并发编程与高并发解决方案学习(线程池)
继承Thread的弊端
1.每次new Thread的时候都需要新建一个线程,性能差
2.线程缺乏统一管理,可能无限制的新建线程,相互竞争,有可能占用过多系统资源导致死机或者OOM
3.Thread类缺少更多功能,比如更多的执行、定期执行、线程中断。
线程池的好处
1.重用存在的线程,减少对象创建、消亡的开销、性能佳
2.可以有效的控制最大并发线程数,提高系统资源利用率,同时可以避免过多资源竞争,避免阻塞。
3.提供定时执行、定期执行、单线程、并发数控制等功能。
线程池-ThreadPoolExecutor
corePoolSize:核心线程数
maximumPoolSize:线程最大线程数
workQueue : 阻塞队列,存储等待执行的任务,很重要,会对线程池运行过程产生重大影响
※如果运行的线程数小于corePoolSize,直接创建新线程来处理任务,即使线程池中的其他线程是空闲的;
※如果线程池中的线程数量大于等于corePoolSize且小于maximumPoolSize的时候后,则只有当workQueue满的时候才创建新的线程来处理任务
※如果corePoolSize等于maximumPoolSize的时候,那么创建的线程池大小是确定的,这个时候如果有新任务提交如果workQueue没满的时候就把请求放在workQueue里面,等待有空闲的线程从里面取出任务来处理
如果运行的线程数目大于maximumPoolSize的时候,这个时候如果workQueue也已经满了那么需要通过拒绝策略处理任务。
keepAliveTime : 线程没有任何任务执行时,最多保持多久时间终止。

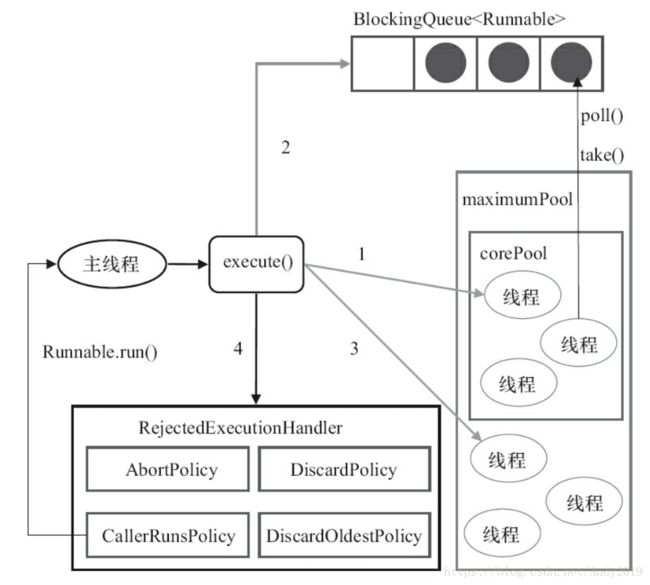
ThreadPoolExecutor执行execute方法分下面4种情况。
1)如果当前运行的线程少于corePoolSize,则创建新线程来执行任务(注意,执行这一步骤
需要获取全局锁)。
2)如果运行的线程等于或多于corePoolSize,则将任务加入BlockingQueue。
3)如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务(注意,执
行这一步骤需要获取全局锁)。
4)如果创建新线程将使当前运行的线程超出maximumPoolSize,任务将被拒绝,并调用
RejectedExecutionHandler.rejectedExecution()方法。
ThreadPoolExecutor采取上述步骤的总体设计思路,是为了在执行execute()方法时,尽可能
地避免获取全局锁(那将会是一个严重的可伸缩瓶颈)。在ThreadPoolExecutor完成预热之后
(当前运行的线程数大于等于corePoolSize),几乎所有的execute()方法调用都是执行步骤2,而
步骤2不需要获取全局锁
源码分析
/**
* Executes the given task sometime in the future. The task
* may execute in a new thread or in an existing pooled thread.
*
* If the task cannot be submitted for execution, either because this
* executor has been shutdown or because its capacity has been reached,
* the task is handled by the current {@code RejectedExecutionHandler}.
*
* @param command the task to execute
* @throws RejectedExecutionException at discretion of
* {@code RejectedExecutionHandler}, if the task
* cannot be accepted for execution
* @throws NullPointerException if {@code command} is null
*/
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}unit : keepAliveTime的时间单位
threadFactory:线程工厂,用来创建线程
rejectHandler:当拒绝处理任务时的策略

ThreadPoolExecutor方法
execute():提交任务,交给线程池执行
submit():提交任务,能够返回执行结果 execute + future
shutdown()关闭线程池,等待任务都执行完了
shutdownNow():关闭线程池,不等待任务执行完
getTaskCount():线程池已执行和未执行的任务总数
getCompletedTaskCount():已完成的任务数
getPoolSize():线程池当前的线程数
getActiveCount():当前线程池中正在执行任务的线程数量
newCachedThreadPool
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
@Slf4j
public class ThreadPoolExample1 {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int index = i;
executorService.execute(new Runnable() {
@Override
public void run() {
log.info("task:{}", index);
}
});
}
executorService.shutdown();
}
}newFixedThreadPool
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
@Slf4j
public class ThreadPoolExample2 {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
final int index = i;
executorService.execute(new Runnable() {
@Override
public void run() {
log.info("task:{}", index);
}
});
}
executorService.shutdown();
}
}newSingleThreadExecutor
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
@Slf4j
public class ThreadPoolExample3 {
public static void main(String[] args) {
ExecutorService executorService = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int index = i;
executorService.execute(new Runnable() {
@Override
public void run() {
log.info("task:{}", index);
}
});
}
executorService.shutdown();
}
}newScheduledThreadPool
import lombok.extern.slf4j.Slf4j;
import java.util.Date;
import java.util.Timer;
import java.util.TimerTask;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
@Slf4j
public class ThreadPoolExample4 {
public static void main(String[] args) {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);
// executorService.schedule(new Runnable() {
// @Override
// public void run() {
// log.warn("schedule run");
// }
// }, 3, TimeUnit.SECONDS);
executorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
log.warn("schedule run");
}
}, 1, 3, TimeUnit.SECONDS);
// executorService.shutdown();
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
log.warn("timer run");
}
}, new Date(), 5 * 1000);
}
}