从软件方面讲,这一现象称为“免费的午餐”—只需升级运行应用程序的硬件就能改进其性能。(有关这方面的详细信息,请参阅“面向软件并发的基本转变”,网址为 ddj.com/184405990。)
但如今的模式正在发生改变,处理器的增加使性能得到了改进。多核系统现在已是无处不在了。当然,只有软件能同时执行多个任务,多核方式才能提高性能。如果想让多处理器实现多处理器计算机所承诺的性能提高,必须编写可以使用顺序技术出色完成任务的函数。
本文将介绍以下内容:
|
本文使用了以下技术: 多线程 |
目录
从软件方面讲,这一现象称为“免费的午餐”—只需升级运行应用程序的硬件就能改进其性能。(有关这方面的详细信息,请参阅“面向软件并发的基本转变”,网址为 ddj.com/184405990。)
但如今的模式正在发生改变,处理器的增加使性能得到了改进。多核系统现在已是无处不在了。当然,只有软件能同时执行多个任务,多核方式才能提高性能。如果想让多处理器实现多处理器计算机所承诺的性能提高,必须编写可以使用顺序技术出色完成任务的函数。
并发和并行
现在,程序员有时必须要考虑并行给编程所带来的难题—并发。为了保证响应,需要有某种方式能从输入事件的处理线程卸载响应时间过长的活动。过去这类活动大部分涉及文件 I/O,但现在更多的是涉及与 Web 服务的会话。
Microsoft .NET Framework 提供了异步编程模型和后台工作程序理念,以适应这一常用编程需要。虽然在并行编程中平行编程的复杂性大部分相雷同,但基本模式和目标却各异。多核处理器不会减少并发编程需求,这种技术是用于优化后台活动和系统中的其它计算,目的是提高性能。
去年,Microsoft 发起了“平行计算管理计划”(go.microsoft.com/fwlink/?LinkId=124050),该活动不但是要探讨如何构建并有效执行并行程序,而且旨在鼓励创建新一代应用程序,能够将“摩尔红利”转化为客户价值。我将很快研讨一些并行性的思路。Stephen Toub 和 Hazim Shafi 在本期的文章“在下一版本的 Visual Studio 中更好地支持并行性”介绍了一些我们用于支持这些方法的库和工具。Joe Duffy 在本期的文章“解决多线程代码中的 11 个可能的问题”中讨论了改进并发应用程序安全的技术和方法。
以前,我使用“并发执行机会”一词进一步区分并行与并发编程。如开发人员使用异步编程模式或后台工作程序,或者在服务器中处理并发请求,这里会有一个例外,即所有不同的线程一律前行。操作系统的任务计划程序将确保每个线程均获得公平的共享资源。但这一点对于并行编程并无帮助。如果您感兴趣的是编写将用于新硬件系统的应用程序,它能发挥的作用就更为有限。
如果您想从免费午餐中受益,即通过硬件升级使软件的性能更好,则需要让更多现有的并行功能可以在将来继续发挥功效。在此,我将使用“任务”这一术语取代线程,来强调并行实施中的转变以及我的思路:鼓励应对并行编程的开发人员将问题分解为更多的任务。
并行编程系统的实现应该能根据需要将这些任务映射给系统线程和处理器。只有为数不多的程序员发现,从操作系统取得系统资源并在进程中进行管理以便有效执行并行程序的方式有了巨大的变化。它就象一个线程池,但侧重于将应用程序中的并行机会与当前硬件的可用资源相搭配,而不只是按并行程序员的指令管理线程。
在并发编程中(尤其是服务器),大部分困难源自使用锁等工具协调长时间运行线程对共享变量的访问。如转为具备任务的并行编程,可以使用一个新概念。例如,在任务 A 后面运行一个任务 B,并提供基本协调元素对其加以说明。这样程序员就可以考虑为工作制订计划。通常,这一计划会从本质上配合程序的算法结构,并从并行编程抽象的结构化使用中反映出来。程序抽象与并行算法间的良好配合能极大地减少对传统并发机制的需求(如锁和事件),并可避免许多并发编程的风险(但不能完全消除)。
接下来,我将说明一些并行编程的主要方法并通过正在开发的抽象展示其使用。我还会特别使用 C# 展示 C++ 并行模式库 (PPL) 和 .NET 并行扩展(网址为 go.microsoft.com/fwlink/?LinkId=124621)。
结构化多线程
人们处理问题时最常用的模式是先分割再解决:使用定义良好的交互将一个大问题分解为多个小问题,这些问题可单独解决,然后将结果汇总,从而解决原始问题。无论是大型公司的风险,还是邻居的日常琐事,它们都使用这一技术解决问题。由这一观念带动的应用程序也顺理成章的成为了并行编程的基础。
