backbone模型:FCN、SRN、STN
文章目录
- FCN网络
- CNN图像分割
- 模型结构
- FCN github资源
- FCN的优缺点
- SRN 网络
- 什么是空间规整( spatial regularization)?
- SRN网络github资源
- STN网络
- 空间变换器
- localisation network
- 网格生成器: sampling grid
- 采样器:sampler
- 参考:
在图像识别领域, 很多基础、已被验证有效的模型会被用作基础模型backbone,接入不同的模型中,或者输出层做一些变形/优化。 这些基本的模型常见的有: VGGNet, ResNet,STN等。
FCN网络擅长提取图像细节特征;SRN利用注意力机制提高了图像语义特征提取精度, STN网络擅长做图像矫正。
FCN网络
FCN, fully convolutional network, 全卷积网络,该网络试图从抽象的特征中恢复出每个像素所属的类别。即从图像级别的分类进一步延伸到像素级别的分类。
FCN网络在经典的vgg模型上,把最后的全连阶层全部去掉,换成卷积层。利用反卷积(deconvolution),上池化(unpooling)等上采样(upsampling)操作,将特征矩阵恢复到接近原图的尺寸, 然后对每一个位置上的像素做类别预测, 从而能够识别更清晰的物体边界。 基于FCN的检测网络, 可以用高分辨率的特征图直接预测物体的边界,特别适合不规则物体。由于FCN网络最后一层特征图的像素分辨率较高,而图文识别任务中需要依赖清晰的文字笔画来区分不同字符(特别是汉字),所以FCN网络很适合用来提取文本特征。当FCN被用于图文识别任务时,最后一层特征图中每个像素将被分成文字行(前景)和非文字行(背景)两个类别。
CNN图像分割
传统基于CNN的图像分割算法,为了对一个像素做分类,使用该像素周围每一个图像作为CNN,缺点是第一存储开销比较大,另外,计算效率比较低下,相邻的像素基本上是重复的,三是像素块大小的限制了感知区域的大小。
模型结构
FCN将传统CNN中的全连阶层转化为卷积层,在传统CNN的结构中,前面5层是卷积层,6-7层是一维向量(长度是4096),第8层也是一维向量,长度为1000,分别对应1000个类别的概率。如下图上半部分所示, 最后一层中是1000个分类的概率。但是在FCN中,将6-8层标示为卷积层,分别是(4096,1,1),(4096,1,1),(1000,1,1),这也是FCN全卷积网络名称的由来。
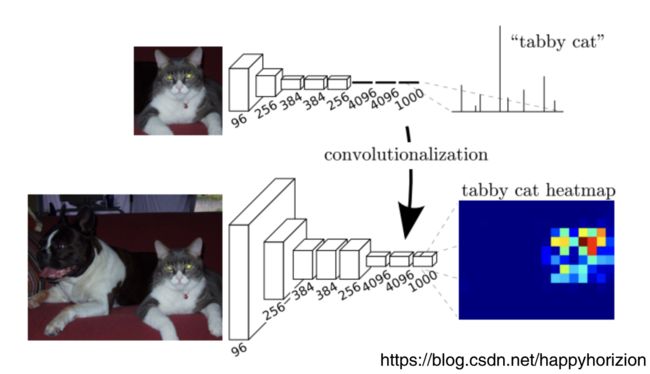
