IntelliJ IDEA构建基于maven的spark+hbase工程(scala语言)
摘要
利用IDEA来编写基于maven的scala程序,主要功能用来支持从hbase中拉取数据供spark进行mapreduce运算。
软件准备
首先下载安装IntelliJ IDEA
https://www.jetbrains.com/idea/download/#section=windows
不需要javaee支持的话,直接选择Community版本就行了,毕竟免费,也足够支持maven,scala,git,spark,hbase了。
安装过程中选择scala支持
安装完成后,配置全局的maven,指定自己安装的maven也可以使用idea默认自带maven。
工程构建
新建maven project,类似eclipse的simple project,不需要其他附属,scala支持后续添加
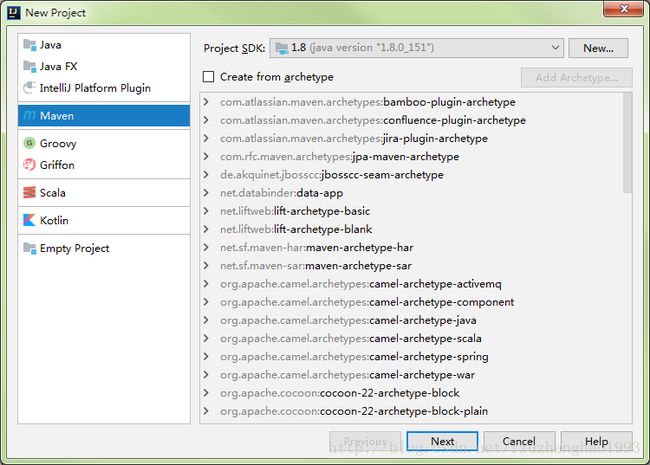
新工程删除java文件夹,新建scala文件夹。
配置pom,因为需要编译scala,所以plugin选择maven-scala-plugin
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.testgroupId>
<artifactId>LdSparkHbaseartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<jdk.version>1.8jdk.version>
<logback.version>1.1.2logback.version>
<slf4j.version>1.7.7slf4j.version>
<junit.version>4.11junit.version>
<spark.version>2.1.0spark.version>
<hadoop.version>2.6.5hadoop.version>
<hbase.version>1.2.6hbase.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>${hbase.version}version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>${hbase.version}version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbaseartifactId>
<version>${hbase.version}version>
<type>pomtype>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<version>2.15.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>3.1.0version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<createDependencyReducedPom>falsecreateDependencyReducedPom>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.test.SparkCountmainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>工程右键,选择add framwork support,在打开的选项中添加scala支持
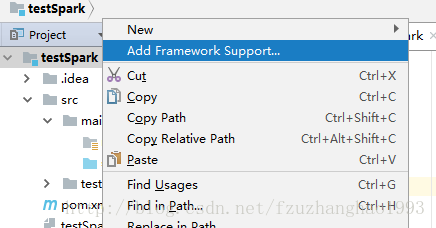
先看看工程能不能用,建议新建一个hello work类,run一下,看看工程构建是否正常。
新建SparkCount类,这里遍历采用官方demo,mapreduce自己修改
SparkCount
package com.test
import org.apache.hadoop.hbase.{HBaseConfiguration, HTableDescriptor, TableName}
import org.apache.hadoop.hbase.client.HBaseAdmin
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.spark._
import org.apache.hadoop.hbase.client.HTable
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.mapred.JobConf
import org.apache.hadoop.io._
object SparkCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("spark://testserverip:7077")
.setAppName("reduce")
val sc = new SparkContext(sparkConf)
val tablename = "apos_status"
val conf = HBaseConfiguration.create()
//设置zooKeeper集群地址,也可以通过将hbase-site.xml导入classpath,但是建议在程序里这样设置
conf.set("hbase.zookeeper.quorum", "localhost")
//设置zookeeper连接端口,默认2181
conf.set("hbase.zookeeper.property.clientPort", "2181")
conf.set(TableInputFormat.INPUT_TABLE, tablename)
conf.set(TableInputFormat.SCAN_COLUMNS, "apos:type")
//读取数据并转化成rdd
val hBaseRDD = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
val count = hBaseRDD.count()
println(count)
hBaseRDD.foreach { case (_, result) => {
//获取行键
val key = Bytes.toString(result.getRow)
//通过列族和列名获取列
val typenames = Bytes.toString(result.getValue("apos".getBytes, "type".getBytes))
if (key != null && typenames != null) {
println(key + ":" + typenames);
}
}
}
println("map begin");
val result = hBaseRDD.map(tuple=>Bytes.toString(tuple._2.getValue("apos".getBytes, "type".getBytes))).map(s=>(s,1)).reduceByKey((a,b)=>a+b)
println("map end");
//最终结果写入hdfs,也可以写入hbase result.saveAsTextFile("hdfs://localhost:9070/user/root/aposStatus-out")
//也可以选择写入hbase,写入配置
var resultConf = HBaseConfiguration.create()
//设置zooKeeper集群地址,也可以通过将hbase-site.xml导入classpath,但是建议在程序里这样设置
resultConf.set("hbase.zookeeper.quorum", "localhost")
//设置zookeeper连接端口,默认2181
resultConf.set("hbase.zookeeper.property.clientPort", "2181")
//注意这里是output
resultConf.set(TableOutputFormat.OUTPUT_TABLE, "count-result")
var job = Job.getInstance(resultConf)
job.setOutputKeyClass(classOf[ImmutableBytesWritable])
job.setOutputValueClass(classOf[org.apache.hadoop.hbase.client.Result])
job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
val hbaseOut = result.map(tuple=>{
val put = new Put(Bytes.toBytes(UUID.randomUUID().toString))
put.addColumn(Bytes.toBytes("result"), Bytes.toBytes("type"), Bytes.toBytes(tuple._1))
//直接写入整型会以十六进制存储
put.addColumn(Bytes.toBytes("result"), Bytes.toBytes("count"), Bytes.toBytes(tuple._2+""))
(new ImmutableBytesWritable, put)
})
hbaseOut.saveAsNewAPIHadoopDataset(job.getConfiguration)
sc.stop()
}
}
打包运行
打包工程
如果没有显示maven projects导航栏,可以直接搜索
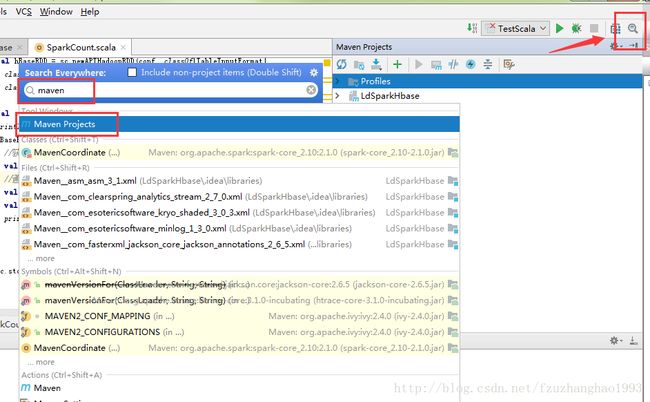
双击构建,也可右键选择构建

构建成功,上传到服务器运行测试

运算结果

count,foreach,mapreduce三个操作合计
![]()