增强学习之入门 这个很明白
本文首发于集智:https://jizhi.im/blog/post/intro_q_learning
“机器学习”的话题一直很火热,相关的概念也是层出不穷,为了不落后于时代,我们都还是要学习一个。
第一次听到“增强学习”(Reinforcement Learning)的时候,我以为只是在“深度学习”的基础上又玩儿的新花样。后来稍微了解了一下,发现其实是完全不同的概念,当然它们并非互斥,反而可以组合,于是又有了“深度增强学习”(Deep Reinforcement Learning)。
这让人不由得感慨起名的重要性,“增强”这个名称就给人感觉是在蹭“深度”的热点,一个下五洋,一个上九天。而“卷积神经网络”(Convolutional Neural Network)这个名字就好的多,其实这里的“卷积”跟平时说的那个卷积并不是一回事,但是就很有科技感、Geek范。更好的还有“流形学习”(Manifold Learning),洋溢着古典人文主义气息。
天地有正气,杂然赋流形。——文天祥《正气歌》

军师,就是掌握了决策艺术的人。
增强学习是关于决策优化的科学,其背后正是生物趋利避害的本能。
“熊瞎子掰苞米”就是一个典型的决策过程。因为胳肢窝只能夹一个苞米,所以对每个苞米,熊瞎子都要做一个决策——掰,还是不掰?这是个问题。
在俗话故事里,熊瞎子并不知道自己掰一个丢一个,所以他的决策就是“掰掰掰”(Buy, Buy, Buy),最后结果就是拿了一个很小的苞米,后悔地想要剁手。而聪明的智人却选择“只掰比自己胳肢窝里大的”,那么理想状况下,就是得到了最大的。

熊瞎子不高兴
这里,熊瞎子或智人表示Agent,也就是决策过程里的行为主体。玉米地就是Environment,而现在胳肢窝里的苞米大小则是State,而眼前一个等待采摘的苞米,是熊瞎子对环境的Obervation。掰还是不掰?无论哪一种,都是对环境做出的Action。
当你走出玉米地时,最终拿到的苞米,才是自己的,这是你的Reward。“掰掰掰”,“只掰大的”或是“只掰贵的,不掰贵对的”——这些都是Policy。以上就是增强学习里的几个核心基本概念。

增强学习所解决的问题,介于“有监督”和“无监督”之间。决策是有目标的,或是“最大的苞米”,或是“赢下这盘棋”,这就与聚类任务不同。但是这个“目标”又不是固定明确的,最终获胜的棋路,就一定是最佳的吗?未必,不像图片分类或是价格预测,能评判个准确率。
如果要用知乎的方式来描述增强学习,应该是“如何评价”。比如一手“炮五平二”,是好是坏呢?不是立即就能得到反馈的,而可能是在终盘才能体现出来,这就是Reward的滞后性。所以做增强学习,心里应该时刻装着“婆婆婆婆这是真的吗?我不信,等反转!”
你从昏迷中醒来,发现自己被锁着,面前一个电视自动打开了。画面上有一个眼神和善的玩偶,用Kaiser一样的山东口音说"I wanna to play a game."

Game的规则是这样的,一个4x4的方格代表迷宫。你是夺宝奇兵、摸金校尉、古墓丽影,从左上角出发,直到右下角挖宝。但是这个迷宫里面不太平,有很多陷阱,踩上就是一个“大侠请重新来过”。