实际上,由于前面5层中多次卷积和池化pooling以后,得到的图像越来越小,分辨率越来越低。为了从分辨率低的粗略图像恢复到原图的分辨率,FCN采用了上采样(反卷积deconvolution)实现的。
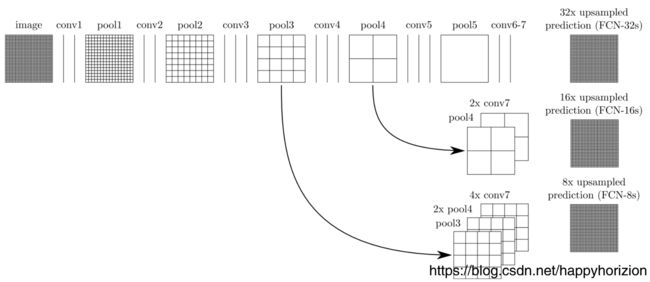
对于第5层的输出,反卷积到原图大小需要32倍放大,除此之外还将第3层、第5层的输出也做反卷积(16倍/8倍)的上采样,结果就精细了很多。
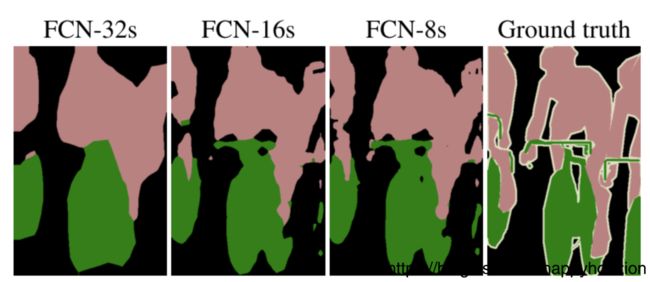
下图是32倍、16倍和8倍上采样的结果对比。
FCN github资源
tensorflow 1.12.0: https://github.com/hansinahuja/Semantic-Segmentation
FCN的优缺点
-
优点
FCN的优点很多,首先可以接受任意大小和尺寸的输入,二是更加高效,避免了传统CNN做图像分割的重复卷积和大量存储的问题。 -
缺点
但是FCN的结果还是比较模糊的,而且在对像素分类后没有考虑像素和像素之间的关系,忽略了空间规整(spatial regularization)步骤,缺乏空间的一致性。
SRN 网络
什么是空间规整( spatial regularization)?
为什么要做空间规整? 因为标签之间没有标注空间信息,难以得到标签之间潜在的空间关系。
如何做空间规整?在Learning Spatial Regularization with Image-level Supervisionsfor Multi-label Image Classification一文中,作者提出了学习所有标签之间的注意力图(attention maps),挖掘标签之间的潜在关系,结合正则化的分类结果和ResNet101网络的分类结果,提高了图像分了的表现。rocks置信度从0.405提高到了0.526, sun从0.339提高到了0.519. 其他类别也有相应的提高。
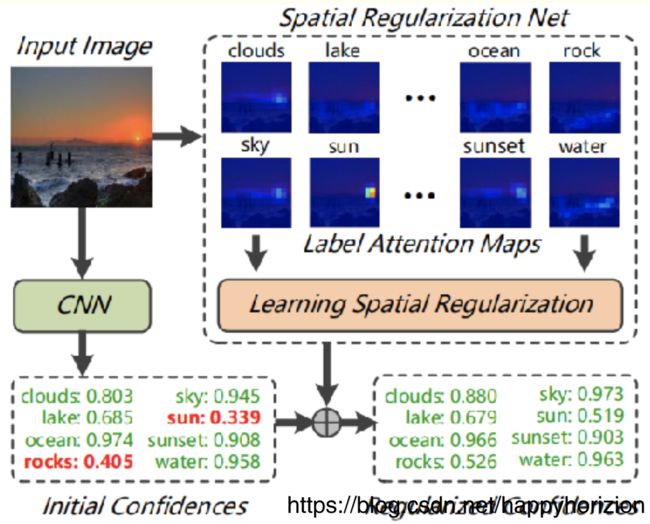
空间规整网络(spatial regulation network, SRN)的主网络是ResNet-101,得到基本的视觉分类特征并作为SRN的输入。SRN利用注意力机制,当图像中存在某个标签的时候,更多的注意力应该放在相关的区域,从而标签的注意力图(在原图的相应位置)编码了标签对应的空间信息,结合住网络和SRN分类结果得到最终的分类置信度。
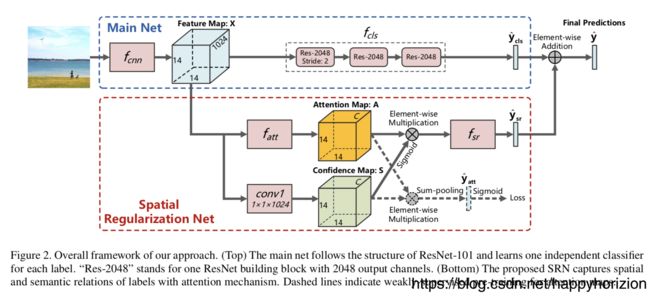
利用注意力机制学习空间正则信息的网络结构详图:

SRN网络github资源
caffe: https://github.com/zhufengx/SRN_multilabel
1.
