【darknet速成】Darknet图像分类从模型自定义到测试
欢迎来到专栏《2小时玩转开源框架系列》,这是我们第12篇文章,前面已经说过了caffe,tensorflow,pytorch,mxnet,keras,paddlepaddle,cntk,chainer,deeplearning4j,matconvnet,lasagne。
今天说darknet,也是最后一个框架了,本文所用到的数据,代码请参考我们官方git
https://github.com/longpeng2008/LongPeng_ML_Course
作者&编辑 | 言有三
1 Darknet是什么
首先不得不夸奖一下Darknet的主页风格不错。

官网地址:https://pjreddie.com/darknet/
GitHub: https://github.com/pjreddie/darknet
Darknet本身是Joseph Redmon为了Yolo系列开发的框架。
Joseph Redmon,一个从look once,到look Better, Faster, Stronger,到An Incremental Improvement,也就是从Yolo v1,干到Yolo v2,Yolo v3的男人,头像很应景。

Darknet几乎没有依赖库,是从C和CUDA开始撰写的深度学习开源框架,支持CPU和GPU。
咱们的第一个开源框架说的是Caffe,现在这最后一个Darknet跟caffe倒是颇有几分相似之处,只是更加轻量级。
2 Darknet结构解读
首先我们看下Darknet的代码结构如下:
cfg,data,examples,include,python,src,scripts几个子目录。
2.1 data目录
以上就是data目录的内容,包含了各种各样的文件。图片就是测试文件了,不必说。我们首先看看imagenet.labels.list和imagenet.shortnames.list里面是什么。
imagenet.labels.list是:
n02120505
n02104365
n02086079
n02101556
·············
看得出来就是imagenet的类别代号,与之对应的imagenet.shortnames.list里是:
kit fox
English setter
Siberian husky
Australian terrier
·············
可知这两个文件配套存储了imagenet1000的类别信息。
接着看9k.labels,9names,9k.trees,里面存储的就是Yolo9000论文中对应的9418个类别了。coco.names,openimages.names,voc.names都类似。
2.2 cfg目录
cfg,下面包含两类文件,一个是.data,一个是.cfg文件。我们打开imagenet1k.data文件看下,可知它配置的就是训练数据集的信息:
classes=1000 ##分类类别数
train = /data/imagenet/imagenet1k.train.list ##训练文件
valid = /data/imagenet/imagenet1k.valid.list ##测试文件
backup = /home/pjreddie/backup/ ##训练结果保存文件夹
labels = data/imagenet.labels.list #标签
names = data/imagenet.shortnames.list
top=5
另一类就是.cfg文件,我们打开cifar.cfg文件查看。
##---------1 优化参数配置---------##
[net]
batch=128
subdivisions=1
height=28
width=28
channels=3
max_crop=32
min_crop=32
##数据增强参数
hue=.1
saturation=.75
exposure=.75
##学习率策略
learning_rate=0.4
policy=poly
power=4
max_batches = 5000 ##迭代次数
momentum=0.9 ##动量项
decay=0.0005 ##正则项
##---------2 网络参数配置---------##
[convolutional]
batch_normalize=1 ##是否使用batch_normalization
filters=128
size=3
stride=1
pad=1
activation=leaky ##激活函数
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[dropout]
probability=.5
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[dropout]
probability=.5
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[dropout]
probability=.5
[convolutional]
filters=10
size=1
stride=1
pad=1
activation=leaky
[avgpool]
[softmax]
groups=1
包含两部分,第一部分就是优化参数的定义,类似于caffe的solver.prototxt文件。第二部分就是网络定义,类似于caffe的train.prototxt文件,不同的是网络层用[]来声明,batch normalization以及激活函数等配置进了[convolutional]里面。
最后的avgpool不需要配置池化半径,softmax不需要配置输入输出,在最后设置group参数。
你可能好奇,那残差网络怎么弄呢?
[shortcut]
activation=leaky
from=-3
如上,通过一个from=-3参数来进行配置,就是往后退3个block的意思了。
2.3 python目录
下面只有两个文件,即darknet.py和proverbot.py。前者就是python调用yolo模型的案例,后者没什么用。
2.4 include,src,examples目录
include和src就是具体的函数实现了,卷积等各类操作都在这里。examples就是高层任务的定义,包括classifier,detector,代码的解读就超过本文的内容了,以后详解。
3 数据准备和模型定义
3.1 数据准备
前面已经把该介绍的都介绍了,下面就开始准备数据进行训练。跟caffe一样,数据准备的流程非常简单。
首先,在data目录下建立我们自己的任务,按照如下目录,把文件准备好
├── genedata.sh
├── labels.txt
├── test
├── test.list
├── train
└── train.list
使用如下命令生成文件
find `pwd`/train -name \*.jpg > train.list
find `pwd`/test -name \*.jpg > test.list
其中每一行都存储一个文件,而标签是通过后缀获得的。
/Users/longpeng/Desktop/darknet/data/mouth/train/60_smile.jpg
/Users/longpeng/Desktop/darknet/data/mouth/train/201_smile.jpg
/Users/longpeng/Desktop/darknet/data/mouth/train/35_neutral.jpg
/Users/longpeng/Desktop/darknet/data/mouth/train/492_smile.jpg
标签的内容存在labels.txt里面,如下
neutral
smile
3.2 配置训练文件路径和网络
去cfg目录下建立文件mouth.data和mouth.cfg,mouth.data内容如下:
classes=2
train = data/mouth/train.list
valid = data/mouth/test.list
labels = data/mouth/labels.txt
backup = mouth/
top=5
mouth.cfg内容如下:
[net]
batch=16
subdivisions=1
height=48
width=48
channels=3
max_crop=48
min_crop=48
hue=.1
saturation=.75
exposure=.75
learning_rate=0.01
policy=poly
power=4
max_batches = 5000
momentum=0.9
decay=0.0005
[convolutional]
batch_normalize=1
filters=12
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=24
size=1
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=48
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[connected]
output=128
activation=relu
[connected]
output=2
activation=linear
[softmax]
在这里我们用上了一点数据增强操作,大家在后面会看到它的威力。
4 模型训练
使用如下命令进行训练:
./darknet classifier train cfg/mouth.data cfg/mouth.cfg
训练结果如下:
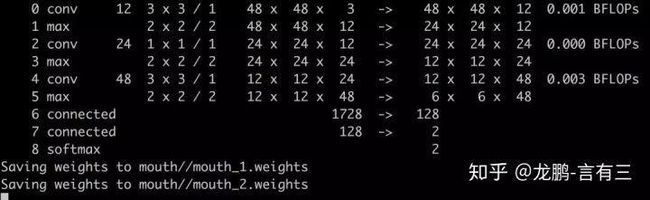

