深度学习的一些重点总结
一,变分推断
变分推断通过使用已知简单分布来逼近需推断的复杂分布,并通过限制近似分布的类型,从而得到一种局部最优、但具有确定解的近似后验分布。
在现实生活中,E步对 p ( z ∣ x , Θ t ) p(z|x,\Theta^t) p(z∣x,Θt)的推断很可能因为 z ⃗ \vec z z模型的复杂而难以进行,此时可以借助变分推断。通常假设 z ⃗ \vec z z服从分布:
q ( z ⃗ ) = ∏ i = 1 M q i ( z ⃗ i ) q(\vec z)=\prod_{i=1}^{M}q_i(\vec z_i) q(z)=i=1∏Mqi(zi)
即假设复杂的多变量 z ⃗ \vec z z可以拆解为一系列相互独立的多变量 z i ⃗ \vec {z_i} zi,更重要的是可以令 q i q_i qi分布相对简单或有很好的结构,例如可以假设 q i q_i qi为指数族的分布。其中 q i q_i qi是 q i ( z ⃗ i ) q_i(\vec z_i) qi(zi)的简写。这被称为“均值场法”,即我们可以选择 q i q_i qi的形式来选择任何图模型的结构,通过选择变量之间相互作用的多少来灵活地决定近似程度的大小。
在这个假设条件下,我们就可以得到变量子集 z ⃗ j \vec z_j zj最接近真实情形的分布为:
q j ∗ ( z ⃗ j ) = exp ( E i ≠ j [ ln p ( x ⃗ , z ⃗ ) ] ) exp ( ∫ E i ≠ j [ ln p ( x ⃗ , z ⃗ ) ] ) d z ⃗ j q_j^*(\vec z_j)=\frac{\exp (E_{i\ne j}[\ln p(\vec x,\vec z)])}{\exp (\int E_{i\ne j}[\ln p(\vec x,\vec z)])d\vec z_j} qj∗(zj)=exp(∫Ei̸=j[lnp(x,z)])dzjexp(Ei̸=j[lnp(x,z)])
在对变量 z ⃗ j \vec z_j zj的分布 q j ∗ q_j^* qj∗进行估计时融合了 z ⃗ j \vec z_j zj之外的其他 z ⃗ i ≠ j \vec z_{i \ne j} zi̸=j的信息,这是通过联合似然函数 ln p ( x ⃗ , z ⃗ ) \ln p(\vec x,\vec z) lnp(x,z)在 z ⃗ j \vec z_j zj之外的隐变量分布上求期望得到的,因此亦称“平均场”方法。
在实际使用变分法时,最重要的是考虑:
- 如何对隐变量进行拆解。
- 假设各变量子集服从何种分布。
- 在此基础上利用上式再结合EM算法即可进行概率图模型的推断和参数估计。
二,BP推导
**基本原理:**利用输出后的误差来估计输出层的前一层误差,再利用这个误差来估计更前一层的误差,依此逐层反传下去,从而获得其他各层的误差估计。
**核心思想:**利用梯度下降法,基于逐层计算的误差估计,对网络各连接权重进行调节。
各层误差大小等于:该结点收集到的误差乘以激励函数对“该结点加权和”的导数。


