评分卡模型开发--定性指标筛选
转自:https://cloud.tencent.com/developer/article/1016327
定量指标是数值型的,我们还可以用回归的方法来筛选,那么定性的指标怎么办呢? R里面给我们提供了非常强大的IV值计算算法,通过引用R里面的informationvalue包,来计算各指标的IV值,即可得到各定性指标间的重要性度量,选取其中的high predictive指标即可。 有很多小伙伴不知道informationvalue是什么: 我大概说一下,IV值衡量两个名义变量(其中一个是二元变量)之间关联性的常用指标。
library(InformationValue)
library(klaR)
credit_risk<-ifelse(train_kfolddata[,"credit_risk"]=="good",0,1)
#将违约状态变量用0和1表示,1表示违约。
tmp<-train_kfolddata[,-21]
data<-cbind(tmp,credit_risk)
data<-as.data.frame(data)
factor_vars<-c("status","credit_history","purpose","savings","employment_duration",
"personal_status_sex","other_debtors","property",
"other_installment_plans","housing","job","telephone","foreign_worker")
#获取所有名义变量
all_iv<-data.frame(VARS=factor_vars,IV=numeric(length(factor_vars)),
STRENGTH=character(length(factor_vars)),stringsAsFactors = F)
#初始化待输出的数据框
for(factor_var in factor_vars)
{
all_iv[all_iv$VARS==factor_var,"IV"]<-InformationValue::IV(X=
data[,factor_var],Y=data$credit_risk)
#计算每个指标的IV值
all_iv[all_iv$VARS==factor_var,"STRENGTH"]<-attr(InformationValue::IV(X=
data[,factor_var],Y=data$credit_risk),"howgood")
#提取每个IV指标的描述
}
all_iv<-all_iv[order(-all_iv$IV),] #排序IV由结果可知,可选择的定性入模指标,如表3.12所示。

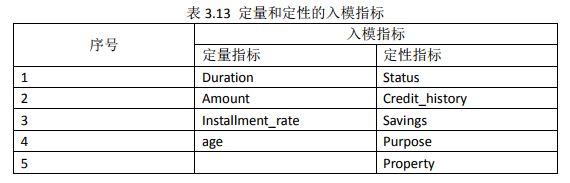
综上所述,模型开发中定量和定性的入模指标如表3.13所示。
对入模的定量和定性指标,分别进行连续变量分段(对定量指标进行分段),以便于计算定量指标的WOE和对离散变量进行必要的降维。对连续变量的分段方法通常分为等距分段和最优分段两种方法。等距分段是指将连续变量分为等距离的若干区间,然后在分别计算每个区间的WOE值。最优分段是指根据变量的分布属性,并结合该变量对违约状态变量预测能力的变化,按照一定的规则将属性接近的数值聚在一起,形成距离不相等的若干区间,最终得到对违约状态变量预测能力最强的最优分段。
这里再补充一点:
转自:https://zhuanlan.zhihu.com/p/27770760
变量选择:
选择上基本几个方面,客户物理属性,贷前贷中贷后的表现,这里不多叙述,比如逾期,余额等,此处不多叙述。
实际中,在实际应用场景,很多很根据业务背景,构造特征变量(或者称为衍生变量),
形如

x,y和z都是变量,a和b是系数,当然还有很多形式,这方面我请教过很多人,似乎并没有可以套用的经验模板,只能看各位的脑洞了。
而因变量,一般选舆情90天以上的客户标记为0(坏客户),其他为1(好客户)
变量筛选
这里学校的理论都有一堆。
单变量:归一化,离散化,缺失值处理
多变量:降维,相关系数,卡方检验,信息增益。决策树等。
这里讲一种行业经常用的基于IV值进行筛选的方式。
首先引入概念和公式。
IV的全称是Information Value,中文意思是信息价值,或者信息量。
求IV值得先求woe值,这里又引入woe的概念。
WOE的全称是“Weight of Evidence”,即证据权重。
首先把变量分组(怎么分后面说),然后对于每个组i,对于第i组有:
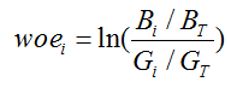
其中 是第i组坏客户数量(bad), 是整体坏客户数量。同理,G就是good,好客户的意思。

woe反映的是在自变量每个分组下违约用户对正常用户占比和总体中违约用户对正常用户占比之间的差异;从而可以直观的认为woe蕴含了自变量取值对于目标变量(违约概率)的影响
而IV值得公式如下:
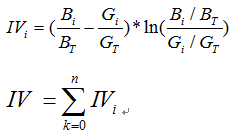
我们可以看到IV值其实是woe值加权求和。这个加权主要是消除掉各分组中数量差异带来的误差。
比如如果只用woe的绝对值求和,如果一些分组中,A组数量很小,B组数量很大(显然这样的分组不合理),这是B的woe值就很小,A组很大,求和的woe也不会小,显然这样不合理。比如:

最后我们可以根据每个变量VI值的大小排序去筛选变量。VI越大的越要保留。
变量处理
变量离散化:
评分卡模型用的是logistics,基本上都需要变量离散化后,效果才比较好。
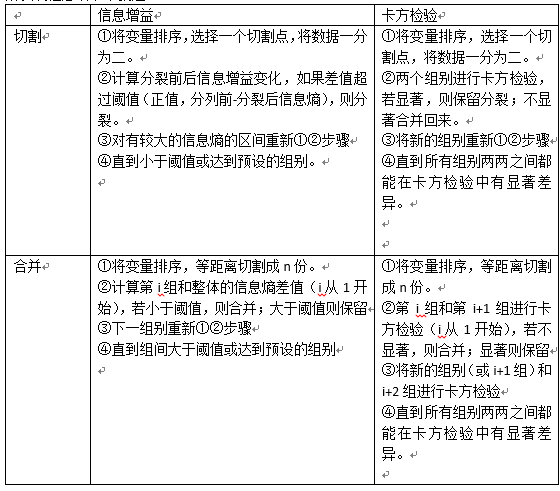
离散化一般有几种方式:合并和切割。
合并:先把变量分为N份,然后两两合并,看是否满足停止合并条件。
切割:先把变量一分为二,看切割前后是否满足某个条件,满足则再切割。
而所谓的条件,一般有两种,卡方检验,信息增益。
传送门:卡方检验 卡方检验-百度百科
信息增益 百度百科-信息增益
所以流程总结下来就是
哑变量:
当一些变量是非等级的字符串变量怎么办呢?
比如职业ABC,有的人写成123,其实这样就会有很大误差,ABC3种职业本无关系,但变为123后,1 2之间和1 3之间,似乎前者更加密切,对于模型来说(2-1<3-1)。所以我们需要将其变成哑变量。形如:

N组变量用M个变量的0和1来代替(M肯定小于N),在用这些新变量拟合模型。