上面每一行展示的分别是:batch数目,epoch数目,损失,平均损失,学习率,时间,见过的样本数目。
将最后的结果提取出来进行显示,损失变化如下,可知收敛非常完美。
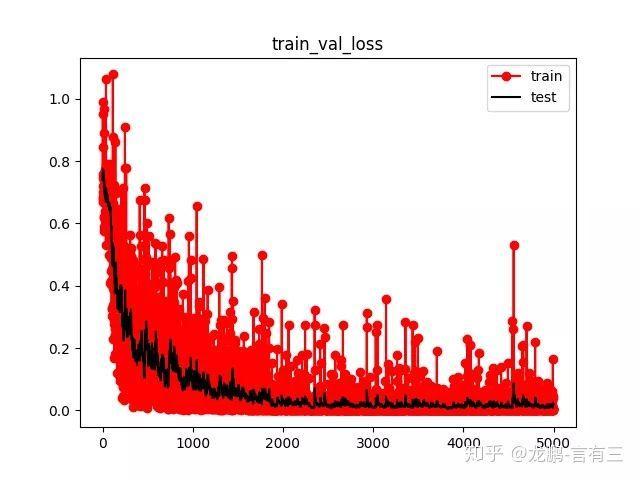
训练完之后使用如下脚本进行测试。
./darknet classifier valid cfg/mouth.data cfg/mouth.cfg mouth/mouth_50.weights
一个样本的结果如下:
darknet/data/mouth/test/27_smile.jpg, 1, 0.006881, 0.993119,
99: top 1: 0.960000, top 5: 1.000000
依次表示样本darknet/data/mouth/test/27_smile.jpg,被分为类别1,分类为0和1的概率是0.006881, 0.993119,该样本是第99个测试样本,此时top1和top5的平均准确率分为是0.96和1。
到这里,我们只用了不到500个样本,就完成了一个精度不错的分类器的训练,如此轻量级的darknet,我决定粉了。
总结
本文讲解了如何使用darknet深度学习框架完成一个分类任务,框架固然小众,但是速度真快,而且非常轻便,推荐每一个玩深度学习,尤其是计算机视觉的朋友都用起来。

本系列完整文章:
第一篇:【caffe速成】caffe图像分类从模型自定义到测试
第二篇:【tensorflow速成】Tensorflow图像分类从模型自定义到测试
第三篇:【pytorch速成】Pytorch图像分类从模型自定义到测试
第四篇:【paddlepaddle速成】paddlepaddle图像分类从模型自定义到测试
第五篇:【Keras速成】Keras图像分类从模型自定义到测试
第六篇:【mxnet速成】mxnet图像分类从模型自定义到测试
第七篇:【cntk速成】cntk图像分类从模型自定义到测试
第八篇:【chainer速成】chainer图像分类从模型自定义到测试
第九篇:【DL4J速成】Deeplearning4j图像分类从模型自定义到测试
第十篇:【MatConvnet速成】MatConvnet图像分类从模型自定义到测试
第十一篇:【Lasagne速成】Lasagne/Theano图像分类从模型自定义到测试
第十二篇:【darknet速成】Darknet图像分类从模型自定义到测试
感谢各位看官的耐心阅读,不足之处希望多多指教。后续内容将会不定期奉上,欢迎大家关注有三公众号 有三AI!