结构化多线程指提供并行模式的顺序语句,它的块呈结构化。例如,一条采用顺序语法的复合语句 { A; B; },原本先求 A 的值,再求 B 的值,现在成为了一个并行语句,A 和 B 可以同时求值。但整个构造并未完成,控制继续转到下一个构造,直到两项子任务全部完成为止。这是一个旧概念,一直被视为 Cobegin 语句有时也称为“派生-联结并行性”以突出结构。相同的基本观点也适用于循环,其中每个迭代均定义一个任务,该任务与其他迭代同时计算。所有迭代均完成后,并行循环即告结束。
著名的 QuickSort 算法就是“分割-解决”这一概念的常见示例。在此我使用 C++ 构造展示一下此算法的简易并行化。基本算法选取一个数组,使用第一个元素做为基准值,将数据分为两部分,更新数组以便所有小于基准值的数值在前,大于基准值的数值在后。随后递归应用这一步骤对数据排序。通常还会在中间使用一些非递归算法(如插入排序)来减少开销。
图 1 展示了 Microsoft 正在开发的两种功能。第一个是新的 C++ lambda 语法,它为将表达式或语句列表捕获为函数对象带来了极大的便利。以下语法创建了一个函数对象,调用它时会计算两个括号之间的代码。
[=] { ParQuickSort(data, mid); }
图 1 快速排序
// C++ using the Parallel Pattern Library templatevoid ParQuickSort(T * data, int length, T* scratch) { if(length < Threshold) InsertionSort(data,length) else { int mid = ParPartition(data[0], data, length, scratch, /*inplace*/true); parallel_invoke( [=] { ParQuickSort(data, mid); }, [=] { ParQuickSort(data+mid, length-mid); }); } }
前面的 [=] 标记 lambda 并指示将所有未在表达式中引用的变量复制到对象中,在 lambda 主体中引用这些变量的项目将会引用这些副本。
parallel_invoke 是一个模板算法,在本例中,它获取两个这样的函数对象,将每个视为单独的任务加以计算,从而同时运行这些任务。完成两项任务后(在本例中,是完成两个递归排序),parallel_invoke 返回,然后完成排序。
注意:示例中的并发是递归应用“分割-解决”并发的结果。您在每一层级只有两项子任务,计算结束时您完成的任务数与排序数据的数量成正比。我已阐述了并发的所有内容,这类程序有可能发展为更大的问题,或需要更多的内核。对于固定大小问题,现实中任何有开销的机器都有可伸缩性限制。这是著名的 Amdahl 定律所产生的结果。平台供应商一个重要的工程目标就是不断降低这些开销,这意味着选择象阈值这样的值会很困难(图 1 中),随后对系统变化进行预测可能会更为困难。它们需要大小适度,既不让您付出过多的开销,同时还要保证不会限制将来的扩展。
Stephen Toub 和 Hazim Shafi 在本期讲述的 PPL 中有这个模板算法。除了 parallel_invoke,还有一个与 Standard Template Library's (STL) for_each 类似的 parallel_for_each。对于 parallel_for_each,其语法为每个迭代都是单独的任务,与其他迭代任务同时运行,parallel_for_each 在所有任务完成后返回。一些弱结构化技术还会创建与常用任务组相关的单项任务,然后等候所有这些任务完成。这会提供与 Cilk 生产基本元素 (supertech.csail.mit.edu/cilk) 相同的基本功能,但它以标准 C++ 功能为构建基础。
使用并行循环可处理射线跟踪。每个输出像素都需要些许并行度,与图 2 中所示类似的代码可存在这一现象。它使用 .NET 并行扩展的 Parallel.For 方法进行表达,对于托管开发人员,它包含的基本模式与 PPL 针对 C++ 开发人员所支持的模式相同。我在此使用一个简单的嵌套循环来说明与矩形屏幕上每个像素对应的任务空间。此代码假定循环主体中调用的不同方法可以安全并发执行。
图 2 并行循环
// C# using Parallel Extensions to the .NET Framework
public void RenderParallel(Scene scene, Int32[] rgb)
{
Parallel.For(0, screenHeight, y =>
{
Parallel.For (0, screenWidth, x =>
{
Color color = TraceRay(new Ray(camera.Pos,
GetPoint(x, y, scene.Camera)), scene, 0);
