利用税务数据分析美国人群收入情况
一、案例描述:
本案例数据集中记录了从过去大约100年内全球各国高收入信息,通过这些信息我们能分析群人的收入变化情况,以及专注在美国的各个收入阶层之间的差别关系。本案例集的下载地址为:
https://old.datahub.io/dataset/world-top-incomes-database二、相关代码:
#coding=utf-8
import numpy as np
import matplotlib as plt
import matplotlib.pyplot as plt
import csv
data_file="income_dist.csv"
#过滤出特定的国家
def dataset(path,Country="United States"):
with open(data_file,'r') as csvfile:
reader=csv.DictReader(csvfile)
for row in filter(lambda row:row["Country"]==Country,reader):
yield row
#创建时间序列
def timeseries(data,column):
for row in filter(lambda row:row[column],data):
yield (int(row["Year"]),row[column])
#对matplotlib进行包装,传参进行
def linechart(series,**kwargs):
fig=plt.figure()
ax=plt.subplot(111)
for line in series:
line=list(line)
xvals=[v[0] for v in line]
yvals=[v[1] for v in line]
ax.plot(xvals,yvals)
if 'ylabel' in kwargs:
ax.set_ylabel(kwargs['ylabel'])
if 'title' in kwargs:
plt.title(kwargs['title'])
if'labels'in kwargs:
ax.legend(kwargs.get('labels'))
return fig
def percent_income_share(source):
column={
"Top 10% income share",
"Top 5% income share",
"Top 1% income share",
"Top 0.5% income share",
"Top 0.1% income share"
}
source=list(dataset(source))
return linechart([timeseries(source,col) for col in column],
labels=column,
title="U.S Percentage Income Share",
ylabel="Percentage")
# percent_income_share(data_file)
# plt.show()
#计算各个阶层收入的中位数并且作图
def normalizes(data):
data=list(data)
norm=np.array(list(d[1] for d in data),dtype="f8")
mean=norm.mean()
norm/=mean
return zip((d[0]for d in data),norm)
def norm_percent_income_share(source):
column={
"Top 10% income share",
"Top 5% income share",
"Top 1% income share",
"Top 0.5% income share",
"Top 0.1% income share"
}
source=list(dataset(source))
return linechart([normalizes(timeseries(source,col)) for col in column],
labels=column,
title="U.S Percentage Income Share",
ylabel="Percentage")
# norm_percent_income_share(data_file)
# plt.show()
#不同收入组的各年平均收入,并且进行绘图
def average_income(source):
column={
"Top 10% average income",
"Top 5% average income",
"Top 1% average income",
"Top 0.5% average income",
"Top 0.1% average income"
}
source=list(dataset(source))
return linechart([timeseries(source,col)for col in column],labels=column,title="U.S Average Income",
ylabel="2008 US Dollars")
# average_income(data_file)
# plt.show()
#堆积图来分析富裕人群
def stackedarea(series,**kwargs):
fig=plt.figure()
axe=fig.add_subplot(111)
fnx=lambda s:np.array(list(v[1] for v in s),dtype="f8")
yax=np.row_stack(fnx(s) for s in series)
xax=np.arange(1917,2008)
polys=axe.stackplot(xax,yax)
axe.margins(0,0)
if 'ylabels'in kwargs:
axe.set_ylabel(kwargs['ylabel'])
if 'labels' in kwargs:
legendProxies=[]
for poly in polys:
legendProxies.append(plt.Rectangle(0,0),1,1,
fc=poly.get_factor()[0])
axe.legend([legendProxies,kwargs.get('labels')])
if 'title' in kwargs:
plt.title(kwargs['title'])
return fig
def income_composition(source):
column=("Top 10% average income",
"Top 5% average income",
"Top 1% average income",
"Top 0.5% average income",
"Top 0.1% average income"
)
source=list(dataset(source))
labels=("Salary","Dividends","Internet","Rent","Business")
return stackedarea([timeseries(source,col)for col in column],labels=labels,title="U.S. Top 10% Income Composition",ylabel="Percentage")
income_composition(data_file)四、本次案例输出结果展示
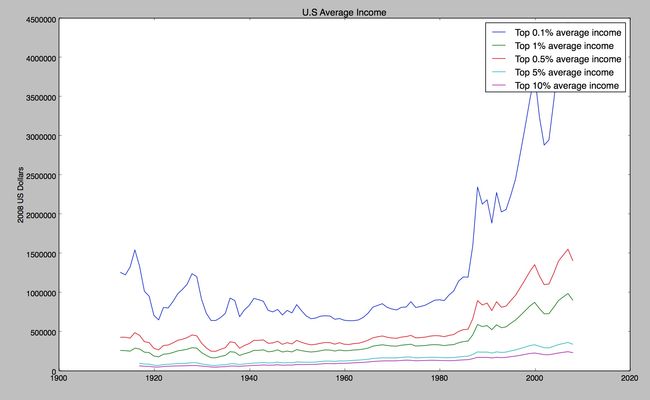
这简直就是贫富差距拉大的佐证啊。