STN网络
虽然卷积神经网络对于图像的分类能力非常强大,但是仍然受限于对输入数据本身的空间不变性,例如在OCR识别中,如果文字图像本身因为各种原因(拍照时候纸张的褶皱等)发生了扭曲,将会大大降低模型的识别正确率。空间变换网络可以显式地对网络中的数据进行空间变换,作为一个组件插入到现有的卷积架构中,在模型中学习平移、缩放、旋转和非刚性扭曲。
下面我们来看看STN(spatial transformer network)是如何通过训练一个网络实现空间变换的。
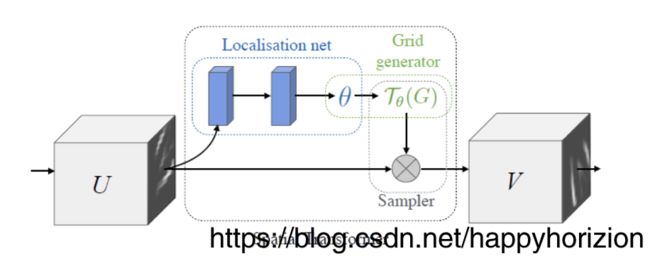
空间变换器
一个空间变换器可以分为:
1) localization network: 用来计算空间变换的参数 θ \theta θ
2)网格生成器 grid generator: 生成input map U到output map V各个像素点的对应关系 T θ T_{\theta} Tθ
3)采样器 sampler: 根据input map U 和 T θ T_{\theta} Tθ 生成最终的output map。
localisation network
localization network由一系列隐藏网络层(全连接或者卷积网络加回归层组成), θ \theta θ的形式可以根据需求来定, 例如2D仿射变换, θ \theta θ 就是2x3的向量。
θ = f l o c ( U ) \theta = f_{loc}(U) θ=floc(U)
网格生成器: sampling grid
假设输入U(可以是图片,也可以是其他层输出的feature map)的像素$ (x^s_i, y^s_i) , V 的 像 素 , V的像素 ,V的像素(x^t_i, y^t_i)$, 映射关系为:
KaTeX parse error: Expected & or \\ or \cr or \end at end of input: …n{pmatrix} 2. \theta = f_{loc}(U) KaTeX parse error: Expected 'EOF', got '\end' at position 27: …\ 4. y_i^s 5. \̲e̲n̲d̲{pmatrix} 6. =…
A θ A_{\theta} Aθ也可以是3D仿射变换、透射变换等。
采样器:sampler
采样器利用采样网络和输入的特征图同时作为输入,得到特征图变换后的结果。
V i c = ∑ n H ∑ m W U n m c max ( 0 , 1 − ∣ x i s − m ∣ ) max ( 0 , 1 − ∣ y i s − n ∣ ) V_i^c=\sum_n^{H}{\sum_m^{W}{ U^c_{nm} \max(0, 1-|x_i^s-m|)\max(0, 1-|y_i^s-n|)}} Vic=n∑Hm∑WUnmcmax(0,1−∣xis−m∣)max(0,1−∣yis−n∣)
STN 本质上是一种监督学习算法,通过将输入图片/其他层得到的特征在空间上进行对齐/配准,减少物体由于刚性/非刚性变换造成的识别准确率下降问题。
参考:
https://blog.csdn.net/taigw/article/details/51401448
空间规整: https://blog.csdn.net/zziahgf/article/details/77750222
空间规整:https://www.cnblogs.com/White-xzx/p/10203607.html
空间变换网络: https://blog.csdn.net/xholes/article/details/80457210
知乎: 理解STN https://zhuanlan.zhihu.com/p/41738716