揭秘深度强化学习
文/ Tambet Matiisen 译/赵屹华,刘翔宇
原作者Tambet Matiisen在文章结尾列出了对本文内容给出意见和建议的读者,以及深入了解这些技术的在线文档和视频链接,受篇幅所限,译文不再赘述。感谢Tambet Matiisen授权《程序员》翻译和刊载。
原文链接:http://neuro.cs.ut.ee/demystifying-deep-reinforcement-learning/
本文为《程序员》文章,未经允许不得转载,更多精彩文章请订阅2016年《程序员》
尽管监督式和非监督式学习的深度模型已经广泛被技术社区所采用,深度强化学习仍旧显得有些神秘。这篇文章将试图揭秘这项技术,并解释其背后的逻辑。受众读者主要是有机器学习或者神经网络背景,却还没来得及深入钻研强化学习技术的朋友。
文章大纲如下:
- 强化学习面临的主要挑战是什么?我们将会在此讨论credit assignment问题和探索-利用的取舍。
- 如何用数学表达式表示强化学习过程?我们将定义马尔科夫决策过程,并用它来解释强化学习过程。
- 该如何构建长期策略?我们定义了“未来回报折扣(discounted future reword)”概念,它构成了下一节算法的基础。
- 如何预测和估计未来回报?我们将会定义并且解释简单的基于表的Q-learning算法。
- 如果状态空间过大了怎么办?我们演示了如何用一个(深度)神经网络模型来替换Q-table算法。
- 在真正使用它之前我们还需要做些什么?我们将会讨论经验重播技术,用神经网络来稳定学习过程。
- 都完成了吗?最后,我们会考虑一些针对探索-利用问题的简单解决方案。
强化学习
我们以Breakout(打砖块)游戏为例。在游戏中,玩家将操控屏幕底部的一块滑板,让球反弹后撞击屏幕上部的砖块,直到所有砖块都破碎。每当球击中了砖块,砖块会消失,玩家的得分会增加——玩家得到了奖励回报。
假设你想训练一个神经网络模型来玩这款游戏。网络的输入将是屏幕图像,输出结果是三种动作:向左、向右和撞击(接住球)。我们可以把它当做一个分类问题——对每一帧屏幕图像,你是需要左移、右移还是撞击。听起来很直白吗?没错,接着你需要,大量的训练样本数据。当然,你可以用专家级玩家的游戏视频作为训练数据,但这不是我们的学习方式。我们不需要外人千百次地告诉我们每一帧图像该选择哪一种操作动作。我们只需要偶尔得到一些正反馈信息,剩下的一切事情我们自己就能搞定。
这就是强化学习试图去解决的任务。强化学习介于监督式学习和非监督式学习之间。监督式学习的每个训练样本都有一个标签,非监督式学习的训练样本没有标签,强化学习的训练样本有稀疏并且时间滞后的标签——即奖励回报。模型仅基于这些奖励回报从环境中学习正确的行为。
尽管概念非常直观,在实际操作中却充满了挑战。举个例子,当你在“打砖块”游戏中击中了砖块并且得到了奖励回报,这个回报往往与最近的几次动作(移动滑板)并没有关联。调整滑板位置、撞击球使其反弹,所有这些复杂工作在得到回报之前早已完成了。这被称为credit assignment问题——也就是说,是由于之前的哪些行为才取得的回报,它们的贡献程度是什么。
当你用某一种策略取得了一定的回报之后,你是打算继续做下去,还是尝试一些可能获得更大回报的方法呢?在上面的“打砖块”游戏中,一种简单的策略就是移到屏幕的左边界等着。球飞向左侧的情况总是比右侧更多些,所以你在游戏结束前总是能很容易地得到大概10分。你对这个成绩已经感到满意了,还是想得到更多?这就是所谓的探索-利用困境——是应该利用好已知有效的方法,还是要发掘其它可能更好的方法。
