堆漏洞
1.堆结构介绍
堆是供程序使用的虚拟空间之一
程序未运行时,并不知道需要多少的虚拟空间 来运行程序。
在程序运行过程中,往往伴随着大量申请和释 放内存的操作,为了更好的管理内存空间的使 用和提高程序运行效率,需要专门对内存进行 管理。

常见的内存管理库有:
tcmalloc:谷歌开源的内存管理库
jemalloc:FreeBSD开发人员所开发
ptmalloc&ptmalloc 2:基于dlmalloc 2.7.x开发
ptmalloc中,实现了malloc()、free()和 其他函数以对内存进行管理。
glibc使用ptmalloc对内存空间进行管理, 在2.3.x版本后集成了ptmalloc 2。
ptmalloc中用户请求的空间由chunk这一 数据结构来表示:


结构中头部是前向指针的堆块的大小,第二个是本块的大小,这些是系统使用的。
中间mem是自己能够使用的:链表中前后的chunk的地址,还有一个是用户空间。
chunk指针指向的是chunk的起始位置
但这个位置并不是用户能够写入或读取的起始位置
在已分配的chunk中,用户实际使用的区域从mem 指针指向的区域开始。
一个chunk(未分配的)中的信息从上往下依次是 前一个chunk的大小
本chunk的大小(最低位,图中P表示前一个chunk是否 处于使用中)
链表中前一个chunk的地址 链表中后一个chunk的地址
注:在large bin中的chunk还有两个指针用于加速在 large bin中查找最近匹配的空闲chunk。
在ptmalloc中,为了节省空间,对chunk 进行了空间复用:
当一个chunk处于使用中时,它的下一个 chunk的第一个域(即用于记录前一个chunk 的大小的区域)是无效的,因此这个域可以被当前的chunk所使用。
在用户申请内存空间时,会对用户所需的 空间大小进行处理后再进行空间分配:
ptmalloc依赖平台对size_t的定义进行地址对 齐
32位平台size_t长度为4字节
64位平台的size_t长度可能是4字节,也可能 是8字节
64位Linux平台size_t长度为8字节
2.堆管理方式介绍
ptmalloc采用bin来对空闲的chunk进行管理。
bin是一种记录空闲chunk的链表数据结构,是一 个将chunk连接起来的链表,它根据chunk的大 小进行管理,共四类:
fast bin
unsorted bin
small bin
large bin
当chunk被释放时,ptmalloc会将属于chunk根 据一定的规则放入相应的bin中。
在glibc中用于记录bin的数据结构有两种, 分别如下所示:
fastbinsY: 这是一个数组,用于记录所有的 fast bins;
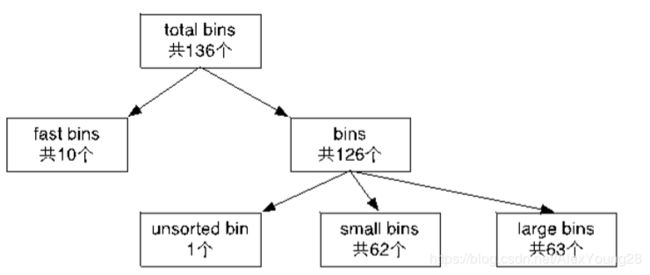
bins: 这也是一个数组,用于记录除fast bins 之外的所有bins。 一共有126个bins
ptmalloc使用bins数组来维护bin:
bins[1]为unsorted bin
bins[2-63]为small bin
bins[64-126]为large bin
使用fastbinY数组来维护fast bin。
这些bin都位于libc中,因此可以利用链表的 结构在特定条件下泄漏libc地址。


(1)main_arena
这是主分配区。每个进程只有一个主分配区,可有多个非主分配区。
程序每次申请内存时,都要对主分配区加锁,在多 线程环境下,对主分配区的竞争可能会非常激烈, 因此在ptmalloc中加入了非主分配区来提高malloc 的效率
主分配区能够访问进程的heap和mmap区域 并向操作系统申请虚拟内存,而非主分配区只 能访问mmap区域。
(2) fast bin
单向链表,通过chunk的size进行索引。 fast bin主要用于提高小内存申请的分配效率
默认情况下,对于 SIZE_SZ 为 4B 的平台, 小 于 64B 的 chunk 分配请求;对于 SIZE_SZ 为 8B 的平台,小于 128B 的 chunk 分配请求,首 先查找fast bins
首先会查找 fast bins 中是否有所需大小的 chunk 存在(精确匹配),如果存在,就直接返回属于 fastbin中的chunk被释放后,这个chunk将会被加 入到对应索引值idx的fastbin链表中
单向链表,通过chunk的size进行索引。fast bin主要用于提高小内存申请的分配效率。
当用户申请了一个大小属于fastbin的chunk, ptmalloc通过chunk大小获得索引值idx,进而获 得对应的链表来寻找符合条件的chunk。
fast bin使用LIFO和大小完全匹配的规则:
添加操作(free内存)就是将新的fast chunk加入链 表尾,删除操作(malloc内存)就是将链表尾部的 fast chunk删除。