rgb[x + y*screenWidth] = color.ToInt32();
});
});
}
仍请参阅 Duffy 有关并发安全的文章。在并行编程的早期,开发人员将承担这些责任。购者自慎,买主当心。
对于正常的数据结构(可能是递归或不规则),并行性可以反映这种结构,因此结构化多线程最适合与其搭配使用,即使在问题中出现一些数据流这一结论也成立。以下示例按拓扑逻辑顺序遍历一幅图片,因此我必须先看到所有前置任务,然后才能访问节点。我在每个节点保留了一个计数字段,它初始化为前置任务的数目。访问节点后,我减少后续任务的计数(请确保此操作的安全,因为一次可能会有多项前置任务尝试这一操作)。计数变为零后,我就可以访问该节点:
// C++
void topsort(Graph * g, void (*action)(Node*)) {
g->forall_nodes([=] (Node *n) {
n->count = n->num_predecessors();
n->root = (n->count == 0);
});
g->forall_nodes([=] (Node *n) {
if(n->root) visit(n, action);
});
}
图 3 深度优先搜索
// C++ using the Parallel Pattern Library
// Assumes all predecessors have been visited.
void visit(Node *n, void (*action)(Node*)) {
(*action)(n);
// assume n->successors is some kind of STL container
parallel_for_each(n->successors.begin(),
n->successors.end(),
[=](Node *s) {
if(atomic_decrement(s->count) == 0) // safely does "-- s->count"
visit(s, action);
});
}
parallel_for_each 遍历后续任务的列表,对每项任务应用函数对象,然后允许并行完成这些操作。假定的 atomic_decrement 函数未显示,它使用判优并发访问的某些策略。注意,在此您会开始在我们其他的并行算法中看到更多传统并发问题,随着元素操作愈发复杂(如射线跟踪示例),这些问题会更为恶化。
此算法的结构保证让操作独占访问其参数,这样,如果操作更新这些字段,不需要额外的锁定。此外,它们还会保证所有前置任务已更新,不会发生变动,且任何后续任务均未更新,在此操作完成前也不会有改变。在构建正确的并行算法时,能够推论哪是稳定状态,哪种状态可以并发更新至关重要。
结构化多线程的长处在于并行机会(包括那些部分排序计算面临的机会)易于表达,无须在基本算法中搀杂过多向工作程序线程映射作业的机制。这就提供了更为强大的复合模式,如此处所示,其数据结构可提供某些基本并行遍历方法(如 Graph::forall_nodes),可以重复使用它们构建更为复杂的并行算法。此外,与只为两个或四个处理器查找足够的并行机制相比,说明所有的并行机制要容易得多。它不只是更为便利,还为将来的八处理器机器提供了先天扩展机会。
数据并行性
数据并行性指对数据合计应用某些常用操作,以生成新的数据合计或将合计减为标量值。并行性源自对独立于周边元素的每个元素执行相同的逻辑操作。对于合计操作,现在已经有多种语言能提供多层支持,但至今为止最为成功的是与数据库搭配使用的 SQL。LINQ 在 C# 和 Visual Basic 中为 SQL 样式的运算符提供直接支持,使用 LINQ 表达的查询可以传递给数据提供程序,如 ADO.NET,或者根据内存中的对象集合(甚至 XML 文档)进行计算。
.NET 并行扩展带有 LINQ to Objects 和 LINQ to XML 实现,它包括查询的并行计算。此实现称为 PLINQ,可利用它轻松与数据合计配合使用。以下示例展示了统计群集标准 K 平均算法的内核:在每一步骤中,您在空间会有 K 个点,它们是您的备选群集中心:将每个点映射到最近的群集,然后针对映射到相同群集的所有点,通过平均群集中的点位重新计算该群集的中心。此过程继续执行,直到达到聚合条件,即群集中心的位置稳定下来。此算法说明的中央循环可以相当直接地转化为 PLINQ,如图 4 所示。
图 4 查找中心
// C# using PLINQ
var q = from p in points.AsParallel()
let center = nearestCenter(p, clusters)
