ACL 2017自然语言处理精选论文
作者简介:洪亮劼,Etsy数据科学主管,前雅虎研究院高级经理。长期从事推荐系统、机器学习和人工智能的研究工作,在国际顶级会议上发表论文20余篇,长期担任多个国际著名会议及期刊的评审委员会成员和审稿人。
责编:何永灿([email protected])
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅《程序员》
涉及自然语言处理、人工智能、机器学习等诸多理论以及技术的顶级会议——第55届计算语言学年会(The 55th Annual Meeting of the Association for Computational Linguistics,简称ACL会议)于今年7月31日-8月4日在加拿大温哥华举行。从近期谷歌学术(Google Scholar)公布的学术杂志和会议排名来看,ACL依然是最重要的自然语言处理相关的人工智能会议。因为这个会议的涵盖面非常广泛,且理论文章较多,一般的读者很难从浩如烟海的文献中即刻抓取到有用信息,这里笔者从众多文章中精选出5篇有代表性的文章,为读者提供思路。
Multimodal Word Distributions
摘要:本文的核心思想为如何用Gaussian Mixture Model来对Word Embedding进行建模,从而可以学习文字的多重表达。这篇文章值得对Text Mining有兴趣的读者泛读。
文章作者Ben Athiwaratkun是康奈尔大学统计科学系的博士生。Andrew Gordon Wilson是新加入康奈尔大学Operation Research以及Information Engineering的助理教授,之前在卡内基梅隆大学担任研究员,师从Eric Xing和Alex Smola教授,在之前,其在University of Cambridge的Zoubin Ghahramani手下攻读博士学位。
这篇文章主要研究Word Embedding,其核心思想是想用Gaussian Mixture Model表示每一个Word的Embedding。最早的自然语言处理(NLP)是采用了One-Hot-Encoding的Bag of Word的形式来处理每个字。这样的形式自然是无法抓住文字之间的语义和更多有价值的信息。那么,之前Word2Vec的想法则是学习一个每个Word的Embedding,也就是一个实数的向量,用于表示这个Word的语义。当然,如何构造这么一个向量又如何学习这个向量成为了诸多研究的核心课题。
在ICLR 2015会议上,来自UMass的Luke Vilnis和Andrew McCallum在“Word Representations via Gaussian Embedding”文章中提出了用分布的思想来看待这个实数向量的思想。具体说来,就是认为这个向量是某个高斯分布的期望,然后通过学习高斯分布的参数(也就是期望和方差)来最终学习到Word的Embedding Distribution。这一步可以说是扩展了Word Embedding这一思想。然而,用一个分布来表达每一个字的最直接的缺陷则是无法表达很多字的多重意思,这也就带来了这篇文章的想法。文章希望通过Gaussian Mixture Model的形式来学习每个Word的Embedding。也就是说,每个字的Embedding不是一个高斯分布的期望了,而是多个高斯分布的综合。这样,就给了很多Word多重意义的自由度。在有了这么一个模型的基础上,文章采用了类似Skip-Gram的来学习模型的参数。具体说来,文章沿用了Luke和Andrew的那篇文章所定义的一个叫Max-margin Ranking Objective的目标函数,并且采用了Expected Likelihood Kernel来作为衡量两个分布之间相似度的工具。这里就不详细展开了,有兴趣的读者可以精读这部分细节。
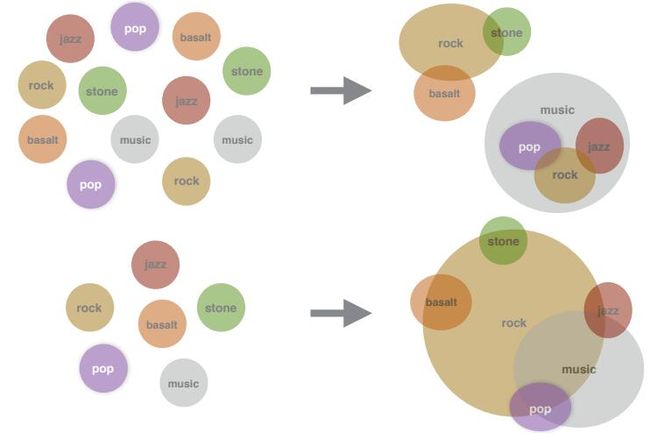
文章通过UKWAC和Wackypedia数据集学习了所有的Word Embedding。所有试验中,文章采用了K=2的Gaussian Mixture Model(文章也有K=3的结果)。比较当然有之前Luke的工作以及其他各种Embedding的方法,比较的内容有Word Similarity以及对于Polysemous的字的比较。总之,文章提出的方法非常有效果。这篇文章因为也有源代码(基于Tensorflow),推荐有兴趣的读者精读。