强化学习是我们(或者所有的动物)如何学习的一种重要模型。来自父母的奖励、在学习取得的成绩、工作的薪水——这些都是回报的形式。Credit assignment问题和探索-利用困境在我们每天的工作和感情生活中都会遇到。因此研究这个问题是十分重要的,游戏组成了一只尝试各种新方法的绝妙沙盒。
马尔科夫决策过程
接下来,问题转化为如何将强化学习问题公式化,使得人能够理解?最常见的一种方法就是将其用马尔科夫决策过程展示。
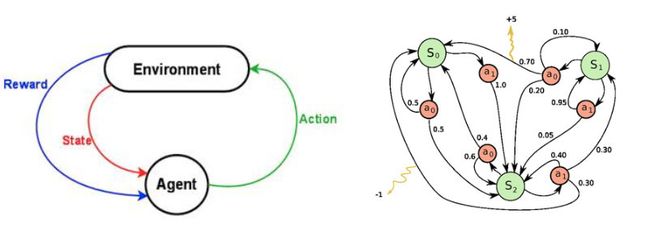
假设你是一位代理者(agent),位于某个环境(environment)中(比如“打砖块”游戏)。这个环境又处在某个特定状态(state)下(比如滑板的位置、球的位置和方向、剩余的砖块等等)。代理者能在环境中执行特定的动作(actions)(比如左移或者右移滑块)。这些动作有时会带来一次回报(reward)(比如得分增加)。每次动作都会转换环境进入到新的状态,代理者又可以执行另一个动作,周而复始。你选择动作的依据可以称为策略(policy)。通常来说环境是随机的,也就是说下一个状态将会随机出现(比如,某一次你没接住球,新发射的球随机出现在某个方向上)。
状态和动作的集合,以及相邻两次转换的规则,构成了马尔科夫决策过程。每一轮过程(如一局游戏)是一系列有限的状态、动作和回报:
这里si表示状态,ai表示动作,ri+1表示执行动作后得到的回报。本轮过程的结束状态为sn(比如“游戏结束”画面)。马尔科夫决策过程依赖于马尔科夫假设,下一个状态si+1的概率仅取决于当前状态si和当前动作ai,与之前的动作和状态无关。
未来回报折扣
为了取得长期良好的表现,我们不仅需要考虑即刻的回报,还有未来将会取得的回报。我们将要如何处理呢?
假定有一次马尔科夫决策过程,我们很容易计算出一轮中取得的所有回报(total reward):
基于此,时间t之后的所有未来回报(total future reward)可以表示为:
但由于我们的环境是随机的,不能保证下次进行同样的动作时候可以得到同样的回报。我们越深入未来,越可能出现分歧。出于这个原因,通常使用未来回报折扣来代替:
其中γ是介于0到1之间的折扣因子——回报越是深入未来,γ值越小。很容易看出,在t时刻的未来回报折扣可以用t+1时刻同样的事情来表示:
如果我们令折扣因子γ=0,那么这种策略将是目光短浅的,我们只依赖于即刻回报。如果我们希望保持即刻回报与未来回报之间的平衡,应该将折扣因子γ设为与0.9近似的值。如果的环境是恒定的,相同的动作总是能够得到同样的回报,那么我们可以把折扣因子设为1。
对于一个agent良好的策略是,总是选择能够使未来回报(折扣)最大化的动作。
Q学习(Q-learning)
在Q学习中,我们定义一个函数Q(s, a),表示在状态s下进行a动作时最大的未来回报折扣,并以此继续优化。
Q(s, a)可以理解为“在状态s下进行a操作之后,游戏结束时可能最大的得分”。它之所以称为Q函数,是因为表示的是在某一状态下执行某一操作时候的“质量”。
这听起来可能令人费解。只知道当前的状态和动作,不知道后来的动作和回报,我们如何估计最后的分数呢?其实我们不能。只不过作为一个理论构想,我们假设存在这么一个函数。只要闭上眼睛,嘴里默念五遍:“Q(s, a)存在,Q(s, a)存在……”感受到了吗?
