基于用户的协同过滤算法在显式、隐式反馈数据中的评估比较
目录
一、问题描述
二、算法描述
三、评价指标
四、实验结果
五、总结
一、问题描述
实现基于用户的协同过滤(UserCF)算法,以TopN的推荐方式,分别在显式和隐式反馈数据集中进行评估和比较。
实验采用Grouplens团队提供的公开数据集Movielens-latest-small,包括671个用户对9125部电影的100004条评分,并将数据以6比2的比例随机分为训练集和测试集。
隐式反馈只考虑用户是否看过电影,显式反馈考虑用户对电影的评分。
二、算法描述
UserCF算法是一种基于统计学的方法,目标是通过分析用户的历史行为,为用户推荐和他相似的用户喜欢的物品,因此算法中的一个重要内容便是计算用户的相似度。
UserCF算法中相似度的计算是一种近邻模型,中心思想是通过寻找k个近邻用户来模拟主体的行为(KNN),寻找近邻用户需要一个指标来衡量用户间近邻程度,简易的计算方法如下(给定用户u和用户v,N(u)表示用户u喜欢的物品集合,N(v)表示用户v喜欢的物品集合):
1. 杰卡德相似度

2. 余弦相似度

算法步骤:
1. 读取数据,建立用户 – 物品数据结构,如下图所示:

用户A喜欢物品a、b、c,用户B喜欢物品a、c,以此类推。
2. 建立物品 – 用户倒排表,如下图所示。目的是在计算相似度时排除那些![]() 的数据,只需要扫描倒排表就可以计算出
的数据,只需要扫描倒排表就可以计算出![]() 的用户组合。
的用户组合。

3. 利用余弦相似度构建相似度矩阵,如用户A和用户B的相似度计算如下:
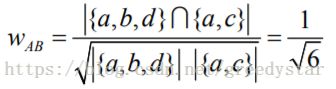
4. 寻找K近邻相似用户。
5. 计算用户评分,w表示用户相似度,r表示用户的反馈评分。
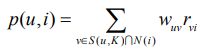
6. 得出TopN推荐列表。
三、评价指标
通过计算选取不同近邻用户K值时的准确率、召回率和F1值对算法进行评估。
准确率、召回率和F1值的定义请参考推荐系统发展综述 - 4.推荐方式和效果评估
四、实验结果
实验结果中的
实验结果中TopN的N值为选取的用户相似度较大的N个用户作为近邻用户,非最终推荐列表的TopN。
1. 隐式反馈

从图中可以看到,当N取18时,F1值最大为0.15,此时召回率为0.23,准确率为0.1,可以看出仅考虑隐式反馈时,通过UserCF算法得到的推荐列表结果并不是很理想。
2. 显式反馈
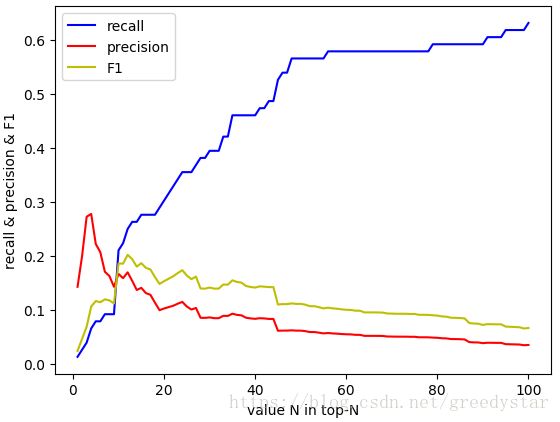
当N取16时,F1值最大为0.2,此时召回率为0.27,准确率为0.17,相比较隐式反馈结果有所提升。
随着N的增大,显式和隐式反馈数据推荐结果的召回率逐渐上升,这是因为所选择的近邻用户越多,为用户推荐的物品就越多,因此召回率会大大增加,而相反,准确率则会逐渐下降。
五、总结
UserCF算法是通过统计学的方法来挖掘用户历史行为数据的规律,隐式反馈数据中所体现的用户行为规律较为粗糙,不利于发现和挖掘,而显示反馈数据能够对用户的行为进行一定的偏好划分,更具有代表性。
因此协同过滤算法通常考虑显式反馈数据,最直观的显式反馈数据是评分数据,常用在音乐、视频服务推荐中。电商平台中的浏览、收藏、加入购物车、购买等行为也可以体现出不同层面的用户偏好,比如购买代表的偏好程度最高,浏览代表的最低,以此分级也可作为显式反馈数据。
参考:项亮. 推荐系统实践[M]. 北京: 人民邮电出版社, 2012.