linux工作中常用文件操作命令
本文主要是本人在使用linux的时候操作文件以及目录的常见的命令,主要内容如下:
ls 按照时间修改顺序列出文件,以M/G方式(human readable)显示出文件(如ls -lth) ,显示隐藏文件等
判断文件是否存在test -f filename && echo “File exists”
通配符文件的删除
文件的移动(少了以及大量),批量重命名等
SecureCRT linux与win10下文件的传送(rz, sz)例如linux下大批量的文件传输到win10下
dh (disk usage) 目录大小查看,排序
linux文件(主要是代码的树型查看)
文件查找(locate /find)
转载注明出处哈
“http://blog.csdn.net/haluoluo211/article/details/77714264”
ls
前段时间在linux上面跑C++程序的时候,偶尔程序会挂掉,这个时候我们需要通过core dump文件定位问题。而core dump文件有一大推我们需要安装最新的修改时间排序,显示的大小等信息:

然后在
sudo gdb AntiChatFilterd /data/core_files/core-AntiC659
通过gdb调试(注意上面省略了一些字符)
显示所有的文件,包括隐藏文件:ls -a
或者ls -ld .?*
按照最近修改时间排序 ls -lt (反向排序在ls -lrt)
最常用还有比如回到上一层目录 cd -
判断文件是否存在: test -f filename && echo “File exists”
通配符删除文件
一般 rm -f filename删除文件
比如我们要删除多个文件
rm -f 1.jpg 2.jpg 或者 rm -f {1,2}.jpg
rm -f *.jpg 删除所有的jpg
当rm 删除文件列表太长可以使用for循环
for f in *.pdf; do rm “$f”; done
文件移动重命名
比如重命名目录
mv /home/user/oldname /home/user/newname
当我们移动很多文件的时候,往往会报错参数太长
下面给出一个自己的示例

awk -F, ‘NR>1&&2==1{print1}’ submission_model_1_v1.csv | xargs mv –target-directory=result_1
上面通过 xagrs 把所有的图片通过参数,然后 mv到target directory中
或者(下面是移动文件并按照 0000x.jpg格式化重命名)
find -name ‘*.jpg’ \ # find jpg s
| awk ‘BEGIN{ a=0 }{ printf “mv \”%s\” %04d.jpg\n”, $0, a++ }’ # build mv command
| bash # run that command
文件批量重命名
比如我要把目录下所有的 png->jpg
rename 's/\.png$/\.jpg/' *.png
# 或者
for file in *.png
do
mv "$file" "${file%.png}.jpg"
done又比如想按照 0001~0010 ,jpg 这样的形式命名可以
find -name '*.jpg' \ # find png s
| awk 'BEGIN{ a=0 }{ printf "mv \"%s\" %04d.jpg\n", $0, a++ }' # build mv command
| bash # run that command
sz /rz (以及批量linux文件->win10)
一般 sudo rz -bey (覆盖原有文件,一般不会传送终止,如果终止了一般 disconnect SecureCRT 然后重新回到目录下 rz -bey 即可)
linux文件-》win10下 一般 sz filename即可
但是传送大量文件就有问题,参数太长
也可以类似上面的for 循环

#!/bin/sh
read -p "input the class num: " class
class_num=`awk '$2=='$class' {class_num+=1;} END {print class_num}' train.txt`
echo "$class sample size is: $class_num"
read -p "input the num of how many samples you wants to download: " download_num
step=$((class_num / download_num))
echo "step size is $step"
# all_files-> a.jpg b.jpg c.jpg
all_files=`awk -v c="$class" '$2==c {print $1} ' train.txt `
d_f=" "
count=0
for i in $all_files
do
count=$(($count+1))
if [ $count -eq $step ]
then
count=0
d_f="$d_f $i" #there is a space between two variable
fi
done
echo "after for loop, the end of sz"
cd /data5/light/storm_1_1/images
sudo sz $d_f
cd -
其中 train.txt 部分内容如下:
head -2 train.txt
train/4C0/4C0B77F76A1C58DE372F984AA8A807BEFF04F63A.png 0
train/4C0/4C0A77546E80894F8F89EE8D7AB8C7E159A99193.png 0
tail -2 train.txt
train/64f/64fc3277521ff37177cbb43329b891dcb8f01203.png 27
train/9C9/9C999B0A7FBEA214C3C8546549447A9902151ACB.png 16dh (disk usage) 目录大小查看,排序
先上个简单示例,查看boost的这个目录大小:

-h, --human-readable print sizes in human readable
format (e.g., 1K 234M 2G)(以合适的方式显示文件大小)
-s, --summarize display only a total for each
argument(显示总的大小)dh -h --max-depth=1 *
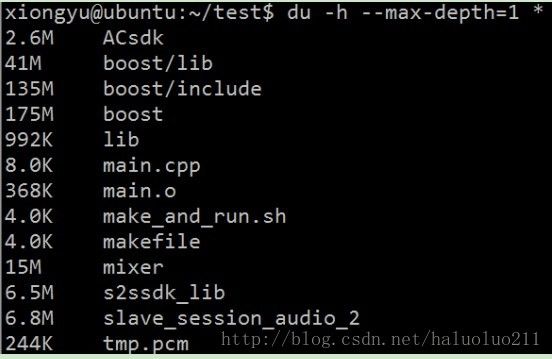

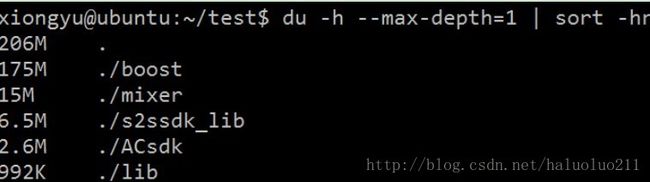
sort -h 按照大小排序,-r反向排序(故而最大的在第一个)
linux文件(主要是代码的树型查看)
tree ( 查看项目的目录结构) sudo apt-get install tree
tree -d
etc
|-- abrt
| |-- abrt-action-save-package-data.conf
| |-- abrt.conf
| |-- gpg_keys
| `-- plugins
| |-- CCpp.conf
| `-- python.conf
转载注明出处哈
“http://blog.csdn.net/haluoluo211/article/details/77714264”
文件查找(locate /find)
文件查找主要是find/locate一般locate查找比较快,但记得sudo updatedb(如果长时间没有更新)
locate -i new.txt (-i 忽略大小写Ignore Case )
find / -name “filename”
目的:在根目录“/”开始搜被称为filename的文件,“filename”文件名可以包含通配符(*,?)
Regular files only(当前目录下查找以my开头的文件查找)
$ find . -name ‘my*’ -type f