【FPN车辆目标检测】深入解读FPN及Windows7+TensorFlow+Faster-RCNN+FPN代码环境配置和运行过程
论文链接:
https://arxiv.org/abs/1612.03144
代码链接:
https://github.com/yangxue0827/FPN_Tensorflow
先来简单介绍一下FPN。
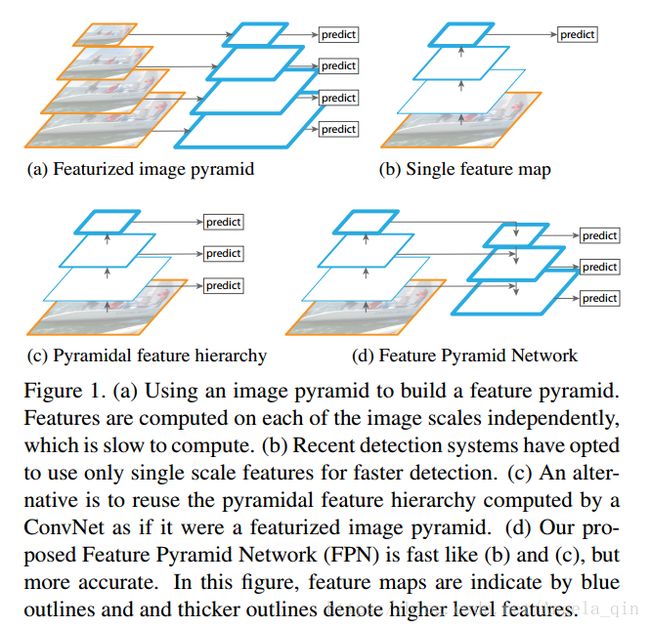
(a) 用图片金字塔生成特征金字塔。内存消耗大。
(b) 只在特征最上层预测,例如Faster-RCNN。
(c) 特征层分层预测,例如SSD。
(d) 就是本文要说的FPN,它从高层携带信息传给底层,每层都依次融合后,再分层预测。
一、安装环境
1. 安装Anaconda3
https://www.anaconda.com/download/#windows
2. 安装虚拟环境 (名为:tensorflow)
打开anaconda控制台 (记住是anaconda3下面的prompt,并且右击“以管理员身份运行”)
执行命令:
conda create -n tensorflow python=3.5
3. 进入虚拟环境
执行命令:
activate tensorflow
4. 安装anaconda-navigator
执行命令:
conda install anaconda-navigator
这样Anaconda3下面就多了一个Navigator(原来只有Cloud)
5. 安装tensorflow虚拟环境下的tensorFlow
打开Anaconda Navigator,选择到tensorflow虚拟环境下再进行安装。
不过用navigator有一个坏处,就是版本是限定的,不能自己选择,如上图所示,都是1.8的版本,如果你刚好要装1.8的话还是可以的,但是我一开始装了1.8的,结果
ImportError: No module named 'tensorflow.contrib.slim'