// "index" of nearest cluster to p
group p by center into g
select new
{
index = g.Key,
count = g.Count(),
position = g.Aggregate(new Vector(0, 0, 0),
(accumulated, element) => accumulated + element,
(accumulated1, accumulated2) =>
accumulated1 + accumulated2,
(accumulated) => accumulated
) / g.Count()
};
var newclusters = q.ToList();
LINQ 和 PLINQ 的区别在于数据集合点的 AsParallel 方法。本例还显示 LINQ 包含核心的 map/reduce 模式,但这一模式是明确集成到主流语言中的。本例中的另一精微之处是 Aggregate 运算符的行为。第三个参数是一个委托,它提供了一种组合部分总和的机制。有了这个方法,就可以并行实现,即将输入合并成块,并行减小每个块,然后将各个结果组合起来。
如使用结构化多线程方法,数据结构假设会变得十分混乱,与此相比,数据并行中的算法表达得更为清晰,可读性也更好。此外,更加精炼的说明让系统能有更大的机会进行优化,如果手工执行这种优化,算法将会十分晦涩。最后,这种高级表示让执行目标更为灵活:多核 CPU、GPU 或扩大为群集。只要叶函数(如 nearestCenter)没有副作用,在面向线程的编程中您就不会遇到任何数据争用或死锁问题。
并行性开发的常用技术是使用管道。在这一模型中,数据项在管道的各个阶段之间流动,在向下一阶段传送前要接受检查和转换。数据流的基理是:数据值在图形的节点间流动,并根据输入数据的可用性触发计算。通过并发执行各个节点和让一个节点针对不同的输入数据多次激活,以此实现并行。
.NET 并行扩展支持显式创建单个任务(类型为 Task,实现结构化多任务的底层机制),然后确定在第一项任务完成后开始执行的第二项任务。Future 这一概念在命令编程和数据流编程之间搭建起了桥梁。它是计算最终生成的值的名称。这种分隔使我能在了解值之前定义它的操作。
Future 的 continueWith 方法由委托加以参数化,它将用于创建在 Future 值可用时执行的任务。调用 continueWith 会生成一个新 Future,它会确定委托参数的结果。在命令编程中,常会因副作用计算任务,因此 continueWith 也可做为 Task 的方法使用。
Strassen 矩阵乘法算法中的并行性就是这一类型的一个示例。它是基本矩阵乘法算法面向块的版本。两个输入矩阵均被分为四个子块,然后用代数方法将其合并,形成输出矩阵的子块。(有关详细信息,请参阅 Wikipedia 就 Strassen 算法撰写的文章,网址为 wikipedia.org/wiki/Strassen_algorithm。)
其中一项任务可能如下所示:
// C# using Parallel Extensions to the .NET Framework var m1 = Future.StartNew(() => (A(1,1)+B(1,1))*(A(2,2)+B(2,2));
为清晰起见,我在委托中使用数学符号而不是代码来表达计算。A 和 B 是输入矩阵,A(1,1) 是 A 矩阵左上方的子块。添加项是矩阵的标准,乘法是 Strassen 算法的递归应用。输出是与此表达式结果相对应的临时矩阵。
前七项子任务是独立的,但后四项子任务以前七项为输入。基本数据流图应如图 5 所示。其中,标为 c11 的任务依赖于 m2 和 m3 的结果。我想让该任务在其输入可用时能够执行。在 C# 中可以使用如下代码表达:
var c11 = Task.ContinueWhenAll(delegate { ... }, m2, m3);
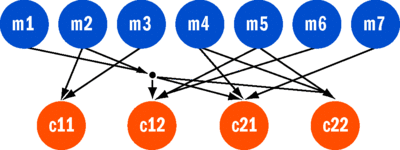
图 5 子任务(单击图像可查看大图)
它展示了所谓的中等粒度数据流,其计算量为几百到几千个操作,与之相比,精细粒度数据流中的每个操作可以是单一算术操作。用于处理“如果全部”和“如果任何”这两种概念的几种便利方法可以更清晰地表述这一点,但如 Stephen Toub 所述,它们是在基本机制之上实现的(请参阅blogs.msdn.com/pfxteam/archive/2008/07/23/8768673.aspx)。
