【决策树】ID3算法理解与R语言实现
一、算法理解
想来想去,还是决定用各大畅销书中的相亲例子来解释什么叫决策树。

简单来说,决策树就是根据各种变量,作为输入条件,最终输出决策的过程。比如上图中女方在相亲过程中,影响是否见男方的变量有年龄、长相、收入、是否是公务员等。
最终在各种变量组合下,最终输出见或不见的决策。
下边是决策树的一种定义:
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
二、数学公式
对于决策树有大体认识后,我们来讨论其背后的包含的数学理论支撑,主要是信息论中的信息。为了理解,我们需要了解两个数学概念。
信息熵:熵是无序性(或不确定性)的度量指标。假如事件A的全概率划分是(A1,A2,...,An),每部分发生的概率是(p1,p2,...,pn),那信息熵的公式如下:
![]()
信息增益:
简单来说,就是在某种变量算出其相应的信息熵后,用总体信息熵减去,即为该变量的信息增益。比如,我们算出见与不见总体的信息熵,减去年龄变量的信息熵,即为信息增益,Gain(x)。
一般我们选择信息增益最大的变量进行节点划分,这样能快速对决策树进行分叉,并且保证决策树的高度最小。
举例说明:
在某社区中,我们根据某用户的用户博客密度,好友密度、是否使用真实头像来判断该用户是真人还是机器人。
具体的数据如下:
| 日志密度 | 好友密度 | 是否真实头像 | 账号是否是真实的 |
| s | s | no | no |
| s | l | yes | yes |
| l | m | yes | yes |
| m | m | yes | yes |
| l | m | yes | yes |
| m | l | no | yes |
| m | s | no | no |
| l | m | no | yes |
| m | s | no | yes |
| s | s | yes | no |
很明显,我们需要判别的分类变量为账号是否是真实的。于是,我们计算该变量的信息熵为:
![]()
0.7代表上述训练集中,账号为真的概率为0.7,账号为假的概率为0.3
下面,我们再计算一下日志密度(简称L)变量的信息熵:
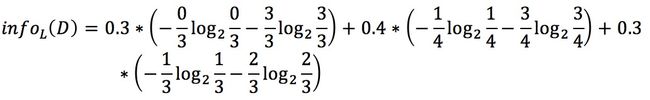
第一个0.3代表日志密度为L的概率为0.3,括号中0/3 代表在日志密度为L的情况下,账号为假的概率为0/3 ,后边的3/3代表在日志密度为L的情况下,账号为真的概率为3/3.
0.4代表日志密度为M的概率为0.4,括号中1/4 代表在日志密度为M的情况下,账号为假的概率为1/4 ,后边的3/4代表在日志密度为L的情况下,账号为真的概率为3/4.
0.3代表日志密度为S的概率为0.3,括号中2/3代表在日志密度为S的情况下,账号为假的概率为2/3 ,后边的1/3代表在日志密度为L的情况下,账号为真的概率为1/3.
在计算其它变量的信息熵时,也是这个逻辑,这里不再赘述,最终算得:
总体的信息熵为:0.879
日志密度L的信息熵为:0.603 ,信息增益Gain(L) = 0.879-0.603=0.276。
同理,好友密度的信息增益为0.553。真实头像的信息增益为0.033。
我们以信息增益最大的变量作为初始的分支判断条件。
------------------
其实,不管算哪个变量的熵值,都是在以决策结果变量为维度算,只不过限制在了某个变量等于特定值的子集中去算了。
如果一个变量在某种取值下,决策变量的取值也唯一(在上例子中,好友密度为M的情况下,是真实账号的情况权威yes),这时候该变量在该取值下的信息熵为0,
我们称该节点的纯度较高。
我们选择纯度高、信息熵高的变量,因为拿这种变量进行划分,最能直接将树节点分分开。
可以通过下边的R语言自定义函数中的熵值计算函数以及决定用哪个变量拆分函数来理解这个道理。
三、用R语言自带包实现算法
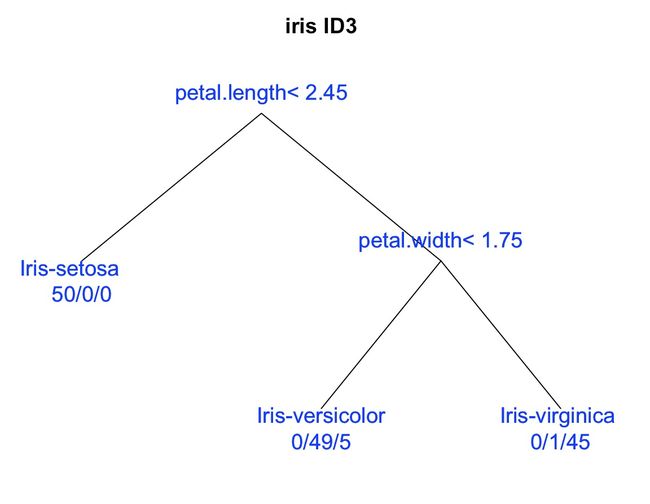
用R中的Rpart包实现iris数据集分类的代码:
SNS<-read.csv("./DataSource/SNS.data.csv")
library(rpart)
#使用rpart包并传参数
iris.rp<-rpart(class~.,data = iris,method = "class")
#画图
plot(iris.rp,uniform = T,branch = 0,margin = 0.1,main="iris ID3")#http://f.dataguru.cn/thread-121228-1-1.html
text(iris.rp,use.n = T,col="blue",cex=1.2) #use.n 是控制下边50/0/0样本分类概况,col字体颜色、cex 字体大小
#用fancyRpartPlot画图,但是rattle包总是安装失败以下是输出结果:
四、用R语言自定义函数实现算法
#用R语言实现决策树ID3算法,以iris数据集为例
#计算总体信息值的函数,这里只允许最后一列作为决策结果列
info<-function(dataSet){
rowCount=nrow(dataSet) #计算数据集中有几行,也即有几个样本点
colCount=ncol(dataSet)
resultClass=NULL
resultClass=levels(factor(dataSet[,colCount])) #此代码取得判别列中有个可能的值,输出 "Iris-setosa" "Iris-versicolor" "Iris-virginica"
classCount=NULL
classCount[resultClass]=rep(0,length(resultClass)) #以决策变量的值为下标构建计数数组,用于计算和存储样本中出现相应变量的个数
for(i in 1:rowCount){ #该for循环的作用是计算决策变量中每个值出现的个数,为计算信息值公式做准备
if(dataSet[i,colCount] %in% resultClass){
temp=dataSet[i,colCount]
classCount[temp]=classCount[temp]+1
}
}
#计算总体的信息值