总之就三个步骤:
- 前向计算每个神经元的输出值 a j a_j aj( j j j表示网络的第个神经元,以下同);
- 反向计算每个神经元的误差项 δ j \delta_j δj, δ j \delta_j δj在有的文献中也叫做敏感度(sensitivity)。它实际上是网络的损失函数 E d E_d Ed对神经元加权输入 n e t j net_j netj的偏导数,即 δ j = ∂ E d ∂ n e t j \delta_j=\frac{\partial E_d}{\partial net_j} δj=∂netj∂Ed;
- 计算每个神经元连接权重的梯度 w i j w_{ij} wij(表示从神经元 i i i连接到神经元 j j j的权重),公式为 ∂ E d ∂ n e t j = a i δ j \frac{\partial E_d}{\partial net_j}=a_i\delta_j ∂netj∂Ed=aiδj,其中 a i a_i ai表示神经元 i i i的输出。
详细推导见纸质版。
三,CNN结构分析
大小变换公式
W 2 = W 1 − F + 2 P S + 1 W_2=\frac{W_1-F+2P}{S} + 1 W2=SW1−F+2P+1
H 2 = H 1 − F + 2 P S + 1 H_2=\frac{H_1-F+2P}{S}+1 H2=SH1−F+2P+1
在上面两个公式中, W 2 W_2 W2是卷积后Feature Map的宽度; W 1 W_1 W1是卷积前图像的宽度; F F F是filter的宽度; P P P是Zero Padding数量,Zero Padding是指在原始图像周围补几圈0,如果的值是1,那么就补1圈0; S S S是步幅; H 2 H_2 H2是卷积后Feature Map的高度; H 1 H_1 H1是卷积前图像的宽度。
参数量计算
经典结构分析对比
四,LSTM/GRU简述
(1)RNN
容易出现梯度爆炸或梯度消失问题。
梯度爆炸更容易处理一些。因为梯度爆炸的时候,我们的程序会收到NaN错误。我们也可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取,即梯度截断。
梯度消失更难检测,而且也更难处理一些。总的来说,我们有三种方法应对梯度消失问题:
- 合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
- 使用relu代替sigmoid和tanh作为激活函数。
- 使用其他结构的RNNs,比如长短时记忆网络(LTSM)和Gated Recurrent Unit(GRU),这是最流行的做法。因为它们的加性相互作用可以有效控制梯度消失,改善梯度流动。
(2)LSTM
权重数组 W W W最终的梯度是各个时刻的梯度之和,所以当某个时刻t的梯度降为几乎为0时,它之前的梯度都不会对权重数组 W W W的更新产生任何影响,也就是网络事实上已经忽略了t时刻之前的状态。这就是原始RNN无法处理长距离依赖的原因。
长短时记忆网络的思路比较简单。原始RNN的隐藏层只有一个状态,即 h h h,它对于短期的输入非常敏感。那么,假如我们再增加一个状态,即 c c c,让它来保存长期的状态,那么问题不就解决了么?
- **LSTM的输入有三个:**当前时刻网络的输入值 x t x_t xt、上一时刻LSTM的输出值 h t − 1 h_{t-1} ht−1、以及上一时刻的单元状态 c t − 1 c_{t-1} ct−1
- LSTM的输出有两个:当前时刻LSTM输出值 h t h_t ht、和当前时刻的单元状态 c t c_t ct。注意 x x x、 h h h、 c c c都是向量。
LSTM的关键,就是怎样控制长期状态 c c c。在这里,LSTM的思路是使用三个控制开关。
- 第一个开关,负责控制继续保存长期状态c;
- 第二个开关,负责控制把即时状态输入到长期状态c;
- 第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。
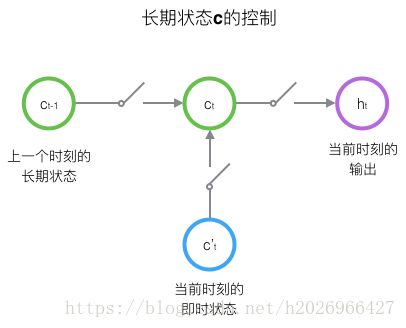
开关就用到了**门(gate)**的概念,而门的本质实际上是一层全连接层。它的输入是一个向量,输出是一个0到1之间的实数向量。
LSTM用两个门来控制单元状态 c c c的内容:
- 一个是遗忘门(forget gate),它决定了上一时刻的单元状态 c t − 1 c_{t-1} ct−1有多少保留到当前时刻 c t c_t ct;
- 另一个是输入门(input gate),它决定了当前时刻网络的输入 x t x_t xt有多少保存到单元状态 c t c_t ct。
LSTM用**输出门(output gate)**来控制单元状态 c t c_t ct有多少输出到LSTM的当前输出值 h t h_t ht。


详细计算过程见纸质版。
(3)GRU
GRU其实是LSTM的一种变体,它对LSTM做了很多简化,同时却保持着和LSTM相同的效果。因此,GRU最近变得越来越流行。
GRU对LSTM做了两个大改动:
-
将输入门、遗忘门、输出门变为两个门:更新门 z t z_t zt(Update Gate)和重置门 r t r_t rt(Reset Gate)。
-
将单元状态与输出合并为一个状态: h h h。
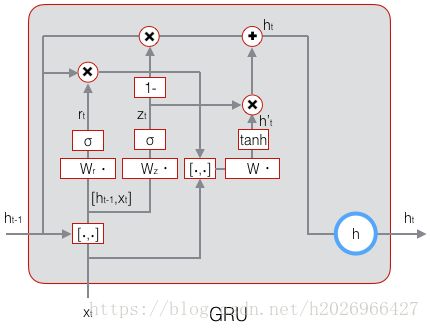
详细计算公式见纸质版。
(4)基于Attention机制的RNN

详细公式见纸质版。
五,正则化方法与优化算法
(1)正则化方法
- 参数范数惩罚或者约束范数惩罚
- 数据增强
- **噪声鲁棒性:**可将噪声加入到输入、权重或者输出(例如标签平滑)当中。
- **提前终止:**提前终止需要用到验证集,因为它的本质是为了找到最佳的训练轮数或者参数更新次数。
- 参数共享: CNN的卷积核、多任务学习等等。其中多任务学习中,共享参数使得各个任务可以从所有任务的汇集数据中获益。
- **参数绑定:**通过参数范数惩罚 ∣ ∣ w ( A ) ∣ ∣ − ∣ ∣ w ( B ) ∣ ∣ ||w^{(A)}||-||w^{(B)}|| ∣∣w(A)∣∣−∣∣w(B)∣∣,显示地强制两个模型的参数尽可能地接近。
- 集成方法
- Dropout:其实可以视为一种bagging的方法。
- 对抗训练
(2)优化算法
基本的优化算法
这类算法保持学习率不变。
标准的SGD算法在极值点附近梯度较小,收敛较慢,可以考虑利用更多的历史迭代信息加快收敛,从而引入动量。**动量使下降轨迹更为平滑,抑制振荡。 **
自适应学习率优化算法
这类算法学习率会进行自适应地变化。
批标准化
批标准化并不是一个优化算法,而是一个自适应的重参数化方法,试图解决训练非常深的模型的困难。重新参数化深层网络以减少层间更新协调的方法。
H ′ = H − u δ H^{'}=\frac{H-u}{\delta} H′=δH−u
其中, u u u是包含H每列列均值的向量, δ \delta δ是包含H每列列标准差的向量。
优点:
- 改善了网络中的梯度流动。
- 允许更大的学习率。
- 减小了在初始化时的强依赖性。
- 以一种有趣的方式充当正则化的形式,并略微减少了dropout的需要。
参数初始化

六,强化学习
七,Attention and Memory
Attention-based network
