大规模数据处理实战--总体概述
目录
Map-Reduce淘汰的原因
MapReduce的替代者
大规模电商热销榜
大规模数据处理工具出现的年代

到2014年谷歌内部没人用Map-Reduce了
2016年谷歌内部培训中,把Map-Reduce替换成了FlumJava
Map-Reduce淘汰的原因
1.高昂的维护成本
预测美团的股价,其中一个重要特征是活跃在街头的美团外卖电动车数量
在真实的环境下,至少需要10个MapReduce任务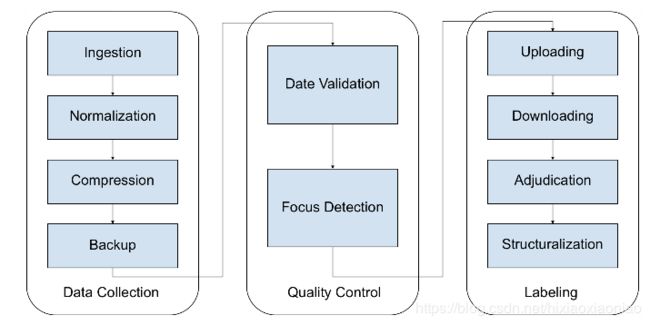
首先,需要收集每日的外卖电动车图片
数据的搜集往往不是公司独立完成,许多公司会选择部分外包或者众包,在数据收集(Data collection)部分,至少需要4个MapReduce任务
1.数据导入(data ingestion),从来把散落的照片,如众包公司上传到网盘的照片,下载到存储系统
2.数据统一化(compression),用来把不同外包公司提供过来的各式各样的照片进行格式统一
3.数据压缩(compression),需要在质量可接受的范围内保持最小的存储资源消耗
4.数据备份(backup),大规模的数据处理系统我们都需要一定的数据冗余来降低风险
第二步需要做数据的质量控制(quality control)流程
1.数据时间有效性验证(data validation),检测上传的图片是否是你想要的日期的
2.照片对焦检测(focus detection),需要筛选掉那些因对焦不准而无法使用的照片
最后才是重头戏,找到这些图片里的外卖电动车
1.数据标注问题上传(question uploading),上传你的标注工具,让你的标注着开始工作
2.标注结果下载(answer downloading),抓取标注完的数据
3.标注异议整合(adjudication),标注异议经常发生,比如争议一个电动车是美团还是京东的
4.标注结果结构化(structuralization),要让标注结果可用,需要把可能非结构化的标注结果转换成存储系统接受的结构
真实的商业MapReduce场景极端复杂,像上面这样的10个子任务的MapReduce系统在硅谷很常见
2.时间上不达标
分片,是指把大规模的数据分配给不同的机器/工人
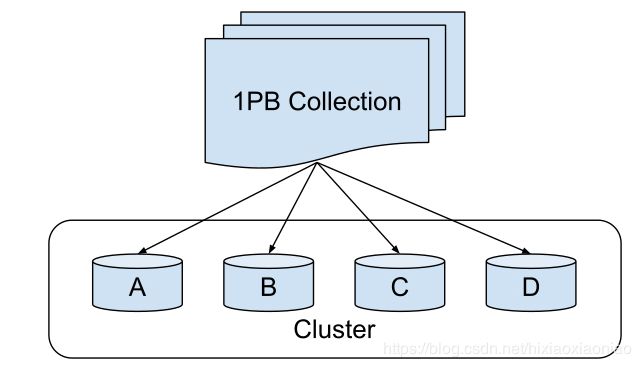
分片函数选择不好,会导致数据倾斜
比如按年龄段分配用户,但facebook的20-30岁用户最多
导致发生掉队问题(stragglers),别的机器都完成了Reduce阶段,一些机器还在工作
通过MapReduce的性能剖析,可以发现掉队的机器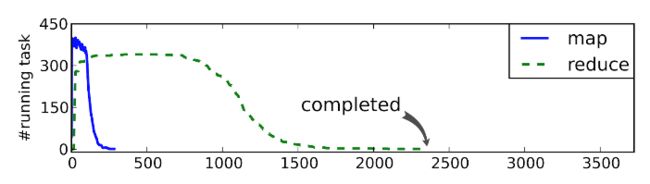
MapReduce的替代者
谷歌等公司对于技术选择非常严格,一个能成为默认方案的技术至少满足如下条件
1.经受了众多产品线,超大规模数据量的考验
2.自发的被众多内部开发者采用,简单易用而受开发者欢迎
