大数据生态圈与IBM Platform Symphony架构设计
随着开源社区不断的壮大,很多以前鲜为人知的技术慢慢地走进了大众IT人员的视野。对一个数据中心而言,最火的两个技术领域便是云计算与大数据。其中每个领域都有一些代表的项目,如云计算领域的OpenStack、CloudStack等,那么大数据领域又有哪些知名的项目呢?当面对这样的问题时,很多人可能会快速地回答:Hadoop、Hive、Hbase以及后来的Yarn(Hadoop二代)、Mesos、Spark、Storm、Flink等。这些答案无疑都是正确的,然而对于整个大数据生态圈而言,会有很多不同的场景需要不同的框架和平台应用去处理,例如流计算任务、批处理任务或者存储的构建、数据的导入等等。我们可以看到一些企业已经开始将一部分业务或者数据迁移到大数据的平台,尤其是一些大型的互联网企业。那么,一个企业该如何选择一个适合的平台甚至一个框架?这个问题不太容易回答。本文致力于介绍整个大数据的生态圈以及IBM Platform Symphony产品,希望读者能从中得到这个问题的线索或答案。
分布式大数据框架的分类
在详细介绍Platform Symphony与大数据生态圈的关系之前,让我们先了解一下整个大数据生态圈的组成。我个人的理解是,目前这个行业可以简单的分为三大层次:分别是数据源、数据处理以及数据分析。数据分析是直接将大数据转换为商业价值的领域,在数据分析的领域会提出各种业务需求;数据处理领域则是负责实现数据分析提出的需求,这一领域也就是我们经常说的基础设施架构层(Infrastructure);数据源指的就是数据产生的地方。在这三块之间也有一些衔接的软件领域,不过往往也都归在了数据处理领域(基础架构层),例如衔接数据源与数据处理层的数据导入工具(如Sqoop等),以及衔接数据分析和数据处理的应用接口(如:SQL接口的Hive,以及流接口的Spark Streaming、Storm等)。在大数据的这三大领域中有很多开源以及非开源的产品,熟知的开源的Hadoop、Spark、Mesos等,都属于数据处理领域,也就是基础架构这一层次。IBM Platform Symphony也属于这个部分。 综上所述,如果宏观的抽象出整个大数据生态涉及的相关领域,大致如图1所示:

基于对大数据相关领域的宏观描述,下来我们就再谈下基础架构这一块。目前大多开源相关的大数据框架基本都可以归属到基础设施架构这个层次。为了更好的理解各个框架之间的关系,我们又将基础设施架构这块分为四层,分别是数据存储层、集群资源管理层、计算引擎层、以及应用接口层。除了一些提供易用性、可维护性以及健壮性的框架之外(一般也可以统称为管理类),其他大部分都可以归在这四类。例如HDFS属于数据存储层,Mesos和Yarn则属于集群资源管理层,Hadoop MapReduce、Storm、Spark等则归属于计算引擎层,Hive、Pig则为数据查询提供接口。Ambari则是一个提升易用性和可维护性的工具,Zookeeper提供了健壮性(HA)。这些系统之间具体的关系,可以参见下面的简图:
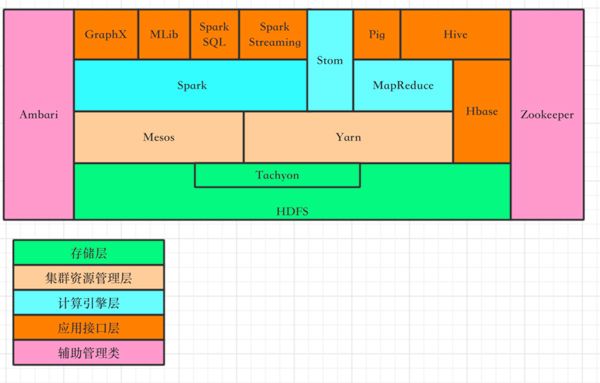
目前开源的大数据框架所支持的操作系统大多数都只支持了Linux,不过这一问题相信未来会有所解决,毕竟大多大数据框架的实现语言都是与操作系统无关的Java(Scala)。
大数据案例举例
通过以上的介绍,我们了解了其中一部分大数据相关的开源架构,但可能没法短期内将其对应到实际的案例中。因此,这里用一个很简单的查询业务架构作为例子,来说明这些框架之间的具体关系。由于传统的业务架构会将大部分数据保存在数据库中,所以这里假设有一个MySQL数据库保存了海量的客户终端信息(例如电话号码、话单以及动态GPS纪录),如果要将查询业务迁移到大数据平台,首先要做的便是数据迁移(Data Movement)。