每个fast bin都是一个单链表(只使用fd指针)。因 为在fast bin中无论是添加还是移除fast chunk, 都是对“链表尾”进行操作,而不会对某个中间的 fast chunk进行操作 。
在进行分配时,除去原子性方面的安全检查, 只对chunk的size域检查。
(3) small bin
双向链表结构,chunk大小范围为:16-504B (SIZE_SZ=4B,以8Byte为公差的等差数列 )或32-1008B(SIZE_SZ=8B,以16Byte 为公差的等差数列)。
在分配chunk时,对双向链表进行安全检查。
如果small bin还未初始化,会调用相关函数 对fast bin中的chunk进行合并并放到 unsorted bin中。
(4) large bin
chunk大小范围为:大于512B( SIZE_SZ=4B)或1024B(SIZE_SZ=8B)
large bin将它的63个bin按照每组的个数32 、16、8、4、2、1分为6组,每组组内的各 bin的chunk大小符合等差数列。
在分配的过程中,会寻找最小的符合申请大小 的chunk,对合适的chunk进行分割后,剩余 的部分将会被放到unsorted bin中。
(5) unsorted bin
unsortedbin的chunk链表头存放在bins[1]中 。
双向链表,可看作是small bin和large bin的缓存 。
进行分配的时候,如果当前选择的unsorted bin中 的chunk不符合条件,则该chunk会被放入到相应 的bin中,然后继续查找。
如果unsorted bin中存在上一次分割剩下的chunk ,则先匹配该chunk。
分配过程中,会对size进行检查。
malloc函数:
在ptmalloc中具体由_int_malloc实现 。
实际申请空间计算方法:
用户申请的空间加上chunk信息所需空间
再减去后一个chunk的复用空间
地址以2 * SIZE_SZ进行对齐
如果计算结果小于MIN_CHUNK_SIZE,则按 系统规定的最小值进行申请。
申请时按照以下顺序查找空闲chunk :
(tcache)(注:glibc 2.27新加入的机制) ,fast bin , small bin ,unsorted bin , large bin , top chunk
注:当malloc从fastbin、smallbin、unsortedbin、 largebin中都无法找到合适或足够大的空闲chunk进行分 配或分割时,若topchunk足够大,将会从topchunk中进 行分配。
free函数:
在用户释放一个堆块的时候,程序会更具堆块 的大小以及堆块的位置的不同做出不同的操作。
先判断当前这个块大小是否小于fastbin的最大值, 如果小于fastbin的最大值,并且不临近topchunk 的时候,就将这个块,链入到fastbin对应的链中, 并不修改后一块的标志位。
如果不是fastbin或者临近topchunk的时候 。这时候程序会先检测前项是否是释放状态,如果前项是释 放状态,则将前项和当前chunk合并,同时检测后项状态 。如果后项是topchunk,则直接将当前的chunk并到 topchunk中。如果后项不是topchunk的时候,也会将后项合并到当前 chunk中,并且会修改后块的标志位,然后将这一块链到 unsortedbin上。在合并中,会触发unlink操作。
unlink函数
在free时,如果free的chunk的前一chunk是 空闲的,将调用unlink函数将前一chunk从 bin中取出。
unlink函数最重要的是下面4行代码 :

p是需要拖链的指针,前两步将p的前向指针和后向指针分别赋给 FD 和 BK。 随后将p的前一个指针的后向指针改为指向p的后一个指针, 将p的 后一个指针的前向指针指向p的前一个指针。也就是将p从链表中脱出来。
3.堆溢出漏洞
造成的原因主要是在堆上对数据进行写入、读取、复制等操作时,未对数据长度、范围等进 行良好的处理,导致对非当前chunk进行了操 作。
通过堆溢出漏洞,能够覆盖关键数据结构、破坏对结构等。
堆溢出漏洞(以unlink为例):
在新版的unlink函数中,对FD 和 BK指针进行了检查:
__builtin_expect( FD->bk != P || BK>fd != P, 0 ) )这个检测,这个检测要求FD>bk== P且BK->fd== P也就是说要求后项 指针的前项指针指向P,前项的后项指针指向P ,也就是构成一个双链才能进行unlink。
要满足FD->bk = P 和 BK->fd = P, __builtin_expect( )函数才能执行else的操 作绕过该安全检查。

堆溢出多见于复制数据到堆上,或向堆上读数 据时,未对边界进行检查,导致可以在堆上写 入超出一个堆块大小的数据,从而覆盖其他关 键数据结构,导致对堆结构的破坏.