所以后来我把navigator里面的tensorflow给卸载了,用如下命令来安装的。
anaconda search -t conda tensorflow –gpu
我后来安装的是1.4.0 版本的,就没有问题了。
![]()
6. 安装tensorflow环境下的spyder
打开Anaconda Navigator
安装完成后,就能使用tensorflow环境下的spyder
7. 在TensorFlow环境下安装opencv 3.0
conda install -c menpo opencv3=3.1.0
二、主要更改文件
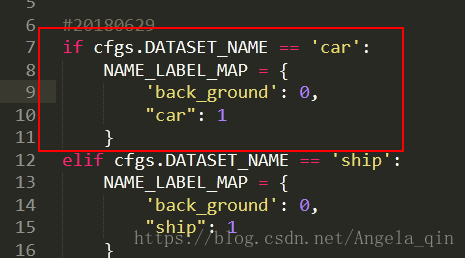
1. libs/label_name_dict.py
添加一项:
2. convert_data_to_tfrecord.py
1)生成训练集
这个python文件我基本都改了,因为我们数据集并不是xml格式的,所以把读取数据的逻辑部分给改动了,(具体数据集格式可以见上文)。
修改过的代码如下:
# -*- coding: utf-8 -*-
from __future__ import division, print_function, absolute_import
import sys
sys.path.append('../../')
import xml.etree.cElementTree as ET
import numpy as np
import tensorflow as tf
import glob
import cv2
from help_utils.tools import *
from libs.label_name_dict.label_dict import *
import os
VOC_dir = 'E:/study_materials/ECCV Vision Meets Drones Challenge/datasets/carData/carData/'
txt_dir = 'TrainAnnotations'
img_dir = 'TrainJPGImages'
save_name = 'train'
save_dir = 'E:/study_materials/ECCV Vision Meets Drones Challenge/FPN_Tensorflow-master(modified)/FPN_Tensorflow-master/data/tfrecords/'
img_format = '.jpg'
dataset = 'car'
#FLAGS = tf.app.FLAGS
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def convert_pascal_to_tfrecord():
save_path = save_dir + dataset + '_' + save_name + '.tfrecord'
mkdir(save_dir)
label_dir = VOC_dir + txt_dir
image_dir = VOC_dir + img_dir
writer = tf.python_io.TFRecordWriter(path=save_path)
for count, fn in enumerate(os.listdir(image_dir)):
if ((count+1)%2) != 0:
continue
else:
#print(count+1)
image_fp = os.path.join(image_dir, fn)
image_fp = image_fp.replace('\\', '/')
label_fp = os.path.join(label_dir, fn.replace('.jpg', '.txt'))
# print('label_fp:',label_fp)
img_name = str.encode(fn)
if not os.path.exists(label_fp):
print('{} is not exist!'.format(label_fp))
continue
# img = np.array(Image.open(img_path))
img = cv2.imread(image_fp)
sizeImg = img.shape
img_height = sizeImg[0]
img_width = sizeImg[1]
boxes = []
with open(label_fp,'r') as f:
for line in f.readlines():
line = line.strip().split(',')
# print('line:',line)
if line[4] != '0':
# print(line)
try:
line = [int(i) for i in line]
except:
line.pop()
line = [round(float(i)) for i in line]
# print('line',line)
#xmin, ymin, xmax, ymax, label
#原始标注,xmin,ymin,box_width,box_height,score,category,truncation,occlusion
if line[4] == 1 and line[5] == 4:
boxes.append([line[0],line[1],line[0]+line[2],line[1]+line[3],1])
gtbox_label = np.array(boxes, dtype=np.int32) # [x1, y1. x2, y2, label]
xmin, ymin, xmax, ymax, label = gtbox_label[:, 0], gtbox_label[:, 1], gtbox_label[:, 2], gtbox_label[:, 3], gtbox_label[:, 4]
gtbox_label = np.transpose(np.stack([ymin, xmin, ymax, xmax, label], axis=0)) # [ymin, xmin, ymax, xmax, label]
feature = tf.train.Features(feature={
# maybe do not need encode() in linux
'img_name': _bytes_feature(img_name),
'img_height': _int64_feature(img_height),
'img_width': _int64_feature(img_width),
'img': _bytes_feature(img.tostring()),
'gtboxes_and_label': _bytes_feature(gtbox_label.tostring()),
'num_objects': _int64_feature(gtbox_label.shape[0])
})
example = tf.train.Example(features=feature)
writer.write(example.SerializeToString())
view_bar('Conversion progress', count + 1, len(glob.glob(image_dir + '/*.jpg')))
print('\nConversion is complete!')
if __name__ == '__main__':
# xml_path = '../data/dataset/VOCdevkit/VOC2007/Annotations/000005.xml'
# read_xml_gtbox_and_label(xml_path)
convert_pascal_to_tfrecord()
- VOC_dir :数据集存放位置
- txt_dir :VOC_dir目录下面的存放Annotation文件的文件夹名
- img_dir :VOC_dir目录下面的存放图片的文件夹名
- save_name :后缀设置,选择保存成car_train.tfrecord 还是 car_test.tfrecord
- save_dir :转化成tfrecord格式之后,数据的保存位置
- dataset :改成car
运行文件,运行过程如下:
本项目一共有6133的训练集
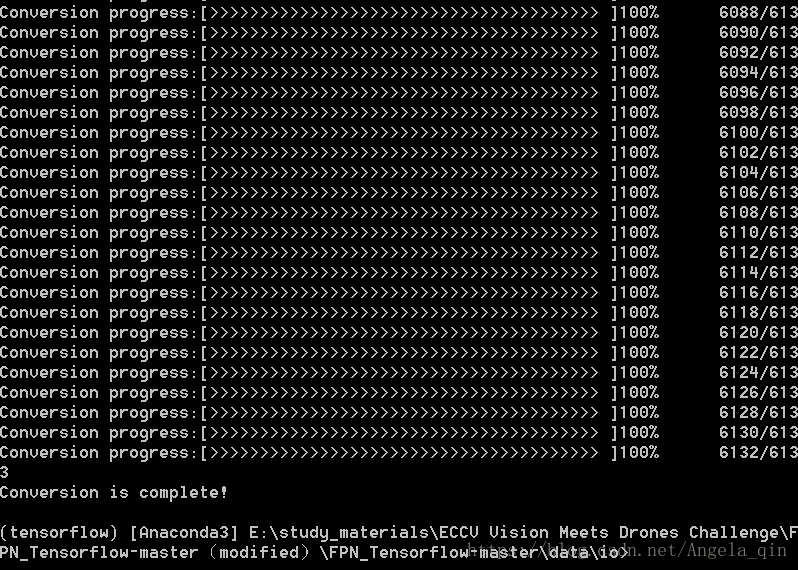
运行成功之后,如下图所示,多了一个car_train_tfrecord.py
2)生成测试集

运行成功之后,如下图所示,多了一个car_test_tfrecord.py
3. read_tfrecord.py
添加car数据集,修改转换成tfrecord之后的训练集和测试集数据位置

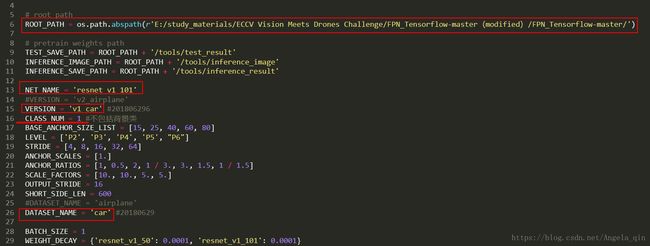
4. config.py
(备注:其他anchor之类的设置都没有动)
最后结果比我之前尝试过的原始的faster-rcnn和yolov3都要好。
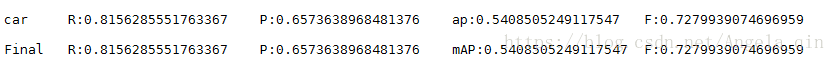
放一张结果图!