Topically Driven Neural Language Model
摘要:文章的核心思想,也是之前有不少人尝试的,就是把话题模型(Topic Model)和语言模型(Language Model)相结合起来。这里,两种模型的处理都非常纯粹,是用“地道”的深度学习语言构架完成。用到了不少流行的概念(比如GRU、Attention等),适合文字挖掘的研究人员泛读。
文章的作者是来自于澳大利亚的研究人员。第一作者Jey Han Lau目前在澳大利亚的IBM进行Topic Model以及NLP方面的研究,之前也在第二作者Timothy Baldwin的实验室做过研究。第二作者Timothy Baldwin和第三作者Trevor Cohn都在墨尔本大学长期从事NLP研究的教授。
这篇文章的核心思想是想彻底用Neural的思想来结合Topic Model和Language Model。当然,既然这两种模型都是文字处理方面的核心模型,自然之前就有人曾经想过要这么做。不过之前的不少尝试都是要么还想保留LDA的一些部件或者往传统的LDA模型上去靠,要么是并没有和Language Model结合起来。
文章的主要卖点是完全用深度学习的“语言”来构建整个模型,并且模型中的Topic Model模型部分的结果会成为驱动Language Model部分的成分。概括说来,文章提出了一个有两个组成部分的模型的集合(文章管这个模型叫tdlm)。

第一个部分是Topic Model的部分。我们已经提过,这里的Topic Model和LDA已相去甚远。思路是这样的,首先,从一个文字表达的矩阵中(有可能就直接是传统的Word Embedding),通过Convolutional Filters转换成为一些文字的特征表达(Feature Vector)。文章里选用的是线性的转换方式。这些Convolutional Filters都是作用在文字的一个Window上面,所以从概念上讲,这一个步骤很类似Word Embedding。得到这些Feature Vector以后,作者们又使用了一个Max-Over-Time的Pooling动作(也就是每一组文字的Feature Vector中最大值),从而产生了文档的表达。注意,这里学到的依然是比较直接的Embedding。然后,作者们定义了一组Topic的产生形式。首先,是有一个“输入Topic矩阵”。这个矩阵和已经得到的文档特征一起,产生一个Attention的向量。这个Attention向量再和“输出Topic矩阵”一起作用,产生最终的文档Topic向量。这也就是这部分模型的主要部分。
最终,这个文档Topic向量通过用于预测文档中的每一个字来被学习到。有了这个文档Topic向量以后,作者们把这个信息用在了一个基于LSTM的Language Model上面。这一部分,其实就是用了一个类似于GRU的功能,把Topic的信息附加在Language Model上。文章在训练的时候,采用了Joint训练的方式,并且使用了Google发布的Word2Vec已经Pre-trained的Word Embedding。所采用的种种参数也都在文章中有介绍。
文章在一些数据集上做了实验。对于Topic部分来说,文章主要和LDA做比较,用了Perplexity这个传统的测量,还比较了Topic Coherence等。总体说来,提出的模型和LDA不相上下。从Language Model的部分来说,提出的模型也在APNews、IMDB和BNC上都有不错的Perplexity值。总体说来,这篇文章值得文字挖掘的研究者和NLP的研究者泛读。
Towards End-to-End Reinforcement Learning of Dialogue Agents for Information Access
摘要:文章介绍如何进行端到端(End-to-End)的对话系统训练,特别是有数据库或者知识库查询步骤的时候,往往这一步“硬操作”阻止了端到端的训练流程。这篇文章介绍了一个“软查询”的步骤,使得整个流程可以能够融入训练流程。不过从文章的结果来看,效果依然很难说能够在实际系统中应用。可以说这篇文章有很强的学术参考价值。