如果你存有疑虑,那么想想有这么一个函数会带来什么。假设你在某个状态下不知道是否执行a动作还是b动作。你想选择结束时有最高得分的那个动作。一旦你使用了神奇的Q函数,那么答案就相当简单——选择Q值最高的那个动作。
其中π表示策略,我们在每个状态下如何选择动作。
好了,那么我们如何得到Q函数呢?现在我们只来关注一个转换< s, a, r, s’>。与上一节的未来回报折扣一样,可以用下一个状态s’的Q值来表示s状态下执行a动作时的Q值。
这被称为贝尔曼方程。如果你仔细思考,会发现这很合乎逻辑——对于当前状态和动作的最大未来回报是即刻回报加上下一个状态的最大未来回报。
Q学习的主要思想是,我们可以使用贝尔曼方程迭代逼近Q函数。在最简单的情况下,Q函数用一个表来实现,状态作为行,动作作为列。Q学习算法的要点很简单,如下:
initialize Q[numstates,numactions]
arbitrarily
observe initial state s
repeat
select and carry out an action a
observe reward r and new state s'
Q[s,a] = Q[s,a] + α(r + γmaxa'
Q[s',a'] - Q[s,a])
s = s'
until terminated算法中的α表示的是学习率,它控制着考虑多少之前Q值和新计算的Q值之间的不同。特别地,当α=1时,那么取消两个Q[s, a],剩下的与贝尔曼方程就是一样的了。
我们用来更新Q[s, a]的maxa ‘Q[s’,a’]只是一个近似值,而且在学习的早期可能完全是错误的。但是,随着每次迭代,这个近似值会越来越准确,这已经得到证明了,如果我们执行这种更新足够多的话,那么Q函数会收敛并代表真正的Q值。
深度Q网络
打砖块游戏的环境状态可以由球拍位置,球的位置和方向,以及是否有砖块来定义。这种直观的表示是一个游戏特有的。我们可以用更为通用的方式来表示所有游戏吗?很明显可以选择屏幕像素——它们包含了所有关于游戏状况的相关信息,除了球的速度和方向。两个连续的屏幕也包含这些信息。
如果我们把在DeepMind论文中提到的相同预处理方式运用于游戏屏幕上——取最后四个屏幕图像,大小调整为84×84,然后用256级灰度转换成灰度图像——我们会得到25684x84x4≈ 1067970种可能的游戏状态。这意味着假想Q表中有1067970行——比宇宙已知的原子数还要多!有人可能会说,许多像素组合(因此状态也是)永远不会出现——我们完全可以用一张稀疏表来表示已访问的状态。即便如此,大多数状态很少被访问,Q表收敛就要等到天荒地老了。理想情况下,我们会对从未见过的状态猜测它的Q值。
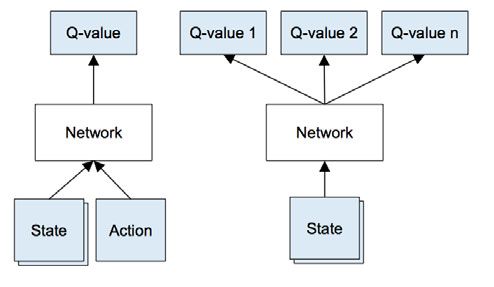
此时深度学习就有用武之地了。神经网络非常适合对高度结构化的数据进行特征提取。我们可以用神经网络来表示Q函数,状态(四个游戏屏幕)和动作作为输入,并输出对应的Q值。或者,可以只将游戏屏幕作为输入,并对每个可能的动作输出Q值。这种方法的优点是,如果想要更新Q值或是选择有最高Q值的动作,只需要在网络中进行简单的一步,就能够立刻得到对于所有动作的所有Q值。
DeepMind使用的网络架构如下: 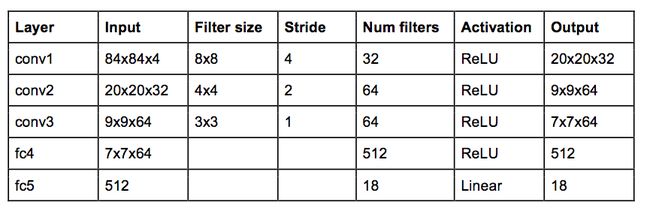
这是一个经典的卷积神经网络,有三个卷积层,之后是两个全连接层。对于熟悉物体识别网络的人,可能会注意到这里没有池化层。但如果仔细想想,池化层保证了转换不变性——网络对图像中物体的位置不敏感。这对类似于ImageNet的分类任务来说意义非凡,但是对于游戏来说,球的位置对于确定潜在回报至关重要,我们不希望丢弃这个信息!