3.能够通过内部领域专家评审
4.比上一代技术提高10%是不够的,必须有显著的提高如70%的提高
未来的MapRecude设计上需要解决的问题
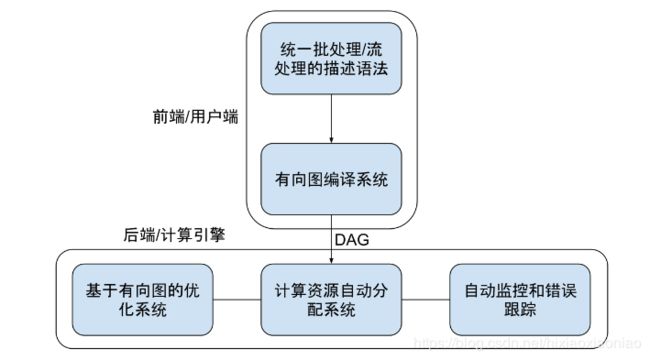
1.需要一种技术让多步骤数据处理变得易于维护
这里可以采用有向无环图DAG的结构
为了协调各种Map和Reduce需要做各种检查,系统不堪重负
采用有向图建模,图中每一个节点都可以被抽象的表达成一种通用的数据集
每一条边都被表达成通用的数据变换
可以用数据集和数据变换描述极为宏大复杂的数据处理流程
2.不需要复杂的配置,可以自动进行性能优化
3.把数据处理的描述语言,和背后的运行引擎耦合开来
这类似 通过HTTP完成通讯,将两端的实现解耦
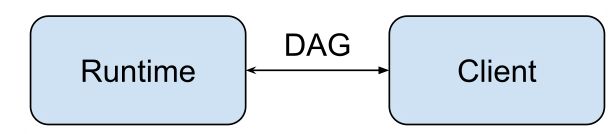
在TensorFlow的设计中,客户端可以使用任何语言,运行引起理论上可以在任何地方运行
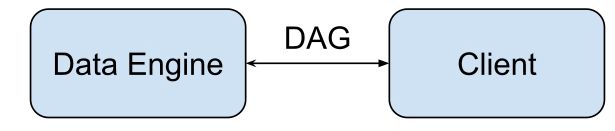
对于数据处理也是一样,有向图表达心意数据处理描述语言和运行引协商一致,其他的实现都是可以扩展的
4.统一批处理和流处理的编程模型
流处理是无界连续的数据
批处理是有界离散的数据
MapReduce的局限是它是为批处理而设计的,应对流处理就不再得心应手
Apache Strom,Apache Flink也有类似的问题
Flink的批处理数据结构用Data Set,但流处理用DataStream
需要统一API,将这两个模型统一
5.需要在架构层面提供异常处理和数据监控的能力
通过上述分析,新的数据处理框架基本模型应该是下面这样的
大规模电商热销榜
求10亿个商品销售的topK
对于小规模问题,可以先用hash计算每个商品的销售次数
在用TopK算法计算出销售的前K名词
小规模算法如果用到了大规模问题上,会出现两个问题
1.内存占用
2.中间结果放到磁盘上的I/O等待问题
大规模处理思路
找1000台机器,每台几次一次处理1W条记录,这样每台机器的处理方式又回归到了传统算法
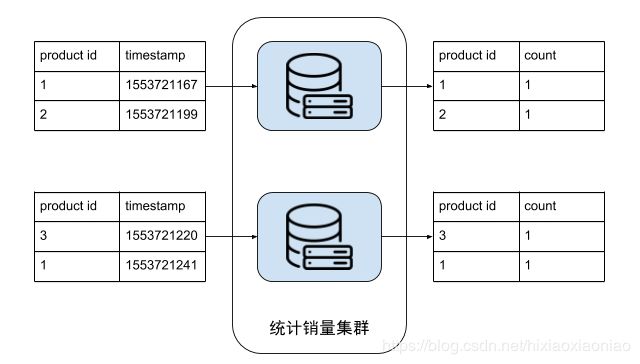
计算topK,把统计销量集群得到的数据输出,作为这个处理流的输入,
把product_id=1的销量全部叠加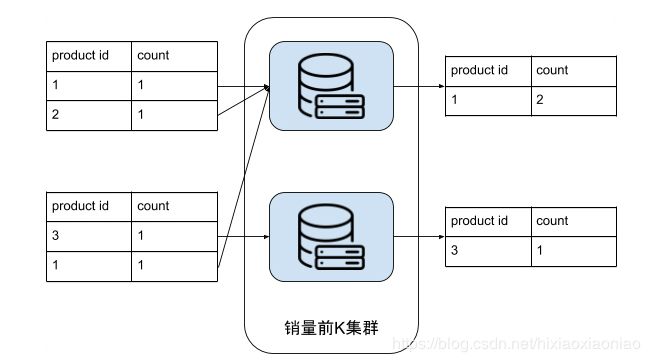
汇总结果因为数据量不大,可以用单机解决
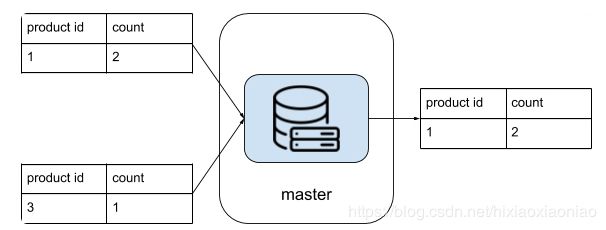
大规模处理框架有两个基本需求
1.高度抽象数据处理流程描述语言,作为框架使用者,最好能用几行代码就把业务逻辑描述清楚
2.自动化的任务分配优化,这个框架背后的引擎需要足够智能,把原来手动配置的系统进行自动任务分配
对于上面的场景,计算销售统计计算集群,可以这么写代码
sales_count = sale_records.Count()
top_k_sales = sales_count.TopK(k)