至于结构化多线程,我已指出了其并行机会,如果您只有一个处理器,那么完全可以按子任务的创建顺序依次执行。但如果有其他资源,您就有机会通过捕捉子任务中的执行顺序约束来从中受益。与结构化多线程不同,您可以方便地允许一项任务枚举数据流图并对单个子任务隐藏其结果的使用和组合方式,这一点不同于常用的并行算法处理机制。
数据经常要流入应用程序,我想在其流过时对其加以处理。在这种情况下,数据遍历的路径相当稳定。我将任务与下一数据项的可用性关联起来,而不是关联其他任务的完成状况。在机器人技术中,算法决策要依靠以不同速率到达的多种传感器数据流,此时这一模型的价值尤为突出。
Microsoft Robotics SDK (go.microsoft.com/fwlink/?LinkId=124622) 就采用了这一方式,其中心概念涉及数据流(端口)和由数据到达(信息)激活的任务绑定。当然,我现在提到的这问题不是由向多核转换造成的,而是(如 Web 服务器)以并发为主要特征,必须视为应用程序整个体系结构的一部分加以解决。类似的问题也适用非机器人技术领域的分布式应用程序,但那超出了本文所讨论的范畴。
流式并行性
除了多核,计算机体系结构的另一个重要特征就是内存的多层次分层结构。寄存器、一或多级板上缓存、DRAM 内存以及按需分页磁盘。大多数程序员不熟悉(或至少是不关心)系统体系结构的这一领域,但他们对此并无懊悔之意。因为他们的程序很小,缓存就足以容纳这些程序,并且向缓存返回对内存的引用相当快。但是,如果数据值不在板上缓存中,那就需要数以百计的循环才能从 DRAM 取得数据。提供此类数据的延迟让人感觉程序运行得很慢,因为处理器花费了大量时间等待数据。
有些处理器的体系结构支持一个物理处理内核有多个逻辑处理器。这通常称为(硬件)多线程,在主流处理器中已经有了少量应用(例如,Intel 已在它的某些产品中将这称为超线程)。多线程的动机是允许内存访问延迟,一个逻辑硬件线程在等候内存时,可以从其他硬件线程发出指令。此技术也用在现代 GPU 中,但其来势要更猛。
随着处理内核数量的增加,向内存系统发出的请求数也在增加,这样又出现了一个新问题:带宽限制。处理器每秒从 DRAM 内存传入/传出操作的数量有一定限制。一旦达到上限,就无法继续利用并行取得增益;更多的线程只会产生更多的内存请求,造成请求排队,等候内存控制器的处理。GPU 通常有内存子系统,支持更高的聚合带宽(以每秒 GB 字节计),这样就能支持(或预期)更多的并行性,并从额外的带宽中受益。
就当前的多核芯片体系结构而言,其内核数量的增加速度比内存带宽提高的速度要快,因此对于大部分数据集与内存搭配问题,使用内存分层结构是一种倍受关注的方案。这种不平衡导致了流处理编程的产生,它侧重于将数据块放入板上缓存(或私有内存),然后在下一数据块替换它之前对其执行尽可能多的操作。这些操作可能在内部并行使用多个内核,或以数据流的形式送入管道内,但其重点是在数据位于缓存时对其执行尽可能多的操作。
人们已经期望有专用语言能允许指定流算法并仔细规划其执行,在许多情况下,也可以通过仔细规划时间达到这一目标。例如,您可以将些技术应用于 QuickSort 示例。如果您排序的数据集太大,缓存中容纳不下,最直接的省力方法是将最大的子问题规划给各个内核,这些内核随后会处理单独的各个数据集,但共享板上缓存的益处不复存在。
不过,如果您修改算法,使其只对缓存中的数据集使用并行,则可以从流中受益,如图 6 所示。在本例中,您仍是将大问题分解为小问题(并在分区步骤中使用并行性),但如果两个子问题不能同时放入缓存,我们可以依次处理它们。这意味着一旦您在缓存中得到小数据集,您可以在其处于缓存中时使用所有可用资源完成对其的完全排序,而不必在您启动下一数据集前将其放入内存。
图 6 对小型数据集使用并行
// C++ using the Parallel Pattern Library templatevoid ParQuickSort(T * data, int length, T* scratch, int cache_size) { if(length < Threshold) InsertionSort(data,length) else { int mid = ParPartition(data[0], data, length, scratch, /*inplace*/true); if(sizeof(*data)*length < cache_size) parallel_invoke( [=]{ ParQuickSort(data, mid, cache_size); }, [=]{ ParQuickSort(data+mid, length-mid, cache_size);}); else { ParQuickSort(data, mid, cache_size); ParQuickSort(data+mid, length-mid, cache_size); } } }
