目标检测知识点及常用网络——RCNN,SPPNET等
参考了这个博文https://blog.csdn.net/liuxiaoheng1992/article/details/81775007
物体检测算法常用到的概念
下面我们讲解一下在物体检测算法中常用到的几个概念:Bbox,IoU,非极大值抑制。
Bounding Box(bbox)
bbox是包含物体的最小矩形,该物体应在最小矩形内部,如上图红色框蓝色框和绿色框。
物体检测中关于物体位置的信息输出是一组(x,y,w,h)数据,其中x,y代表着bbox的左上角(或者其他固定点,可自定义),对应的w,h表示bbox的宽和高.一组(x,y,w,h)可以唯一的确定一个定位框。
Intersection over Union(IoU)
对于两个区域R和R′,则两个区域的重叠程度overlap计算如下:
O(R,R′)=|R∩R′|/|R∪R′|
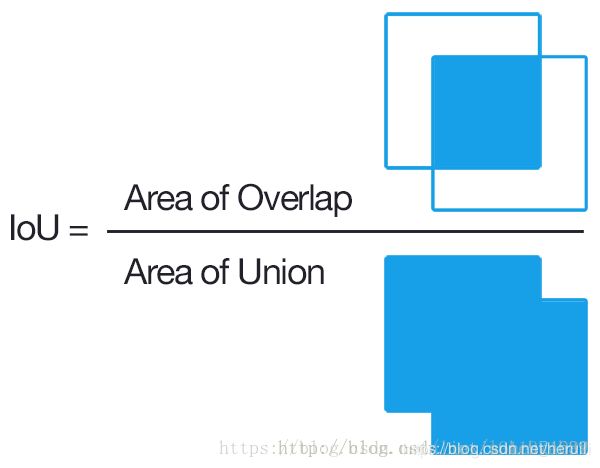
在训练网络的时候,我们常依据侯选区域和标定区域的IoU值来确定正负样本。
非极大值抑制(Non-Maximum Suppression又称NMS)
非极大值抑制(NMS)可以看做是局部最大值的搜索问题,NMS是许多计算机视觉算法的部分。如何设计高效的NMS算法对许多应用是十分关键的,例如视频跟踪、数据挖掘、3D重建、物体识别以及纹理分析等。
这里我们主要针对非极大值抑制在物体检测上的应用,非极大值抑制就是把不是极大值的抑制掉,在物体检测上,就是对一个目标有多个标定框,使用极大值抑制算法滤掉多余的标定框。
R-CNN
如上图所示,R-CNN这个物体检查系统可以大致分为四步进行:
1.获取输入图像
2.提取约2000个候选区域
3.将候选区域分别输入CNN网络(这里需要将候选图片进行缩放)
4.将CNN的输出输入SVM中进行类别的判定
上述四个步骤是一个大致的过程,而且是一个检测的过程,实际上训练过程比较麻烦,下面开始详细介绍。
一、候选区域的提取
这部分有很多传统的方法可以选择,本文为了和之前的物体检测算法进行对比,选择了selective search方法
二、缩放候选区域
因为CNN对输入图像的大小有限制,所以在将候选区域输入CNN网络之前,要将候选区域进行固定尺寸的缩放。
缩放分为两大类(该部分在原文附录A):
1)各向同性缩放,长宽放缩相同的倍数
tightest square with context:
把region proposal的边界进行扩展延伸成正方形,灰色部分用原始图片中的相应像素填补,如下图(B)所示
tightest square without context:
把region proposal的边界进行扩展延伸成正方形,灰色部分不填补,如下图©所示
2)各向异性缩放, 长宽放缩的倍数不同
不管图片是否扭曲,长宽缩放的比例可能不一样,直接将长宽缩放到227*227,如下图(D)所示
在放缩之前,作者考虑,在region proposal周围补额外的原始图片像素(pad p)。上图中,第一层p=0,第二层p=16。
最后试验发现,采用各向异性缩放并且p=16的时候效果最好
三、测试方法
测试时其实分两个结果
1.分类
在测试的时候,先对带检测图像提取出约2000个候选区域,将每个区域都进行缩放,然后将缩放后的图片输入CNN进行特征提取,对CNN输出的特征用SVM进行打分(每类都有一个SVM,21类就有21个SVM分类器),对打好分的区域使用NMS即非极大抑制(每类都单独使用)。
这里SVM怎么打分的这些细节没有细讲,只是简单的说检测的时候使用20004096维度的特征矩阵与4096N的SVM参数矩阵相乘(N为所要分的类别数),我也没看过原码,所以也不太清楚,知道的可以讨论一下。
到这里分类就完成了,但是得到的位置只是候选区在图像中的位置,而候选区的位置并不一定就是ground truth,即检测目标的真实位置。
2.定位(回归)
将CNN对候选区域提取出的特征输入训练好的线形回归器中,得到更为精确的位置定位,具体情况会在下面训练方法中详细介绍。但要明确的是,这些回归器是按照类来训练的,即每类分类完后进行回归。
四、训练方法
1.预训练
训练的时候,文章用了个trick,他先用ILSVRC2012数据库训练Alexnet,训练的时候目标时图片分类,因为ILSVRC2012数据库没有分类的标定数据。这步称为预训练。
2.fine-tuning
这种方法也是当数据量不够的时候,常用的一种训练方式,即先用别的数据库训练网络,然后再用自己的数据库微调训练(fine-tuning)。微调期间,定义与ground truth的IoU大于0.5的候选区域为正样本,其余的为负样本。
这里训练时,网络输出要有所改变,因为分类问题,网络输出为N+1,其中N为正样本的类别数,1为背景。
对于VOC,N=20,对于ILSVRC2013, N=200。
3.目标分类
因为最终目标分类是通过SVM进行分类的,而不是通过网络框架中的softmax分类的。
下面先说一下在SVM的训练中,正负样本的定义,为什么这样定义,然后再说一下为什么不直接用softmax输出的结果而是再训练SVM来进行分类的。
1)SVM正负样本的定义,为什么fine-tuning与SVM正负样本定义不一样?