t=NULL
info=0
for (i in 1:length(resultClass)) {
t[i]=classCount[i]/rowCount
info=-t[i]*log2(t[i])+info
}
return(info)
}
#拆分数据集,此函数的作用在于对于每列自变量,按照其包含的类别值将原始数据集按行拆分,以便在这个子集中计算特定自变量的熵值
splitDataSet<-function(originDataSet,axis,value){#含义即从originDataSet数据集中拆分出第axis个变量等于value的所有行,合并成子集
retDataSet=NULL
for (i in 1:nrow(originDataSet)) { #循环原始数据集所有行
if(originDataSet[i,axis]==value){ #限制特定自变量,遇到目标值则记录下原始数据集整行,然后rbind行连接
tempDataSet=originDataSet[i,]
retDataSet=rbind(tempDataSet,retDataSet)
}
}
rownames(retDataSet)=NULL
return(retDataSet) #返回针对某个自变量的值筛选后的子集
}
#选择最佳拆分变量
chooseBestFeatureToSplita<-function(dataSet){
bestGain=0.0
bestFeature=-1
baseInfo=info(dataSet) #计算总的信息熵
numFeature<-ncol(dataSet)-1 #计算除决策变量之外的所有列,即为自变量个数
for (i in 1:numFeature) {#对于每个自变量计算信息熵
featureInfo=0.0
Feature=dataSet[,i]#定位到第i列
classCount=levels(factor(Feature)) #计算第i列中变量类别,即有几种值
for (j in 1:classCount) {
subDataSet=splitDataSet(dataSet,i,Feature[j]) #将dataSet中第i个变量等于Feature[j]的行拆分出来
newInfo=info(subDataSet) #计算该子集的信息熵,也就是计算该变量在该取值下的信息熵部分
prob=length(subDataSet[,1]*1.0)/nrow(dataSet)# 这里计算该变量等于Feature[j]的情况在总数据集中出现的概率
featureInfo=featureInfo+prob*newInfo #不不断将该变量下各部分信息熵加总
} #第第i个变量的信息熵计算结束
infoGain=baseInfo-featureInfo
if(infoGain>bestGain){ #
bestGain=infoGain
bestFeature=i
}
}# 所有所有变量信息熵计算结束,并且得出了最佳拆分变量
return(bestFeature) #返回最佳变量值
}
#最终判断属于哪一类的条件
majorityCnt <- function(classList){
classCount = NULL
count = as.numeric(table(classList))
majorityList = levels(as.factor(classList))
if(length(count) == 1){
return (majorityList[1])
}else{
f = max(count)
return (majorityList[which(count == f)][1])
}
}
#判断剩余的值是否属于同一类,是否已经纯净了
trick <- function(classList){
count = as.numeric(table(classList))
if(length(count) == 1){
return (TRUE)
}else
return (FALSE)
}
#递归生成树
createTree<-function(dataSet){
decision_tree = list()
classList = dataSet[,length(dataSet)]
#判断是否属于同一类
if(trick(classList))
return (rbind(decision_tree,classList[1]))
#是否在矩阵中只剩Label标签了,若只剩最后一列,则都分完了
if(ncol(dataSet) == 1){
decision_tree = rbind(decision_tree,majorityCnt(classList))
return (decision_tree)
}
#选择最佳属性进行分割
bestFeature=chooseBestFeatureToSplita(dataSet)
labelFeature=colnames(dataSet)[bestFeature] #获取最佳划分属性的变量名
decision_tree=rbind(decision_tree,labelFeature) #这里rbind方法,如果有一个变量列数不足,会自动重复补齐
t=dataSet[,bestFeature]
temp_tree=data.frame()
for(j in 1:length(levels(as.factor(t)))){
#这个标签的两个属性,比如“yes”,“no”,所属的数据集
dataSet = splitDataSet(dataSet,bestFeature,levels(as.factor(t))[j])
dataSet=dataSet[,-bestFeature]
#递归调用这个函数
temp_tree = createTree(dataSet)
decision_tree = rbind(decision_tree,temp_tree)
}
return (decision_tree)
}
t<-createTree(iris)
以上代码及问题说明请访问我的github:https://github.com/HelloMrChen/AlgorithmPractise-R