注意:您必须显式用缓存的大小参数化此代码,这是特定于实现的特征。如果此计算与其他作业或相同作业中的其他任务共享系统,这会不尽人意,并可能成为问题。但它指出了从复杂并行系统中取得性能所面临的一个难题。不是所有的问题都有这一症状,但要想多核芯片发挥良好性能,要求开发人员在某些情况下认真考虑并行交互和内存分层结构。
单程序,多数据
通过二十世纪八十年代的一系列努力,在高性能计算的舞台上,并行性已在技术与科学应用程序中使用了一段时间。这类问题由对数组实施的并行循环主导,循环的主体通常有一个相当简单的代码结构。
更早的射线跟踪片段就是一个例子。当时出现的主流并行性模型称为“单程序,多数据”,通常简称为 SPMD。这一术语暗指计算机体系结构典型的 Michael Flynn 分类法,它包含单指令、多数据 (SIMD) 和多指令、多数据 (MIMD)。在此模型中,程序员将每个处理器(工作程序、线程)的行为视为一组处理器,它们从逻辑上讲参与一个问题,但共享作业。作业通常是循环的单独迭代,它们使用数组的不同部件。
SPMD 中共享作业的概念彰显于 OpenMP (openmp.org) 对 C、C++ 和 Fortran 扩展组的核心。并行区域是此处一个主要概念,在该区域中,单一活动线程并入线程团队,然后共同执行共享循环。使用屏障同步机制来协调此团队,以便整个团队作为一个组从一个循环单位移至下一个循环单位,确保在团队成员完成计算后才能读取数据值。在区域末端,团队汇合在一起,原始单一线程继续工作,直到下一并行区域。
这种并行编程还用于非共享内存系统,在这类系统中,使用构建于信息传递基础上的内节点通信将周围的数据复制到阶段边界适宜的位置。这一技术可应用数以千计的处理器节点,从而获得极高的性能,解决天气建模和医药设计等问题。
与结构化多线程中类似,OpenMP 并行区域可位于函数内部,这样,该函数的调用方就无须了解实现中并行性的使用情况。但 SPMD 模型需要认真考量问题作业如何向团队中的工作程序做映射。
如果一个工作程序的任务时间比它的团队成员要长,就会产生负载不均衡,这暗示着其他团队成员可能要闲置等待该工作程序完成任务。在与其他作业共享系统资源的环境中,也会出现类似情况,如果 OS 中断工作程序,令其执行其他任务,这一人为不均衡会对其他工作程序产生影响。
未来的硬件系统可能有多种不同的处理器内核—耗能大但单线程运行快的大型内核,还有耗能小的小型内核,它们经优化后用于并行操作。这类环境对于 SPMD 模型而言是个大难题,因为它使得将作业映射给工作程序变得极为复杂。结构化多线程方法可以很好地避免这些问题,但代价是要略微增加一些规划开销,并可能损失对 OpenMP 托管代码的内存分层结构控制。
并发数据结构
前面的讨论几乎完全集中在控件并行性上—如何确定并说明单独的任务,这些任务可映射给多个可用内核。数据端与并行性也有关联。如果任务是为更新数据结构,例如将值插入 Hashtable,该操作从逻辑上可以独立于并发执行任务。
数据结构的标准实现不支持并发访问,它可能分解为多种模糊、不可预见且难以重现的方式。只是对整个数据结构加一道锁可能会在所有任务均串行化的程序中造成瓶颈,因并发使用的数据位置过少导致失去并行性。
因此,除了并行控件抽象,还必须要创建新的并发版本通用数据结构—Hashtable、堆栈、队列和各种数据集表现形式。这些版本已定义了受支持方法(可并发调用)的语法,它们设计为可避免在多项任务访问时出现瓶颈。
例如,并行查找图形连接元件的标准方法。基本策略是对图形启动一组深度优先遍历,找出相交节点,然后形成简化图形。顶层函数的基本结构如图 7 中所示。
图 7 深度优先遍历
// C++
// assign to each Node::component a representative node in
// the connected component containing that node
void components(Graph * g) {
g->forall_nodes([=] (Node * n) {
n->component = UNASSIGNED;
});
Roots roots;
EdgeTable edges;
g->forall_nodes([&roots, &edges] (Node * n) {
if(atomic_claim(n, n)) {
roots.add(n);
component_search(n,n, &edges);
}
});
// recusively combine reduced graph (roots, edges)
...