文章作者群来自于微软研究院、卡内基梅隆大学和台湾国立大学。文章中还有Lihong Li和Li Deng(邓力)这样的著名学者的影子。第一作者Bhuwan Dhingra是在卡内基梅隆大学William W. Cohen和Ruslan Salakhutdinov的博士学生,两位导师都十分有名气。而这个学生这几年在NLP领域可以说是收获颇丰:在今年的ACL上已经发表2篇文章,在今年ICLR和AAAI上都有论文发表。
文章的核心思想是如何训练一个多轮(Multi-turn)的基于知识库(Knowledge Base)的对话系统。这个对话系统的目的主要是帮助用户从这个知识库中获取一些信息。那么,传统的基于知识库的对话系统的主要弊病在于中间有一个步骤是对于“知识库的查询”。也就是说,系统必须根据用户提交的查询(Query),进行分析并且产生结果。这一步,作者们称为“硬查询”(Hard-Lookup)。虽然这一步非常自然,但是阻断了(Block)了整个流程,使得整个系统没法“端到端”(End-to-End)进行训练。并且,这一步由于是“硬查询”,并没有携带更多的不确定信息,不利于系统的整体优化。
这篇文章其实就是想提出一种“软查询”,从而让整个系统得以“端到端”(End-to-End)进行训练。这个新提出的“软查询”步骤,和强化学习(Reinforcement Learning)相结合,共同完成整个回路,从而在这个对话系统上达到真正的“端到端”。这就是整个文章的核心思想。那么,这个所谓的“软查询”是怎么回事?其实就是整个系统保持一个对知识库中的所有本体(Entities)所可能产生的值的一个后验分布(Posterior Distribution)。也就是说,作者们构建了这么一组后验分布,然后可以通过对这些分布的更新(这个过程是一个自然获取新数据,并且更新后验分布的过程),来对现在所有本体的确信度有一个重新的估计。这一步的转换,让对话系统从和跟知识库直接打交道,变成了如何针对后验分布打交道。
显然,从机器学习的角度来说,和分布打交道往往容易简单很多。具体说来,系统的后验分布是一个关于用户在第T轮,针对某个值是否有兴趣的概率分布。整个对话系统是这样运行的。首先,用户通过输入的对话(Utterance)来触发系统进行不同的动作(Action)。动作空间(Action Space)包含向用户询问某个Slot的值,或者通知用户目前的结果。
整个系统包含三个大模块: Belief Trackers、Soft-KB Lookup,以及Policy Network。Belief Trackers的作用是对整个系统现在的状态有一个全局的掌握。这里,每一个Slot都有一个Tracker,一个是根据用户当前的输入需要保持一个对于所有值的Multinomial分布,另外的则是需要保持一个对于用户是否知道这个Slot的值的置信值。文章中介绍了Hand-Crafted Tracker和Neural Belief Tracker(基于GRU)的细节,这里就不复述了。有了Tracker以后,Soft-KB Lookup的作用是保持一个整个对于本体的所有值得后验分布。最后,这些后验概率统统被总结到了一个总结向量(Summary Vector)里。这个向量可以认为是把所有的后验信息给压缩到了这个向量里。而Policy Network则根据这个总结向量,来选择整个对话系统的下一个动作。这里文章也是介绍了Hand-Crafted的Policy和Neural Policy两种情况。整个模型的训练过程还是有困难的。
虽然作者用了REINFORCE的算法,但是,作者们发现根据随机初始化的算法没法得到想要的效果。于是作者们采用了所谓的Imitation Learning方法,也就是说,最开始的时候去模拟Hand-Crafted Agents的效果。
在这篇文章里,作者们采用了模拟器(Simulator)的衡量方式。具体说来,就是通过与一个模拟器进行对话从而训练基于强化学习的对话系统。作者们用了MovieKB来做数据集。总体说来整个实验部分都显得比较“弱”。没有充足的真正的实验结果。整个文章真正值得借鉴主要是“软查询”的思想,整个流程也值得参考。但是训练的困难可能使得这个系统作为一个可以更加扩展的系统的价值不高。本文值得对对话系统有研究的人泛读。
