network namespace 是实现网络虚拟化的重要功能,它能创建多个隔离的网络空间,它们有独自的网络栈信息。不管是虚拟机还是容器,运行的时候仿佛自己就在独立的网络中。这篇文章介绍 network namespace 的基本概念和用法,network namespace 是 linux 内核提供的功能,这篇文章借助ip 命令来完成各种操作。ip 命令来自于iproute2 安装包,一般系统会默认安装,如果没有的话,请读者自行安装。
NOTE:ip 命令因为需要修改系统的网络配置,默认需要 sudo 权限。这篇文章使用 root 用户执行,请不要在生产环境或者重要的系统中用 root 直接执行,以防产生错误。
ip 命令管理的功能很多, 和 network namespace 有关的操作都是在子命令ip netns 下进行的,可以通过 ``ip netns help` 查看所有操作的帮助信息。
默认情况下,使用 ip netns 是没有网络 namespace 的,所以 ip netns ls 命令看不到任何输出。
[root@localhost ~]# ip netns help
Usage: ip netns list
ip netns add NAME
ip netns delete NAME
ip netns identify PID
ip netns pids NAME
ip netns exec NAME cmd ...
ip netns monitor
[root@localhost ~]# ip netns ls
创建 network namespace 也非常简单,直接使用 ip netns add 后面跟着要创建的 namespace 名称。如果相同名字的 namespace 已经存在,命令会报Cannot create namespace 的错误。
[root@localhost ~]# ip netns add net1
[root@localhost ~]# ip netns ls
net1
ip netns 命令创建的 network namespace 会出现在 /var/run/netns/ 目录下,如果需要管理其他不是 ip netns 创建的 network namespace,只要在这个目录下创建一个指向对应 network namespace 文件的链接就行。
有了自己创建的 network namespace,我们还需要看看它里面有哪些东西。对于每个 network namespace 来说,它会有自己独立的网卡、路由表、ARP 表、iptables 等和网络相关的资源。ip 命令提供了ip netns exec 子命令可以在对应的 network namespace 中执行命令,比如我们要看一下这个 network namespace 中有哪些网卡。更棒的是,要执行的可以是任何命令,不只是和网络相关的(当然,和网络无关命令执行的结果和在外部执行没有区别)。比如下面例子中,执行bash 命令了之后,后面所有的命令都是在这个 network namespace 中执行的,好处是不用每次执行命令都要把ip netns exec NAME 补全,缺点是你无法清楚知道自己当前所在的 shell,容易混淆。
[root@localhost ~]# ip netns exec net1 ip addr
1: lo: mtu 65536 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@localhost ~]# ip netns exec net1 bash
[root@localhost ~]# ip addr
1: lo: mtu 65536 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@localhost ~]# exit
exit
更新:通过修改 bash 的前缀信息可以区分不同 shell,操作如下:
$ ip netns exec ns1 /bin/bash --rcfile <(echo "PS1=\"namespace ns1> \"")
namespace ns1> ping www.google.com
PING www.google.com (178.60.128.38) 56(84) bytes of data.
64 bytes from cache.google.com (178.60.128.38): icmp_seq=1 ttl=58 time=17.6 ms
ip netns exec 后面跟着 namespace 的名字,比如这里的 net1,然后是要执行的命令,只要是合法的 shell 命令都能运行,比如上面的 ip addr 或者bash。
每个 namespace 在创建的时候会自动创建一个 lo 的 interface,它的作用和 linux 系统中默认看到的lo 一样,都是为了实现 loopback 通信。如果希望 lo 能工作,不要忘记启用它:
[root@localhost ~]# ip netns exec net1 ip link set lo up
默认情况下,network namespace 是不能和主机网络,或者其他 network namespace 通信的。
network namespace 之间通信
有了不同 network namespace 之后,也就有了网络的隔离,但是如果它们之间没有办法通信,也没有实际用处。要把两个网络连接起来,linux 提供了veth pair 。可以把 veth pair 当做是双向的 pipe(管道),从一个方向发送的网络数据,可以直接被另外一端接收到;或者也可以想象成两个 namespace 直接通过一个特殊的虚拟网卡连接起来,可以直接通信。
使用上面提到的方法,我们再创建另外一个 network namespace,这里我们使用 net0 和net1 两个名字。
我们可以使用 ip link add type veth 来创建一对 veth pair 出来,需要记住的是 veth pair 无法单独存在,删除其中一个,另一个也会自动消失。
[root@localhost ~]# ip link add type veth
[root@localhost ~]# ip link
4: veth0: mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 36:88:73:83:c9:64 brd ff:ff:ff:ff:ff:ff
5: veth1: mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether fe:7e:75:4d:79:2e brd ff:ff:ff:ff:ff:ff
小知识: 创建 veth pair 的时候可以自己指定它们的名字,比如 ip link add vethfoo type veth peer name vethbar 创建出来的两个名字就是 vethfoo 和 vethbar 。因为这里我们对名字没有特殊要求,所以就直接使用系统自动生成的名字。如果 pair 的一端接口处于 DOWN 状态,另一端能自动检测到这个信息,并把自己的状态设置为NO-CARRIER。
创建结束之后,我们能看到名字为 veth0 和 veth1 两个网络接口,名字后面的数字是系统自动生成的。接下来,要做的是把这对 veth pair 分别放到已经两个 namespace 里面,这个可以使用ip link set DEV netns NAME 来实现:
[root@localhost ~]# ip link set veth0 netns net0
[root@localhost ~]# ip link set veth1 netns net1
[root@localhost ~]# ip netns exec net0 ip addr
1: lo: mtu 65536 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth0: mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 36:88:73:83:c9:64 brd ff:ff:ff:ff:ff:ff
[root@localhost ~]# ip netns exec net1 ip addr
1: lo: mtu 65536 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
5: veth1: mtu 1500 qdisc noop state DOWN qlen 1000
link/ether fe:7e:75:4d:79:2e brd ff:ff:ff:ff:ff:ff
最后,我们给这对 veth pair 配置上 ip 地址,并启用它们。
[root@localhost ~]# ip netns exec net0 ip link set veth0 up
[root@localhost ~]# ip netns exec net0 ip addr add 10.0.1.1/24 dev veth0
[root@localhost ~]# ip netns exec net0 ip route
10.0.1.0/24 dev veth0 proto kernel scope link src 10.0.1.1
[root@localhost ~]# ip netns exec net1 ip link set veth1 up
[root@localhost ~]# ip netns exec net1 ip addr add 10.0.1.2/24 dev veth1
可以看到,最每个 namespace 中,在配置玩 ip 之后,还自动生成了对应的路由表信息,网络 10.0.1.0/24 数据报文都会通过 veth pair 进行传输。使用 ping 命令可以验证它们的连通性:
[root@localhost ~]# ip netns exec net0 ping -c 3 10.0.1.2
PING 10.0.1.2 (10.0.1.2) 56(84) bytes of data.