}
我们通过让每个节点指向代表性元素来隐式表示元件。输入是一幅图形,我假定它支持 forall_nodes 方法,可使用该方法和结构化多线程技术遍历图形。经函数对象参数化后将其用于每个节点。这一接口将并行算法与图形的结构细节隔离,但保留了结构化多线程的主要属性,并发出现在方法内部,可以高度结构化。
首先,将元件字段初始化为特殊值,然后启动(逻辑上从每个节点)并行深度优先搜索。每个搜索都先声明起始节点。由于其他搜索也可以到达节点,此声明基本上是自动测试,用于确定哪个搜索最先到达。该函数类似如下所示:
// C++
// atomically set n->commponent to component if it is UNASSIGNED
// return true if and only this transition was made.
bool atomic_claim(Node * n, Node * component) {
n->lock();
Node * c = n->component;
if(c == UNASSINGED) n->component = n;
n->unlock();
return c == UNASSIGNED;
}
我已假设每个节点一个锁,但在这个简单示例中,我可能使用 Windows 基元来执行指针值的内锁比较和互换。这里的主要问题是:防止多项任务并发访问的单一全局锁会清除数据并行性(即使我有很多控件并行),这会造成我们的并行尝试受阻。
您不一定每个节点都需要一把锁。可以节点映射给锁的一个小组,但必须小心因使用与目前处理器计数相关的具体值而产生伸缩瓶颈。根本无须使用明确的锁,Jim Larus 对使用“事务性内存”的研究旨在让开发人员只需声明应从并发执行代码隔离的代码间隔,其中的实现视需要引入锁定,以确保这些语法发挥作用。
一旦您已确定新的根元件,将其加入共享数据结构的根项中。从逻辑上讲,这是一组在算法第一步中找到的所有根元件。此容器逻辑上仅有一个实例,您需要为并发添加项优化它的实现。做为 PPL 和 .NET 并行扩展所包含的内容,Microsoft 将提供向量、队列和 Hashtable 的适宜实现,用于构建块。
一个节点的深度优先搜索在相邻节点进行迭代,试图在其元件内声明每个节点。如成功,则递归进入该节点(请参阅图 8)。
图 8 递归搜索
// C++ using the Parallel Pattern Library
// a depth first search from "n" through currently
// unassigned nodes which are
// set to refer to "component". Record inter-component edges in "edges"
void component_search(Node * n, Node * component, EdgeTable * edges) {
parallel_for_each(n->adjacents.begin(),
n->adjacents.end(),
[=] (Node * adj) {
if(atomic_claim(adj, component)
component_search(adj, component, edges);
else if(adj->component != component) {
edges->insert(adj->component, component);
}
});
}
如果声明失败,则意味着这个或其他任务先到达了这一节点,您应查看是否已将其加入别的元件。如果是,将两个元件记入共享的数据结构(EdgeTable)。该表使用并发 Hashtable 创建以避免信息重复。这仍是一个逻辑上共享的数据结构,您必须确保对并发访问有足够支持,以避免争夺或丢失有效并行。
这两种结构、根项和边缘项形成了逻辑图形,它记录初始元件估计值之间的连接。要完成算法,在此逻辑图形上找到已连接的元件,然后用最终的表示项(未显示)更新该节点级信息。