Learning to Skim Text
摘要:这篇文章主要介绍如何在LSTM的基础上加入跳转机制,使得模型能够去略过不重要的部分,而重视重要的部分。模型的训练利用了强化学习。这篇文章建议对文字处理有兴趣的读者精读。
作者群来自Google。第一作者来自卡内基梅隆大学的Adams Wei Yu在Google实习的时候做的工作。第三作者Quoc V. Le曾是Alex Smola和Andrew Ng的高徒,在Google工作期间有很多著名的工作,比如Sequence to Sequence Model来做机器翻译(Machine Translation)等。
文章想要解决的问题为“Skim Text”。简单说来,就是在文字处理的时候,略过不重要的部分,对重要的部分进行记忆和阅读。要教会模型知道在哪里需要略过不读,哪里需要重新开始阅读的能力。略过阅读的另外一个好处则是对文字整体的处理速度明显提高,而且很有可能还会带来质量上的提升(因为处理的噪声信息少了、垃圾信息少了)。
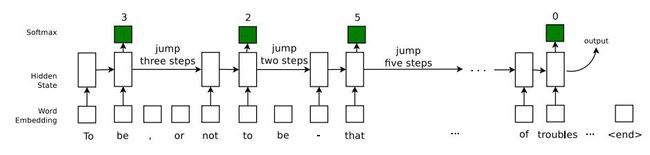
具体说来,文章是希望在LSTM的基础上加入“跳转”功能,从而使得这个时序模型能够有能力判读是否要略过一部分文字信息。简单说来,作者们是这么对LSTM进行改进的。首先,有一个参数R来确定要读多少文字。然后模型从一个0到K的基于Multinomial分布的这一个跳转机制中决定当前需要往后跳多少文字(可以是0,也就是说不跳转)。这个是否跳转的这一个步骤所需要的Multinomial分布,则也要基于当期LSTM的隐参数信息(Hidden State)。跳转决定以后,根据这个跳转信息,模型会看一下是否已经达到最大的跳转限制N。如果没有则往后跳转。当所有的这些步骤都走完,达到一个序列(往往是一个句子)结尾的时候,最后的隐参数信息会用来对最终需要的目标(比如分类标签)进行预测。
文章的另一个创新点,就是引入了强化学习(Reinforcement Learning)到模型的训练中。最终从隐参数到目标标签(Label)的这一步往往采用的是Cross Entropy的优化目标函数。这一个选择很直观,也是一个标准的步骤。然而,如何训练跳转的Multinomial分布,因为其离散(Discrete)特质,则成为文章的难点。原因是Cross Entropy无法直接应用到离散数据上。那么,这篇文章采取的思路是把这个问题构造成为强化学习的例子,从而使用最近的一些强化学习思路来把这个离散信息转化为连续信息。具体说来,就是采用了Policy Gradient的办法,在每次跳转正确的时候,得到一个为+1的反馈,反之则是-1。这样就把问题转换成为了学习跳转策略的强化学习模式。文章采用了REINFORCE的算法来对这里的离散信息做处理。从而把Policy Gradient的计算转换为了一个近似逼近。这样,最终的目标函数来自于三个部分:第一部分是Cross Entropy,第二部分是Policy Gradient的逼近,第三部分则是一个Variance Reduction的控制项(为了优化更加有效)。整个目标函数就可以完整得被优化了。
文章在好多种实验类型上做了实验,主要比较的就是没有跳转信息的标准的LSTM。其实总体上来说,很多任务(Task)依然比较机械和人工。比如最后的用一堆句子,来预测中间可能会出现的某个词的情况,这样的任务其实并不是很现实。但是,文章中提到了一个人工(Synthetic)的任务还蛮有意思,那就是从一个数组中,根据下标为0的数作为提示来跳转取得相应的数作为输出这么一个任务。这个任务充分地展示了LSTM这类模型,以及文章提出的模型的魅力:第一,可以非常好的处理这样的非线性时序信息,第二,文章提出的模型比普通的LSTM快不少,并且准确度也提升很多。
总体说来,这篇文章非常值得对时序模型有兴趣的读者精读。文章的“Related Work”部分也很精彩,对相关研究有兴趣的朋友可以参考这部分看看最近都有哪些工作很类似。
From Language to Programs: Bridging Reinforcement Learning and Maximum Marginal Likelihood
摘要:这篇文章要解决的问题是如何从一段文字翻译成为“程序”的问题,文章适合对Neural Programming有兴趣的读者泛读。