总有一款适合你

这里的方格,就是Environment。虽然对于电脑前的我们,似乎很容易,但是对Agent来说,他尚且对力量一无所知的。不过,只要Agent知道生命的可贵(Reward),就可以训练出一个Policy。
游戏的目的是让分数最大化,比如踩到陷阱了,-10。拿到宝贝了,+10。同样是最终拿到了宝贝,我们希望的是最短路径,那么如果走了多余的路,就要 -1。
Q-Learning的目的就是学习特定State下、特定Action的价值。Q并不是某个本质骑士取的字母,而是表示Quality。
Q-Learning的方法是建立一个表,以state为行、action为列。迷宫共有16个格,每个格子都有5个方向,所以Q-table就是16x5的一个表,对应总共80种可能的决策。
首先以0填充Q-table进行初始化,然后观察每一个决策带来的回馈,再更新Q-table。更新的依据是Bellman Equation:
- s: 当前状态state
- a: 从当前状态下,采取的行动action
- s': 今次行动所产生的新一轮state
- a': 次回action
- r: 本次行动的奖励reward
- \gamma : 折扣因数,表示牺牲当前收益,换区长远收益的程度。
那么最关键的问题是:如何计算Q?
Agent所做的每一轮决策(即一盘游戏),称为一个episode,跟美剧里的“集”单位一样。每一次行动,都会更新Q-table。为了简化过程方便理解,我们换一个更小的迷宫:

初始Q-table如下(行:state,列:action):

UDLR——上下左右;N——静静地看着你。
相应的Q-table如下(E表示不可能的行动):

但是这个Q-table是我们希望得出或逼近的,在游戏开始时,Agent所知的Q-table还是一个全0的矩阵。
算法的基本流程:
- 初始化Q-table矩阵
- 选择起始state
- 选择当前state(s)下的一个可能action(a)
- 换移到下一个state(s')
- 重复第3步
- 使用Bellman Equation,更新Q-table
- 将下一个state作为当前state
- 如此迭代三十年,直到大厦崩塌
比如,从state-1开始,可能的action有D, R, N。然后我们选择了D,到了state-3,这个state踩中了陷阱,所以-10。
在state-3又有三种可能的action:U, R, N。 又因为此时Q-table还没有经过更新,所以当然就是0。假设折扣因数,则有:
第一次更新Q-table的结果是:

现在,我们来到了state-3,如果选择R,就到达了state-4,+10。再次更新Q-table为:
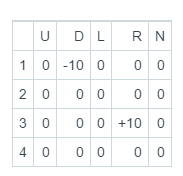
以上就是一个episode。重复这个过程,就像中学生物书里,用电击训练蚯蚓,去训练我们的Agent。经过不断的练习,Agent一定会变强(当然,也可能变秃)。
实践环节:
以下代码可以在集智的https://jizhi.im/blog/post/intro_q_learning中的在线代码运行器中直接运行和修改,不用再复制代码到你的pycharm中了。
- import random
- import matplotlib.pyplot as plt
- gamma = 0.7
- reward = np.array([[0, -10, 0, -1, -1],
- [0, 10, -1, 0, -1],
- [-1, 0, 0, 10, -1],
- [-1, 0, -10, 0, 10]])
- q_matrix = np.zeros((4, 5))
- transition_matrix = np.array([[-1, 2, -1, 1, 1],
- [-1, 3, 0, -1, 2],
- [0, -1, -1 , 3, 3],
- [1, -1, 2, -1, 4]])
- valid_actions = np.array([[1, 3, 4],
- [1, 2, 4],
- [0, 3, 4],
- [0, 2, 4]])
- for i in range(1000):
- start_state = 0
- current_state = start_state
- while current_state != 3:
- action = random.choice(valid_actions[current_state])
- next_state = transition_matrix[current_state][action]
- future_rewards = []
- for action_nxt in valid_actions[next_state]:
- future_rewards.append(q_matrix[next_state][action_nxt])
- q_state = reward[current_state][action] + gamma * max(future_rewards)
- q_matrix[current_state][action] = q_state
- #print(q_matrix)
- current_state = next_state
- print('Final Q-table:')
- print(q_matrix)
至此,我们已经完成了一个最简单的增强学习应用,没有任何跟神经网络相关的概念。那么前面提到的“深度增强学习”又是个什么鬼呢?其实就是把神经网络用在Q-Learning上,后文会详细探讨。