对于数据迁移的场景我们可以使用Sqoop工具进行数据导入。简单来说,Sqoop是一个用MapReduce框架实现的应用,并且Sqoop只有Map的实现。Sqoop的Map任务会并行的从数据库中读取表的信息,并保存到Hadoop的HDFS中。Sqoop本身也可以实现反向的导入,也就是从HDFS到数据库,不过这里我们用不到。了解了Sqoop的大致实现,我们可以知道Sqoop的运行离不开Hadoop的支持。另外需要注意的是,在这个例子中的数据是结构化的DB数据。如果是非结构化或半结构化数据,Sqoop可能就无能为力了。对于非结构化的数据,有兴趣的读者可以研究下Flume等的使用。
当数据迁移完成之后,我们可以通过Hive提供SQL的支持。上层应用便可以方便的通过SQL语句查询HDFS中的用户信息。从这里我们也要了解到Hive本身并不是数据库,它只是提供SQL支持的一种接口实现。Hive会将查询语句转换为MapReduce任务来执行。对于响应时间要求高的客户,可能Hive并不能满足需求。有兴趣的读者也可以在类似的案例中使用Hbase。Hbase是一个分布式的列式数据库,其底层存储也是使用HDFS。不过与Hive不同,其是一款真正的数据库。在大多的场景中,Hbase的响应延迟会比Hive小很多。篇幅有限,这里就不过多介绍Hbase。
到这里我们知道整个方案至少需要有Sqoop、Hive、HDFS以及MapReduce的实现框架。那么Hadoop Yarn除了支持MapReduce的Workload之外,还有什么作用?为了回答这个问题,我们需要引入另一个重要的概念“多租户”。在Hadoop一代中只有对MapReduce任务的支持,而今随着数据中心的发展,往往是多种计算框架并存的。在我们这个例子中,数据迁移一旦完成,批处理的查询任务又不是很频繁的话,就会造成集群资源的浪费。那么为了最大化的提高集群资源利用率,就必须允许多种计算框架之间的资源共享。而Yarn作为一个集群资源的管理者,就可以很好协调多种计算框架之间的资源分配和管理。当然,这也需要计算框架本身的支持。MapReduce是Yarn内置的一种计算框架,已经由Hadoop社区实现。但对于其他的计算框架,则需要其他社区根据Yarn的API来实现对应的App Master。为了方便用户部署和管理集群,我们可以使用Ambari。该案例的整体架构图如图3。
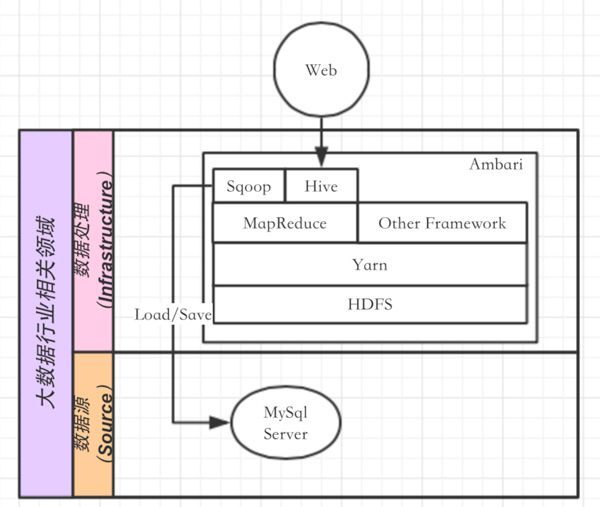
如果引申该案例的话,我们可以在上图的其他Framework中应用更多的计算框架。例如当该案例的集群又需要处理流数据的话,那么我们可以在Other中使用Spark以及Storm等。目前Yarn已经支持在其上运行Spark和Storm等计算框架。对于部分应用也可以使用Apache Slider来部署到Yarn之上。篇幅有限,这里就不过多的介绍这些框架了。
Platform Symphony简介
简单来说,Platform Symphony是一个提供数据分发、任务调度以及资源管理的企业级分布式计算框架,并且支持异构化的IT环境。Platform Symphony由两层架构组成,一层是负责资源管理的EGO(全称Enterprise Grid Orchestrator),另一层是任务管理的SOAM(全称Service-Oriented Architecture Management)。在Symphony的集群中,用户需要根据Symphony提供的API实现Client和Service程序。Symphony涉及的基础模块如图4。
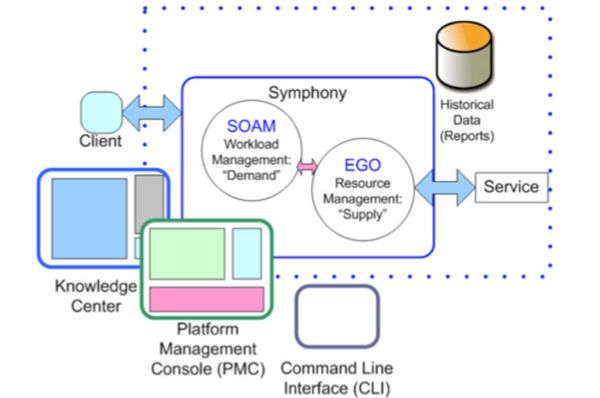
