【斯坦福---机器学习】复习笔记之牛顿方法
本讲大纲:
1.牛顿方法(Newton’s method)
2.指数族(Exponential family)
3.广义线性模型(Generalized linear models)
1.牛顿方法
假设有函数:![]() ,我们希望找到满足
,我们希望找到满足![]() 的
的![]() 值. 这里
值. 这里![]() 是实数.
是实数.
牛顿方法执行下面的更新:

下图为执行牛顿方法的过程:

简单的来说就是通过求当前点的导数得到下一个点.用到的性质是导数值等于该点切线和横轴夹角的正切值.
令![]() ,我们可以用同样的算法去最大化
,我们可以用同样的算法去最大化![]()

牛顿方法的一般化:
如果![]() 是一个向量,那么:
是一个向量,那么:
![]()
其中,![]() 是
是![]() 对
对![]() 的偏导数;
的偏导数;
H称为黑塞矩阵(Hessian matrix),是一个n*n的矩阵,n是特征量的个数,并且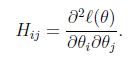 (==当年学的各种名词又开始在脑海里翻滚==)
(==当年学的各种名词又开始在脑海里翻滚==)
牛顿方法的收敛速度比批处理梯度下降快很多,很少次的迭代就能够非常接近最小值了;但是当n很大时,每次迭代求黑塞矩阵和黑塞矩阵的逆代价是很大的.
2.指数族
指数族形式:
![]()
其中,![]() 被称为自然参数(natural parameter)或者典范参数(canonical parameter);
被称为自然参数(natural parameter)或者典范参数(canonical parameter);
T(y)是充分统计量(sufficient statistic)(对于我们考虑的分布来说,通常T(y)=y);![]()
是日志分配函数(log partition function),![]() 是一个规范化常数,使得分布的和为1.
是一个规范化常数,使得分布的和为1.
给定T,a,b,通过改变参数![]() 得到不同的分布.
得到不同的分布.
下面展示伯努利(Bernoulli)和高斯分布(Gaussian distribution)都是指数分布族的特例:
伯努利分布可以写成:
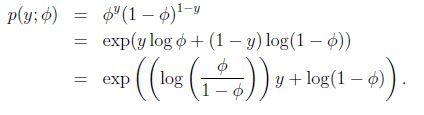
因此,令![]() (有趣地发现其反函数为
(有趣地发现其反函数为![]()
![]() ),并且,
),并且,

高斯分布:
回忆我们对线性回归求导时,方差对我们最终结果并没有任何影响.为了使问题简化,令![]() 于是有,
于是有,

得:

指数分布族还包括很多其他的分布:
多项式分布(multinomial)
泊松分布(poisson):用于计数的建模
伽马分布(gamma),指数分布(exponential):用于对连续非负的随机变量进行建模
β分布,Dirichlet分布:对小数建模
3.GLMS
为了导出GLM,作三个假设:
(1)![]()
(2)给定x,我们的目标是预测T(y)的预期值. 在大部分例子中,我们有T(y)=y,因此意味着我们通过学习得到的假设满足![]() (这个假设对logistic回归和线性回归都成立)
(这个假设对logistic回归和线性回归都成立)
(3)自然参数和输入变量是线性相关的,也就是说![]() (如果自然参数是向量,则
(如果自然参数是向量,则![]() )
)
3.1普通的最小二乘法
为了说明普通的最小二乘法是GLM的特例,设定目标变量y(在GLM术语中叫响应变量-response variable)是连续的,并且假设服从高斯分布![]() ,高斯分布写成指数族的形式,有
,高斯分布写成指数族的形式,有![]() 得到:
得到:

3.2 logistic回归
考虑logistic,我们感兴趣的是二元分类,也就是说![]() 很容易想到指数分布族的伯努利分布,有
很容易想到指数分布族的伯努利分布,有![]() ,同理得到:
,同理得到:
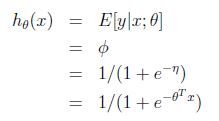
正则响应函数(canonical response function):![]()
正则链接函数(canonical link function):![]()
3.3 softmax 回归
当分类问题的y取值不止两个时,我们需要采用多项式分布(multinomial distribution).
在推导多项式分布的GLM之前,先把多项式分布表达成指数族.
为了参数化多项式分布的k各可能结果,有人可能会用k个参数来说明每一种情况的可能性,但是这些参数是冗余的,并且并不是独立的(由于知道任何其中的k-1个,剩下的一个就可以求出,因为满足![]() ). 因此我们用k-1个参数
). 因此我们用k-1个参数![]() 对多项分布进行参数化,
对多项分布进行参数化,![]() .
.
定义![]() ,如下,
,如下,
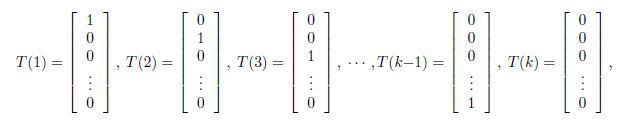
介绍一个很有用的记号,![]() ,例如1{2=3}=0,1{3=5-2}=1.
,例如1{2=3}=0,1{3=5-2}=1.
因此T(y)和y的关系为![]() .
.
并且有![]() ,因此:
,因此:

链接函数为,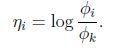 ,为了方便,定义
,为了方便,定义![]() .
.
可得:

因此![]() ,反代回去得到响应函数:
,反代回去得到响应函数:

从η到![]() 的映射叫做softmax函数.
的映射叫做softmax函数.
根据假设3,![]() 得到:
得到:
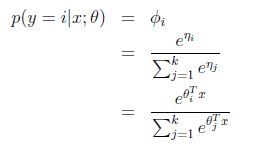
这个应用于分类问题(当![]() ),叫做softmax回归(softmax regression).是logistic回归的推广.
),叫做softmax回归(softmax regression).是logistic回归的推广.

与最小二乘法和logistic回归类似,

再通过梯度上升或者牛顿方法求出θ.