我们以下面的程序为例:
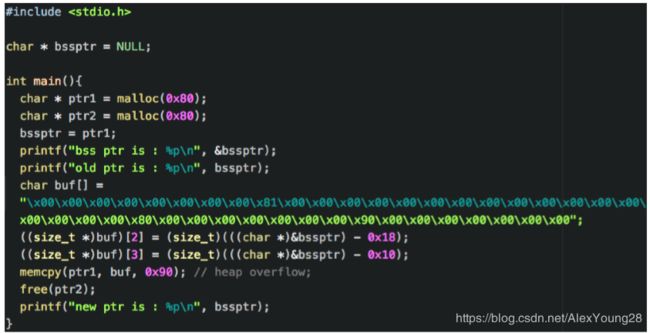
要想实现 FD->bk = ptr1:
必须构建FD=ptr1->fd=&bssptr-0x18
要想实现BK->fd = ptr1:
必须构建BK=ptr1->bk=&bssptr-0x10
要将ptr1伪造为释放块,所以要改写ptr2的内 容,包括prev_size和size两个字段。 将size修改为 0x90(这里0x90的最后一位,即size最后一 位为0标志着上面一个块为释放块,没有被使 用),会导致在释放ptr2的时候(前面有一个 free(Ptr2)),误认前一块为已经释放块(然 而在程序的逻辑中,我们并没有释放第一块)
上述伪造操作,通过memcpy执行,从而将经 过计算好的FD和BK写入ptr1的fd和bk位置。 因为为了将ptr1的伪装成为释放块,所以我们要将ptr1的FD 和 BK进行修改。
然后释放free释放 ptr2,利用伪造的ptr2的 size标志位,伪造prt1为释放块,free会对 ptr1进行unlink操作。
unlink过程中,执行: FD->bk =BK; BK>fd =FD操作,从而实现了bssptr的重新赋 值,将bssptr的值修改为&bssptr-0x18.
后续如果能对bssptr进行其他修改,就可以对 &bssptr-0x18开始的区域进一步修改,并实 现可控。为进一步攻击创造了条件。
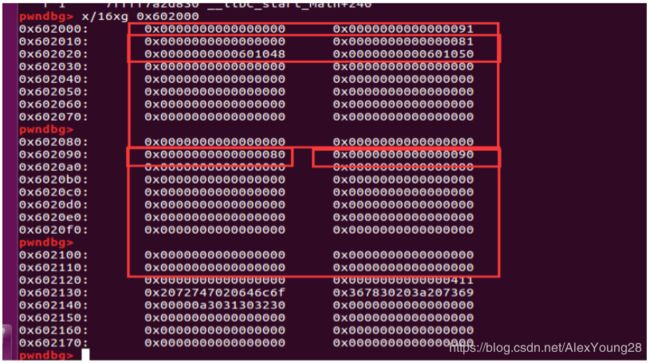
下图是在第二个malloc之后堆上的状态,此时 可以看到两个0x90(即145,最后一位为标志位 1,代表前面是已用的堆块)的块和一个 topchunk,而这时候调用memcpy去堆ptr1 进行heapover,使得ptr1覆盖ptr2的 prev_size和size两个字段。
下图是memcpy之后的内存状态对前后两块的内 容变化进行对比 。发现后一块ptr2的prev_size和size两个字段分 别被改写为0x80和0x90,这样就导致在free后 ptr2的时候,根据size的最后一bit为标志位,当 此位为0,标志着物理上相连的前一块ptr1是释放 块,然后根据prev_size去找前一块的堆头。
4 释放后重用漏洞
Use After Free(UAF) 指的是对堆上已经 释放的块的重用所导致的问题。 UAF往往由于程序在编写的过程中,开发 人员没有清空free之后的指针,导致可以 再度利用该指针,并且可以控制这个指针 去做其他事情。
以一个fastbin上的UAF示例来说明UAF的 利用和危害:
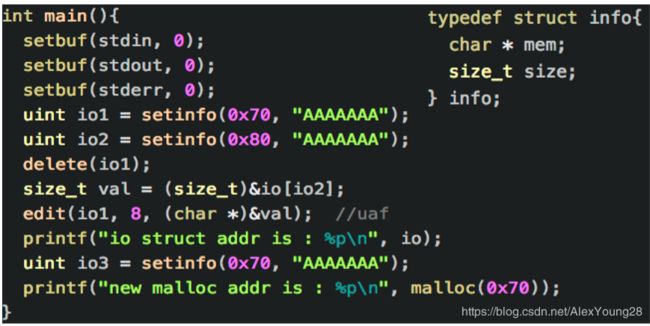


程序逻辑:首先申请堆块,填入一些信息。而 管理信息的结构体位于bss段。程序一共提供 了三个功能,setinfo,edit,delete setinfo:程序通过struct info这个结构体来管理 内存结构,这个结构体中有两项,mem和size,分 别代表申请的内内存地址和大小
edit:会接收io结构体中的数组下标,size和修改 的数据,并且利用结构体中记录的size来判断是否 发生溢出和越界的行为。修改时,判定size是否超 过申请的大小,防止堆溢出。