在训练SVM时,正样本为groundtruth,负样本定义为与ground truth的IoU小于0.3的候选区域为负样本,介于0.3与0.7之间的样本忽略。
fine-tuning时担心过拟合的原因,要扩大正样本的样本量,所以定义比较宽松,但是SVM是最终用于分类的分类器,而且SVM原理就是最小的距离最大化,越难分的数据越有利于SVM的训练,所以对样本的定义比较严格。
2)为什么不直接用softmax的输出结果?
因为在训练softmax的时候数据本来就不是很准确,而SVM的训练使用的是hard negative也就是样本比较严格,所以SVM效果会更好。
4.回归器训练
回归器是线性的,输入为Alexnet pool5的输出。
bbox回归认为候选区域和ground-truth之间是线性关系(因为在最后从SVM内确定出来的区域比较接近ground-truth,这里近似认为可以线性关系)
训练回归器的输入为N对值,{(Pi,Gi)}i=1,2,…,N{(Pi,Gi)}i=1,2,…,N,分别为候选区域的框坐标和真实的框坐标,下面在不必要时省略i。这里选用的Proposal必须和Ground Truth的IoU>0.6才算是正样本.
SPP-net:
是在RCNN之后,是对RCNN的改进
该文章主要改进两点:
- CNN需要固定输入图像的尺寸,导致不必要的精度损失
- R-CNN对候选区域进行重复卷积计算,造成计算冗余
1.为什么CNNs要固定输入图像的尺寸?
CNN主要有两部分组成:卷积层和全连接层。卷积层以滑动窗口方式操作并输出表示各个响应激活空间分布的特征图。实际上,卷积层不需要输入的图像尺寸固定,并且可以产生任意尺寸的特征图。但另一方面,完全连接层需要具有固定大小/长度的输入。 因此,固定输入大小的约束只是来自存在于网络更深层阶段的全连接层。
2.R-CNN为什么会有计算冗余?
如下图所示
R-CNN对于一张图片,先使用segment seletive方法提取出约2000个候选区域,然后将这两千个候选区域分别送入网络中,即一张图片要经历2000次前向传播,这样会造成大量冗余。
SPP-net则提出了一种从候选区域到全图的特征(feature map)之间的对应映射关系,通过此种映射关系可以直接获取到候选区域的特征向量,不需要重复使用CNN提取特征,从而大幅度缩短训练时间。每张图片只需进行一次前向传播即可。
下面来详细讲解一下改进的方法:
1.SPP层(spatial pyramid pooling)
首先要明确的是这一层的位置,这一层加在最后一个卷积层与全连接层之间,目的就是为了输出固定长度的特征传给要求固定输入的全连接层
SPP层的输出:
SPP layer分成1x1,2x2,4x4三个pooling结构(这部分结构如下图所示),对每个输入(这里每个输入大小是不一样的)都作max pooling(论文使用的),出来的特征再连接到一起,就是(16+4+1)x256的特征向量。
无论输入图像大小如何,出来的特征固定是(16+4+1)x256维度。这样就实现了不管图像中候选区域尺寸如何,SPP层的输出永远是(16+4+1)x256特征向量。(简而言之,即是将任意尺寸的feature map用三个尺度的金字塔层分别池化,将池化后的结果拼接得到固定长度的特征向量(图中的256为filter的个数),送入全连接层进行后续操作)
Fast R-CNN
先来回顾一下R-CNN和SPP-net的缺点:
1.R-CNN的缺点
1、训练分为多个阶段。首先要使用search selective算法从输入图像提取约2000个候选区域,其次要训练CNN网络,最后还要训练SVM进行分类、训练bbox回归器进行更为精确的位置定位。
2、训练需要花费大量的时间和空间。因为是分阶段的,CNN将候选区域的特征提取出来以后要都存入硬盘中,之后取出用于训练SVM和bbox回归器,存储特征需要耗费大量的硬盘空间,而且读写过程会造成时间的损耗。
3、检测阶段特别耗时。因为检测时也是对带检测图像中的候选区域进行检测,没个候选区域都要进行前向传播,所以检测一张图像特别耗时。
2.SPP-net的缺点
虽然SPP-net对R-CNN有所改进,即引入了SPP层,使得网络在检测时不需要对每个候选区域进行前向传播,但它也继承了R-CNN的缺点并引入了新的缺点。
类似于R-CNN
1、训练需要分多阶段进行
2、需要将特征存入硬盘
引入的新的缺点:
3、在fune-tuning阶段不能对SPP层下面所有的卷积层进行后向传播(如下图所示)
FAST RCNN:
在Fast R-CNN论文中,在采用VGG16的时候,Conv5_x的输入feature map的spatial size是7x7的,所以在论文中把每个region proposal划分为7x7的网格,那么最终经过RoIPooling输出的feature maps的spatial size为7x7的。RoIPooling跟标准的 max pooling一样,是逐channel的。
Faster RCNN:
Faster RCNN可以说是由两个模块组成的:区域生成网络RPN候选框提取模块+Fast RCNN检测模块.