生成水平矩形框(Axis-align Bounding Box, AABB),旋转矩形框(Rotated Box, RBOX)和任意四边形(Quadrangle, QUAD)几种预测。
- 文章在ICDAR2015,COCO-Text,MSRA-TD500上测试,效果达到了State-of-the-art,在ICDAR2015上的F-score值达到0.7820,超出现有方法许多。
数据集
目前场景文本检测有众多数据集,不同语言,场景,拍摄设备等,比较著名的有以下几个数据集:
- ICDAR 2015
- COCO-Text
- MSRA-TD500
这几个数据集都是比较常用的,使用1)旋转矩形框2)任意四边标注,但是也有一些数据集拥有更加灵活的标注,如曲线形状文字等,可以用于更加精细的算法:
- Total-Text
- SCUT-CTW1500
网络结构
EAST的网路结构如下:

这里简单把EAST的整个网络结构分为三个层:特征提取层、特征合并层、结果输出层。
特征提取层
EAST主要基于U-Net,其主干网络Encoder使用PVANet或者VGG,使用PVANet的主要原因是增加感受野(相对于VGG来说),使其有利于检测长文本。关于U-Net,大家可自行搜索查阅。
特征合并层
利用U-shape的思想逐渐合并不同尺度的特征图,目的是解决文本行尺度变换剧烈的问题。具体做法请参考EAST的网络结构图或查阅U-Net的资料。
在特征合并部分,逐步之前得到的不同大小的feature map,在每一个合并阶段,从上一个阶段来的特征图最先进行unpooling,来增大特征图的大小,然后与当前特征图concate(就是通道数串联)。然后,利用一个 1 ∗ 1 1*1 1∗1的卷积层减少通道数并减少计算量,接着是一个 3 ∗ 3 3*3 3∗3的卷积层将信息融合,最终产生本合并阶段的结果。在最后一个合并阶段之后,利用一个 3 ∗ 3 3*3 3∗3卷积层产生最终的合并部分的特征图,并将其输入到输出层。其计算公式如下:

结果输出层
再来说一下输出层的几个特征图(score map + geometry map),上图最右边蓝色部分:
- 对于检测形状为RBOX,则输出包含文本得分(score map)和文本形状(AABB boundingbox 和rotate angle),也就是一起有6个输出,这里AABB分别表示相对于top, right, bottom, left边的偏移。
- 对于检测形状为QUAD,则输出包含文本得分(score map)和文本形状(8个相对于corner vertices的偏移),也就是一起有9个输出,其中QUAD有8个,分别为 ( Δ x i , Δ y i ) , i ⊂ [ 1 , 2 , 3 , 4 ] (\varDelta x_i, \varDelta y_i), i\subset[1,2,3,4] (Δxi,Δyi),i⊂[1,2,3,4]。
注:RBOX和QUAD二者选一,一般RBOX的效果会略好。
下表中阐明了每个通道的作用:(AABB部分没有在图中画出来,其实AABB就是RBOX的 θ = 0 \theta=0 θ=0的情况)

标签生成
接下来解释具体每一个通道的标签(GT)的生成方法,我们以RBOX为例,以下是RBOX的学习目标生成过程:

- 对于任意四边形标注,向内缩小一些(文中用的0.3倍)并生成分割Mask(如图b)。
- 对于每个在Mask中的点(注意只考虑positive pixel!!),产生4个回归坐标,分别为该点到AABB(axis-aligned bounding box)四条边的距离偏移(d1, d2, d3, d4)。
- 对于每个在Mask中的点(还是只考虑positive pixel!!),产生一个矩形框旋转角度 θ \theta θ。
如果是任意四边形目标,8个坐标分别是任意四边形的四个顶点到该点的距离偏移。
注意:label的四点标注要求按顺时针方向给出,参见ICDAR 2015的数据标注方式即可。
损失函数
文章对于不同的子任务使用不同的损失函数,对于RBOX来说,主要任务包括文字置信度回归(得到score map),边框偏移回归(geometry map)以及角度偏移回归( θ \theta θ map)。
网络的总损失函数为:

文本分割Loss
不同于常见目标检测网络应对样本不平衡的方法,如均衡采样,OHEM等。EAST算法采用了类平衡交叉熵来解决类别不平衡的问题。(文中说采用OHEM等会带来部分stage不可导和需要调更多超参的问题,这会让模型会更复杂)
对于文字置信度回归(生成score map的loss),文章使用了类别加权的Cross Entropy来计算,如下:

其中使用β加权,权重由正负例比例决定,比例越小,权重越大。但是在具体实战中,一般采用dice loss,因为它的收敛速度会比类平衡交叉熵快。
RBOX边界偏移Loss
对于RBOX而言,边界偏移Loss使用了IoU损失:(文本在自然场景中的尺寸变化极大,直接使用L1或者L2损失去回归文本区域将导致损失偏差更倾向于检测大文本。因此论文在RBOX回归时(AABB部分)采用IoU损失,在QUAD回归时采用尺度归一化的smoothed-L1损失,以此来保证几何形状的回归损失是尺度不变的。)

RBOX偏移角度损失
RBOX还有一个角度,这里使用余弦loss:

以上公式中hat均表示预测,”*“均表示GT。所以:

文中 λ θ \lambda_\theta λθ被设置为了10。
QUAD偏移Loss
对于任意四边形QUAD而言,边界loss则使用了SmoothL1Loss作为损失函数:

其中使用 N Q ∗ N_Q{^*} NQ∗作为归一化参数,表示该四边形的最短边的长度:
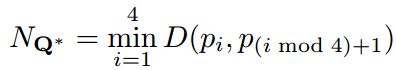
Locality-Aware NMS
局部感知NMS,为了减少时间复杂度。
其基于假设:基于相邻像素点的候选框是高度相关的。所以可以先对这些候选框进行逐步合并,再做常规NMS。
使用以上的训练结束以后,对于每一个点,如果他的score值大于一定阈值,我们就可以认为这个点在某个文字的内部,然后取其偏移,角度等就可以计算出该框所在的位置,大小等。 这么多框,自然是需要做一些去重操作,传统的NMS对于每一个Box都会和其余的所有box计算IoU,这样做的框数量非常大,因此O(n2)的速度接受不了。但是基于以上的方法(EAST)预测出来的框其实是比较有特点的:邻近的像素生成的框重合度都很高,但是不是同一个文本生成的检测框,重合度都很小,因此本文提出先按行“合并”四边形,最后再把剩下的四边形用原始的NMS筛选,这样可以大大降低NMS的时候计算IoU的数量,即Locality-Aware NMS:(局部感知NMS)

实验结果
文本在ICDAR2015数据集上做了一些实验,对比其他方法,本文提升较大:

有问题欢迎交流!
done~
References
- https://arxiv.org/abs/1704.03155
- https://zhuanlan.zhihu.com/p/37504120
- http://blog.prince2015.club/2018/12/16/EAST/
- https://zhuanlan.zhihu.com/p/44364958
- https://blog.csdn.net/Lancher_Mo/article/details/77937499
- https://blog.csdn.net/attitude_yu/article/details/80724187