如图4所示,Client程序用于提交任务到Symphony集群,Symphony会在EGO层为该类应用申请计算资源,接着在对应的机器上启动用户的Service。Service接收任务数据并进行计算,最终会通过Symphony将任务结果返回Client程序。PMC是Symphony提供的一个专业WEB操作界面,其可以定制Symphony集群的配置,以及管理任务等。CLI是Symphony提供的命令行工具的集合,对于习惯使用命令操作的用户来说,更加方便和高效。Knowledge Center是Symphony产品文档的WEB接口,用户可以在其中找到Symphony各个功能的介绍和使用方法。
那么Platform Symphony在大数据中的基础架构层扮演怎样的角色,又可以替代哪些开源的框架呢?带着问题,我们来理解图5。
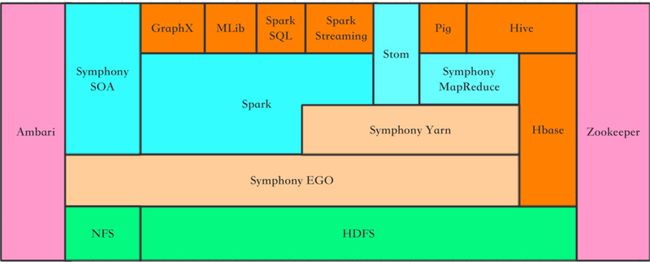
从图5中我们可以看出,在大数据应用场景中,Platform Symphony既处在资源管理层,也涵盖了计算引擎层。因此很多原有的大数据应用,都可以很平滑的迁移到Symphony的集群中运行,例如Hive、Pig等。并且用户以前在Hadoop MapReduce上开发的应用也可以很平滑的运行在Symphony之上。
对比开源的框架,Platform Symphony中的EGO相似与Yarn和Mesos,都处于集群的资源管理层。SOAM则处于计算引擎层,也就是计算框架,负责任务管理和调度。Symphony MapReduce是Symphony内置的一种应用(Hadoop MapReduce也是内置于Yarn的一种应用)。用户其实可以根据Symphony的API实现各种不同的Symphony应用。目前Symphony已经与开源Yarn、Spark、Docker集成,也就是说用户之前在Yarn和Spark上面的应用,都可以直接通过Symphony管理和调度集群资源。另外,也可以将Symphony的用户实例运行在Docker容器中。同时Symphony也支持了通过Ambari部署和管理集群,从而方便用户使用Platform Symphony替代部分开源框架。如果将Symphony应用到之前我们给的示例方案中,大致架构如图6。
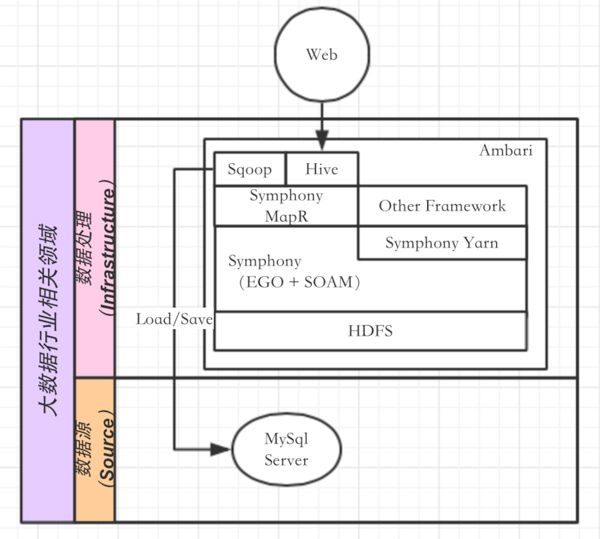
与开源框架不同,Symphony最终是通过其中的EGO模块实现应用之间的资源管理和共享。值得一提的是,Symphony的实现语言是以C和C++为主,其支持的平台也涵盖了市面上大多的操作系统,例如Windows、Linux、Solaris以及AIX等。篇幅有限,这里没有过多的阐述Symphony的内部架构,后续文章中,我们再来探讨Symphony的详细功能和设计。
Platform Symphony与Yarn的对比
很多人提到大数据,可能只意识到了之前我们提到的开源框架,其实是先入为主了。Hadoop MapReduce和Spark之类,这些都只是不同的计算框架而已。Symphony的用户完全可以根据自己的业务计算逻辑,实现自己的Symphony应用。拿MapReduce而言,它也只是Symphony的一个应用。这也间接说明了Symphony的另一个优势,多租户的概念。也就是说,Symphony中可以同时运行多种类型的应用。用过Yarn的读者,可能觉得Symphony有些类似于Yarn。这里就将Symphony的各个模块与YARN做个简单的对比。在对比之前,我们需要先介绍一些Symphony的概念,如图7。