总结
与并行编程相关的性能问题有很多,数据并发性的丢失只是其中之一。如果您初次试用这一技术时,遇到莫明其妙地中断(例如,因为忘记使用锁)或实际速度比顺序执行慢(任务过小、过多锁定、缓存无效、内存带宽不足、数据连接等)。
随着 Microsoft 在并行编程方面的不断投入,抽象将会稳步得到改进,并会有工具帮助诊断和避免相关问题。当然,您也可以期望硬件本身实现改进,加入各项功能以降低各种成本,但这需要时间。
并行转变是软件业面临的一个转折点,必须要采用新的技术。对于应用程序中那些目前对时间敏感的内容,或预期将来会运行更大数据集的内容,开发人员必须要引入并行性。我已经说明了在应用程序中思考和使用并行性的几种不同的方式,并用 Microsoft 开发的新工具(大型“平行计算管理计划”的一部分)对其进行了演示。
深入分析:进军下一个 100X
自 1975 起,微处理器的性能每 10 年提高 100X,这得益于时钟频率 (3,000X) 和晶体管数目 (300,000X) 的指数级增长。指令的力量提高了 8X-100X—8 位 ADD 与 SSE4.1 DPPS“打包-4-SP-浮点矢量的点积”相比较—板上缓存现在的容量已赶上了早期的硬盘。做为一个行业,每个 100X 增长都为我们带来了新的惊喜。它为我们提供了巨大的动力。
但是,下一个 100X 增长的途径会有所不同。按照“摩尔红利规则”,我们仍可以期望每两年看到每个电路单位上晶体管数的另外四次倍增(32、22、16、11 纳米的结点)。但我们发现我们已进入了几条增长曲线的下降点,特别是电压调整和功耗(功率壁垒)、指令级并行性(复杂性壁垒)和内存延迟(内存壁垒)。
功率壁垒微处理器的动态功率与 NCV2f 成正比,即晶体管开关的数量 × 开关电容 × 电压的平方 × 频率。随着光刻结点的不断减小,每电路单位的晶体管数量可能加倍 (↑N),晶体管会越来越小 (↓C) 并使用更低的电压开关 (↓V)。现在,供电电压已从 15V 降至 1V,开关能量降低了 100X 还多。遗憾的是,CMOS 最低阈值电压是 0.7 V,所以我们最多还能期待 (1.0/0.7)2=2X 的节余。尽管有这些节余,但随着我们加大了微处理器的复杂性 (↑N) 并提高了其频率 (↑f),几平方厘米的硅所产生的电路单元功耗已从 1 W 增至 100 W,已达到了目前所用冷却方案的极限。剩下的余地已经很少了,功率的发展已进入零和游戏阶段。时钟频率将不会再向从前一样加快。不会再有另一个 100X 在此出现。
复杂性壁垒高性能微处理器使用出色的无序执行在线程内开拓指令级并行。不过,要从此方法取得更大的收益,存在实际的局限性。串行代码本身及其数据依赖性对可挖掘的并行性有所限制。在硬件中,您有时最多要用 N2 或更多的线路才能完成 N 次并行操作。前沿设计和确认成本也随之按比例增长。最重要的是,假定出现并行软件,功率壁垒决定了更为节省能源的微体系结构是更好的选择—成果/焦耳要强过成果/毫微秒。
内存延迟 DRAM 访问延迟(迟滞)的改进相对较慢,因此 CPU 使用缓存完全避开 DRAM。但缓存是昂贵的选择—如今完全缓存缺失会占用 300 个时钟周期。经验法则是通过将缓存增大四倍来等分缺失率。CPU 内核的复杂性主要集中于承受长时间不可预测的内存访问。但是,扩大内存带宽要更容易一些。您可随后应用内存级并行性—并行软件线程同时发出多个并发内存访问。每个线程可能仍需要等候很长时间才能访问,但并行计算的整体产能相当高。
串行处理器的性能在今后十年将会继续提高,但步伐甚缓。聪明的 CPU 设计人员和编译器编写人员仍能找出一些方法,四处收罗出 5% 或 10% 的性能改进。这是个不错的结果,因为许多很有价值的软件具备串行特征,并受 Amdahl 定律支配。但它仍无法提供我们期望的 100X。它要求软件开发并行性。如果有极为出色的软件出现,处理器供应商就能做好准备,提供具有数十个内核和高带宽内存解决方案的并行处理器。它们会应我们的要求进行构建。
—Jan Gray,Microsoft 并行计算平台构建团队的软件架构师