作者群来自斯坦福大学。主要作者来自Percy Liang的实验室。最近几年Percy Liang的实验室可以说收获颇丰,特别是在自然语言处理和深度学习的结合上都有不错的显著成果。
这篇文章里有好一些值得关注的内容。首先从总体上来说,这篇文章要解决的问题是如何从一段文字翻译成为“程序”的问题,可以说是一个很有价值的问题。如果这个问题能够可以容易解决,那么我们就可以教会计算机编写很多程序,而不一定需要知道程序语言的细微的很多东西。从细节上说,这个问题就是给定一个输入的语句,一个模型需要把目前的状态转移到下一个目标状态上。难点在于,对于同一个输入语句,从当前的状态到可能会到达多种目标状态。这些目标状态都有可能是对当前输入语句的一种描述。但是正确的描述其实是非常有限的,甚至是唯一的。那么,如何从所有的描述中,剥离开不正确的,找到唯一的或者少量的正确描述,就成为了这么一个问题的核心。
文章中采用了一种Neural Encoder-Decoder模型架构。这种模型主要是对序列信息能够有比较好的效果。具体说来,是对于现在的输入语句,首先把输入语句变换成为一个语句向量,然后根据之前已经产生的程序状态,以及当前的语句向量,产生现在的程序状态。在这个整个的过程中,对于Encoder作者们采用了LSTM的架构,而对于Decoder作者们采用了普通的Feed-forward Network(原因文章中是为了简化)。
另外一个比较有创新的地方就是作者们把过于已经产生程序状态重新Embedding化(作者们说是叫Stack)。这有一点模仿普通数据结构的意思。那么,这个模型架构应该是比较经典的。文章这时候引出了另外一个本文的主要贡献,那就是对模型学习的流程进行了改进。为了引出模型学习的改进,作者们首先讨论了两种学习训练模式的形式,那就是强化学习(Reinforcement Learning)以及MML(Maximum Marginal Likelihood)的目标函数的异同。文章中提出两者非常类似,不过比较小的区别造成了MML可以更加容易避开错误程序这一结果。文章又比较了基于REINFORCE算法的强化学习以及基于Numerical Integration以及Beam Search的MML学习的优劣。总体说来,REINFORCE算法对于这个应用来说非常容易陷入初始状态就不太优并且也很难Explore出来的情况。MML稍微好一些,但依然有类似问题。文章这里提出了Randomized Beam Search来解决。也就是说在做Beam Search的时候加入一些Exploration的成分。另外一个情况则是在做Gradient Updates的时候,当前的状态会对Gradient有影响,也就是说,如果当前状态差强人意,Gradient也许就无法调整到应该的情况。这里,作者们提出了一种叫Beta-Meritocratic的Gradient更新法则,来解决当前状态过于影响Gradient的情况。
实验的部分还是比较有说服力的,详细的模型参数也一应俱全。对于提出的模型来说,在三个数据集上都有不错的表现。当然,从准确度上来说,这种从文字翻译到程序状态的任务离真正的实际应用还有一段距离。这篇文章适合对于最近所谓的Neural Programming有兴趣的读者泛读。对怎么改进强化学习或者MML有兴趣的读者精读。文章的“Related Work”部分也是非常详尽,有很多工作值得参考。
论文下载链接:
- Multimodal Word Distributions
- Topically Driven Neural Language Model
- Towards End-to-End Reinforcement Learning of Dialogue Agents for Information Access
- Learning to Skim Text
- From Language to Programs: Bridging Reinforcement Learning and Maximum Marginal Likelihood
相关阅读:
- WWW 精选论文
- WSDM 精选论文解读
- NIPS 十大机器学习精选论文
- ICML 精选论文
- SIGIR 信息检索精选论文
- WWW 2017 精选论文
- 知人知面需知心——论人工智能技术在推荐系统中的应用