Symphony中的SOAM是一个面向服务的中间件,其由Session Director(SD)、Session Manager(SSM)、Service Instance Manager (SIM)和Service Instance(SI)组成。Client就是用户根据Symphony SDK开发的客户端程序,用户从Client提交计算任务。Client会先和SD建立连接,SD会找到该类型应用的SSM。SSM用于管理一类应用的任务。如果该类型SSM不存在,SD会向EGO层申请管理节点的资源,并启动SSM。SSM会根据用户提交的任务向EGO层申请一定的计算资源。拿到计算资源后SOAM层会在计算节点启动SIM和SI(一般一个Slot启动一个SI实例)。然后SSM会发送任务和数据到SIM,进而到SI完成计算。SIM会管理用户的Service进程,如果用户的Service遇到一些错误,SIM会根据用户配置做出对应的行为,我们称之为Error Handing。
图8是Yarn的架构设计:

同样Yarn的Client也是用来提交任务的,在Yarn中RM会申请资源启动App Master。这一步类似于SOAM中SD申请资源启动(或找到)SSM。Yarn中App Master会向RM申请资源启动container运行MR任务,并收集任务状态。这里类似于SSM向EGO申请资源启动SIM和SI,并发送任务和收集任务结果的过程。SSM和App Master一样,是管理和调度任务的模块,在一个集群中可以存在多个(多种不同类型的应用)。很多人都很赞叹Yarn架构的前沿性,尤其与Hadoop一代比较,Yarn将资源管理层单独抽象出来,这样使得Hadoop的架构更加清晰。而Symphony十几年前就已经这样设计了,可见Symphony设计的前瞻性。
当然Symphony与Yarn也有一些差异,例如默认情况下(Yarn可以配置),Yarn的App Master是启动在Yarn的Container中,与真正的计算实例的Container并无特殊对待。也就是说启动App Master的机器,有随机性。而Symphony一般只能启动SSM在Symphony的管理节点。一般情况下,管理节点的硬件性能要求会高于计算节点,而SSM等管理进程对内存以及CPU计算能力的消耗一般也会比较大,所以在管理节点启动SSM这样的重量级进程是有技术背景的。再例如Yarn没有Resource Group的概念,如果需要将某些特殊的任务调度到某一群特定机器时,Yarn显得有些笨重,因为Yarn目前只能通过标签调度(Tag Policy)去做。Symphony可能只需要设定几个Resource Group,并设计不同优先级即可(Symphony很早前也支持了Tag的调度策略)。与所有的开源框架相比,Symphony支持更多的OS平台以及硬件平台。例如Hadoop目前还没支持Windows,而Symphony很早就支持了。更多的差异化,可以在IBM的Knowledge Center找到。
结束语
开源技术的发展确实降低了大数据计算的门槛,因而很多企业也开始了各自的大数据之路。不过一个符合企业特定使用的分布式框架往往需要经历数年甚至十年的进化,才会趋于稳定和成熟。所以并不是每个企业都适合直接去使用开源的产品,往往更多的是使用某些公司包装过的开源产品,从而减少维护和开发的成本。对于IBM Platform Symphony来说,它是一个经历十年以上磨练的分布式计算产品,凭借其技术沉淀,已经在国外银行业应用了很多年,历史远远早于Hadoop。随着大数据在国内的兴起,Symphony也一直致力于解决国内大数据场景的问题和瓶颈,发挥其优势。目前Platform Symphony已经支持了多维度资源调度,并且支持通过Ambari安装部署Symphony集群。最新的发行版中也支持了Spark、Yarn和Docker。用户可以很平滑将开源框架中的应用运行在Symphony上。
作者:沈钊伟([email protected]),2011年加入IBM CSTL(西安)至今,一直从事分布式计算以及大数据相关的研发工作。
责编:周建丁([email protected])