concurrentHashMap原理和hashTable-线程安全的hashmap的三种实现
concurrentHashMap hashTable源码分析与比较
线程安全的Map共经历了三个过程,直接在方法上增加synchronized方法,segment段实现减少锁的粒度,cas(当前内存中的值V和旧的预期值A是否相等,如果相等则将新的值B赋值给V)锁实现。
https://blog.csdn.net/dianzijinglin/article/details/80997935 hashtable解析
https://www.cnblogs.com/dolphin0520/p/3932905.html 1.6版本concurrentHashMap实现
https://blog.csdn.net/jianghuxiaojin/article/details/52006118 1.8版本concurrentHashMap实现
Hashtable源码解析:
直接在方法上加synchronized方法,锁的粒度特别大
public synchronized V put(K key, V value) {
//确保value不为null
if (value == null) {
throw new NullPointerException();
}
//确保key不在hashtable中
//首先,通过hash方法计算key的哈希值,并计算得出index值,确定其在table[]中的位置
//其次,迭代index索引位置的链表,如果该位置处的链表存在相同的key,则替换value,返回旧的value
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
// 已有的key不在map中,校验是否需要rehash
modCount++;
if (count >= threshold) {
//如果超过阀值,就进行rehash操作
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
//将值插入,返回的为null
Entry e = tab[index];
// 创建新的Entry节点,并将新的Entry插入Hashtable的index位置,并设置e为新的Entry的下一个元素
tab[index] = new Entry<>(hash, key, value, e);
count++;
return null;
} 新加入的元素是放到链表头部还是尾部:
hashTable 和 concurrentHashMap的新节点时加入链表头结点还是尾节点
concurrentHashMap 加入尾部,因为刚好需要遍历到最后一个确定是否存在hash和key完全一致的节点
hashTable 加入首部,代码如下:
// 获取当前数组的头结点
Entry
// 创建新的Entry节点,并将新的Entry插入Hashtable的index位置,并设置e为新的Entry的下一个元素
tab[index] = new Entry<>(hash, key, value, e);
Entry的构造器如下:所以新插入的键值对是放在头部的
protected Entry(int hash, K key, V value, Entry
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
1.6版本concurrentHashmap实现
做到读取数据不加锁(volatile修饰table),并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,不用对整个ConcurrentHashMap加锁。
ConcurrentHashMap为了提高本身的并发能力,在内部采用了一个叫做Segment的结构,一个Segment其实就是一个类Hash Table的结构,Segment内部维护了一个链表数组,我们用下面这一幅图来看下ConcurrentHashMap的内部结构: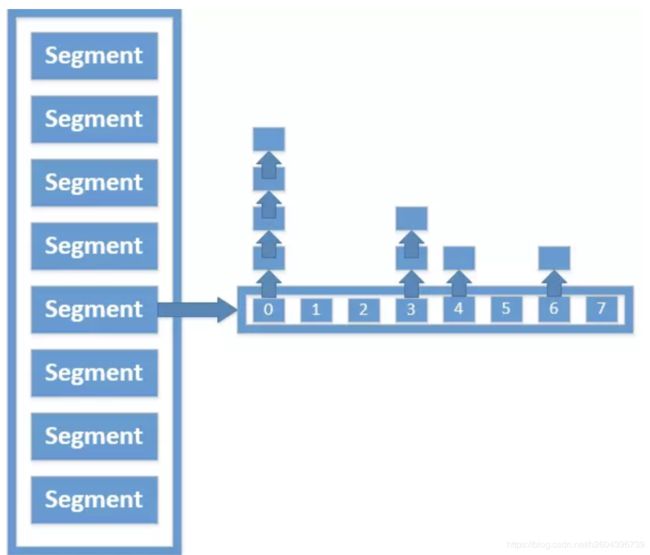
从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上),所以,通过这一种结构,ConcurrentHashMap的并发能力可以大大的提高。
Segment
我们再来具体了解一下Segment的数据结构:
| 1 2 3 4 5 6 7 |
static final class Segment transient volatile int count; transient int modCount; transient int threshold; transient volatile HashEntry final float loadFactor; } |
详细解释一下Segment里面的成员变量的意义:
- count:Segment中元素的数量
- modCount:对table的大小造成影响的操作的数量(比如put或者remove操作)
- threshold:阈值,Segment里面元素的数量超过这个值依旧就会对Segment进行扩容
- table:链表数组,数组中的每一个元素代表了一个链表的头部
- loadFactor:负载因子,用于确定threshold
HashEntry
Segment中的元素是以HashEntry的形式存放在链表数组中的,看一下HashEntry的结构:
| 1 2 3 4 5 6 |
static final class HashEntry final K key; final int hash; volatile V value; final HashEntry } |
可以看到HashEntry的一个特点,除了value以外,其他的几个变量都是final的,这样做是为了防止链表结构被破坏,出现ConcurrentModification的情况。
Put方法实现
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry[] tab = table;
int index = hash & (tab.length - 1);
HashEntry first = tab[index];
HashEntry e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
} 1.7 计算size的方式:分段计算两次,两次结果相同直接返回,否则对所有的分段加锁直接并且直接计算
1.8线程安全map实现
1.8版本相对1.6版本,摒弃了segment的思想,而是采用cas的实现方式,底层数据结构与hashmap相同(数组 +链表、红黑树)
Cas(compare and swap,乐观锁结构):比较内存中的值V和期望的老的值A,如果相等,则将修改后的值B赋给V;
1.8计算size的底层方法为sumCount
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
其基于countCell来计算size
static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}
对于countCell的操作本质上是基于java.util.concurrent.atomic.LongAdder,jvm一种利用空间换时间的方法。
hashTable 和 concurrentHashMap的rehash方式
hashTable两层for循环遍历,https://blog.csdn.net/valuetome111/article/details/77712933
chashMap 多线程并发rehash