Delete:会调用free函数,来是否某个结构体中的 地址指针,将内存还给libc的堆块管理器。)
而且程序在delete的时候,并没有清空结构体 中的数据,没有将size和mem置0,导致可以 对释放之后的堆块进行复写。可以利用edit函数,对某个为清空的指针进行复写。
示例程序的目的是通过uaf,覆盖fastbin的后 项指针 :修改fastbin后项指针,为了让它可以分配到指定内 存去,但是fastbin有一个堆头size的检测,所以这 里需要伪造一个堆头size,然后把后项指针指向过 去,再分配。
覆盖fastbin的后项指针,使之分配到bss段上
目的是在bss段上伪造一个chunk,fastbin指针指 过去后,可对此bss段上的内容进行修改
这里先申请了一个0x70的块,这样再内存中分配的大小 是0x80,而64位情况下,0x80正好是fastbin中的块, 而后面申请0x80的块,实际目的是为了再bss上面写上一 个0x80
由于程序会记录下第二块的size,所以申请0x80的时候 ,程序会在bss上面写入一个0x80),这样就可以再bss 上伪造好一个0x80的size,这样堆块就可以正常的分配 过去)。
5. 重复释放漏洞
双重释放(Double Free)漏洞是UAF漏 洞的一种,主要是由于代码对同一个 chunk进行了两次free操作所导致,结合 释放后写入、堆溢出覆盖写入等漏洞,可 以进一步控制指定的内存区域。
以一个fastbin attck示例来简要说明双重 释放(Double Free)漏洞,先分析一下 free函数的功能,好符合其检查的条件后 开展双释放漏洞利用
free函数的分析 :
fastbin中的chunk的特性:
当用户再次申请相同大小的chunk时,fastbin中匹 配的chunk将会被取出。
符合fastbin大小要求的chunk,在被用户free后, 将会被放入fastbin中,此chunk在被用户使用时, 其下一个比邻的在使用的chunk的pre_inuse中 size的标志位不会被重置为0。
优点:利用时不需要考虑修改下一块的prev_inuse标志 位。
free函数释放chunk时,会检测chunk是否处于使 用状态。
由于fastbin中的chunk在释放后不会重置下一个 chunk的pre_inuse中size的标志位,不会被重置 为0
在执行第二次free chunk时,在此处可以通过free 函数中的check_inuse_chunk(av, p)函数的检查 (即pre_inuse位还标识被用户释放的那个chunk 还处于未被释放状态),因此可以实现对一个 chunk的双free操作。
接着free函数就会将chunk根据其大小放入 相应的fastbin链表中。
放入前,free函数还会检测fastbin中已经放入的 chunk和新放入chunk的大小,主要是检测将新放 入的chunk,和与它同样大小的前一个chunk是否 是同一个,这个检查导致不能连续释放同一个 chunk
因此,只能使用free(chunk1)、free(chunk2)、 free(chunk1)的方式,可以达到双重释放的目的。
双重释放过程中,利用malloc函数,会对命中的 fastbin chunk的size进行检查: 用户申请的空间大小,和命中chunk的size两个数值相同 ,进行fastbin索引的计算并进行比较是否一致。