网络的输入是4个84×84的灰度游戏屏幕图像。网络的输出是每个可能动作(Atari中的18个)的Q值。Q值可以是任何实数,这样就可以使用回归,通过简单的平方误差损失进行优化。
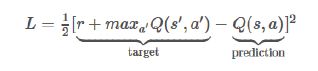
给定一个转换< s, a, r, s’>,之前算法中Q表的更新法则需要替换成:
1、对于当前状态s进行前馈操作,得到所有动作的预测Q值。
2、对于下一个状态s’进行前馈操作,并计算所有网络输出的最大值maxa’ Q(s’, a’)。
3、将针对某个动作的Q值设定为r+γmaxa’ Q(s’,a’)(使用步骤2中计算出的最大值)。对于其他的动作,将Q值设定为步骤1中的Q值,对于这些输出把误差设为0。
4、使用反向传播更新权值。
经验重播(Experience Replay)
现在,我们已经知道了如何使用Q学习来估计每个状态下未来回报,以及使用卷积神经网络来逼近Q函数。但事实证明,使用非线性函数的Q值近似不是那么稳定。让它收敛有很多种方法。这也相当耗时,使用一块GPU大概要花一个星期。
最重要的诀窍是经验重播。在游戏中,所有的经验< s, a, r, s’>被存储在重播内存中。在训练网络时,从重播内存中随机使用小批次,代替多数最近的转换。这打破了后续训练样本的相似性,这可能会导致网络陷入局部最小中。经验重播使得训练任务与常规的监督式学习非常相像,简化了算法的调试和测试。可以从人类玩家中获取所有的经验来训练网络。
探索 - 利用(Exploration-Exploitation)
Q学习试图解决credit assignment问题——它及时将回报传播,直到达到关键决策点,这个点就是得到回报的实际原因。但是我们还没踏入探索-利用困境……
首先观察到的是,当Q表或是Q网络被随机初始化,那么它的预测最初也是随机的。如果我们选择具有最高Q值的动作,这个动作将是随机的,agent将执行粗“探索”。当Q函数慢慢收敛,它返回更为连续的Q值,探索量也随之减少。有人就会这说,Q学习结合了探索作为算法的一部分。但是这种探索是“贪婪”的,它由它碰到的第一个有效策略决定。
解决上述问题的一个简单而有效的方式是使用ε贪婪探索——有ε的概率选择随机动作,否则“贪婪”选择Q值最高的动作。在他们的系统中,DeepMind实际上让ε随着时间从1降低至0.1——在开始的时候系统完全进行随机移动来最大限度地探索状态空间,然后它会降低到一个固定的探索率。
深度Q学习算法
下面是使用经验重播的深度Q学习算法:
initialize replay memory D
initialize action-value function Q with
random weights
observe initial state s
repeat
select an action a
with probability ε select a
random action
otherwise select a =
argmaxa’Q(s,a,)
carry out action a
observe reward r and new state s,
store experience in
replay memory D
sample random transitions from replay memory D
calculate target for each minibatch
transition
if ss, is terminal state then tt
= rr
otherwise tt = rr +
γmaxa’Q(ss,, aa,)
train the Q network using (tt -
Q(ss, aa))^2 as loss
s = s'
until terminated DeepMind使用了很多诀窍来让它起作用——比如目标网络(target network)、误差剪裁(error clipping)、回报剪裁(reward clipping)等,但这些都不在本文讨论范围。
这个算法最惊人的部分是,它可以学习任何东西。试想一下——因为我们的Q函数随机初始化,它最开始输出的全是垃圾。我们使用这些垃圾(下一个状态的最大Q值)作为网络的目标,偶尔加入微小的回报。这听起来很疯狂,它怎么可能学习到任何有意义的东西?事实是,它就是可以。
订阅程序员(含iOS、Android及印刷版)请访问 http://dingyue.programmer.com.cn 
订阅咨询:
• 在线咨询(QQ):2251809102
• 电话咨询:010-64351436
• 更多消息,欢迎关注“程序员编辑部”