64 bytes from 10.0.1.2: icmp_seq=1 ttl=64 time=0.039 ms
64 bytes from 10.0.1.2: icmp_seq=2 ttl=64 time=0.039 ms
64 bytes from 10.0.1.2: icmp_seq=3 ttl=64 time=0.139 ms
--- 10.0.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2004ms
rtt min/avg/max/mdev = 0.039/0.072/0.139/0.047 ms
完成这些,我们创建的网络拓扑结构如下所示:

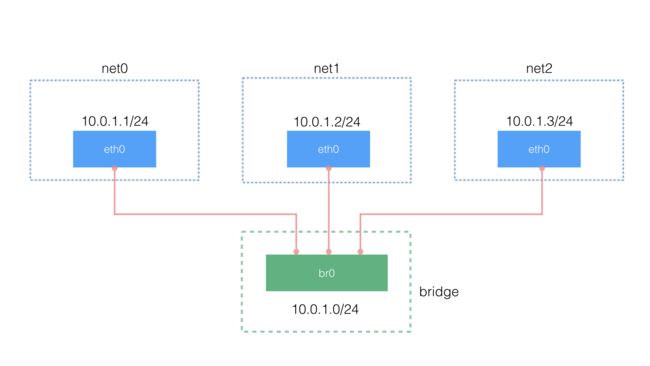
使用 bridge 连接不同的 namespace
虽然 veth pair 可以实现两个 network namespace 之间的通信,但是当多个 namespace 需要通信的时候,就无能为力了。讲到多个网络设备通信,我们首先想到的交换机和路由器。因为这里要考虑的只是同个网络,所以只用到交换机的功能。linux 当然也提供了虚拟交换机的功能,我们还是用ip 命令来完成所有的操作。
NOTE:和 bridge 有关的操作也可以使用命令 brctl,这个命令来自bridge-utils 这个包,读者可以根据自己的发行版进行安装,使用方法请查阅 man 页面或者相关文档。
首先我们来创建需要的 bridge,简单起见名字就叫做 br0。
[root@localhost ~]# ip link add br0 type bridge
[root@localhost ~]# ip link set dev br0 up
下面只演示一个 namespace 的操作,其他 namespace 要做的事情和这个类似。创建 veth pair:
[root@localhost ~]# ip link add type veth
把其中一个 veth(veth1) 放到 net0 里面,设置它的 ip 地址并启用它:
[root@localhost ~]# ip link set dev veth1 netns net0
[root@localhost ~]# ip netns exec net0 ip link set dev veth1 name eth0
[root@localhost ~]# ip netns exec net0 ip addr add 10.0.1.1/24 dev eth0
[root@localhost ~]# ip netns exec net0 ip link set dev eth0 up
最后,把另一个 veth(veth0)连接到创建的 bridge 上,并启用它:
[root@localhost ~]# ip link set dev veth0 master br0
[root@localhost ~]# ip link set dev veth0 up
可以通过 bridge 命令(也是 iproute2 包自带的命令)来查看 bridge 管理的 link 信息:
[root@localhost ~]# bridge link
17: veth0 state UP : mtu 1500 master br0 state forwarding priority 32 cost 2
最后通过 ping 命令来测试网络的连通性:
[root@localhost ~]# ip netns exec net0 ping -c 3 10.0.1.3
PING 10.0.1.3 (10.0.1.3) 56(84) bytes of data.
64 bytes from 10.0.1.3: icmp_seq=1 ttl=64 time=0.251 ms
64 bytes from 10.0.1.3: icmp_seq=2 ttl=64 time=0.047 ms
64 bytes from 10.0.1.3: icmp_seq=3 ttl=64 time=0.046 ms
--- 10.0.1.3 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2008ms
下图是这部分网络的拓扑结构,如果对 docker 网络熟悉的话,其实这和 docker 默认的 bridge 网络模型非常相似。当然要实现每个 namespace 对外网的访问还需要额外的配置(设置默认网关,开启 ip_forward,为网络添加 NAT 规则等)。
转载自 http://cizixs.com/2017/02/10/network-virtualization-network-namespace
参考资料
- 网络虚拟化技术(一): Linux网络虚拟化
- Introducing Linux Network Namespaces