Linux Ubuntu虚拟机 实验分析
实践项目名称: Linux内核分析
一、实践目的
1. 在Ubuntu系统条件下,学会使用虚拟机安装Ubuntu操作系统
2. 掌握组创建、用户创建,并授权。
3. 学会配置C语言编程环境,完成C程序运行。
4. 学会使用fork()系统调用进行进程创建,查看创建的进程。
5. 学习创建如下的进程关系,并解释创建过程。
二、实践内容
1. 在计算机上用虚拟机形式安装linux,虚拟机可采用VmWare或VirtualBox。Linux用Ubuntu或CentOS。
2. 完成组创建、用户创建,并授权。分别命名为testgroup和testuser.
3. 配置C语言编程环境,完成hello world程序运行。
4. 使用fork()系统调用进行进程创建,查看创建的进程。
5. 创建如下的进程关系,并解释创建过程。
三、实践的具体实现过程
- 虚拟机的构建:
首先,下载Vmware虚拟机安装Ubuntu操作系统。

上图为Ubuntu官网下载。下载地址为:(建议使用迅雷下载)
https://ubuntu.com/download/server/thank-you?version=19.04&architecture=amd64
打开Vmware软件,选择新建虚拟机选项。

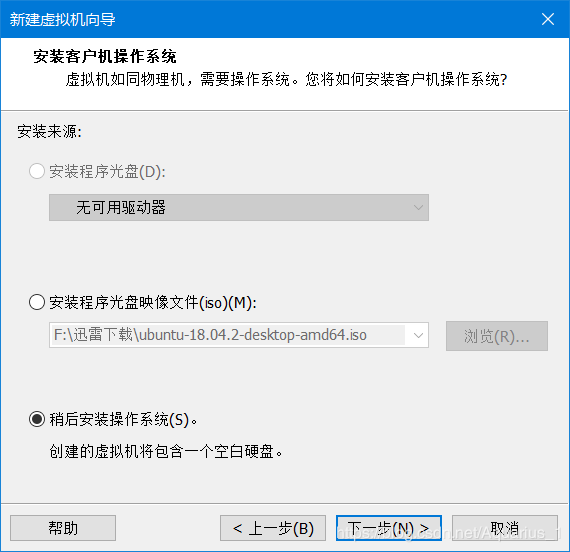
在创建Ubuntu虚拟机时,要在选择系统界面提示框中选择“稍后安装操作系统”;
若选择“安装程序光盘映像文件”会导致虚拟机在安装系统时会出现死机的状态。
选择Linux
选择Ubuntu64位
在创建完成一个虚拟机后(未安装系统),要对其硬件进行配置。
对于Ubuntu虚拟机,要求最小内存为2GB,

并且我们要对虚拟机安装Ubuntu系统,在“虚拟机设置中”,选择“CD/DVD”,找到“使用ISO映像文件”选项,找到刚刚下载的Ubuntu系统并确定。虚拟机再次打开是便会自动安装Ubuntu系统了。

现在这就是一台完整的Ubuntu虚拟机了。
2、完成组创建、用户创建,并授权。分别命名为testgroup和testuser.
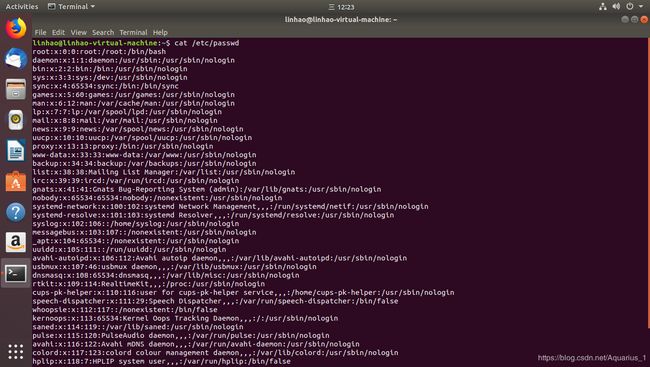
- 登录Ubuntu系统,查看所有用户,需要查看/etc/passwd文件
cat/etc/passwd
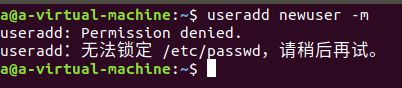
- 创建一个用户,使用命令
useradd newuser -m
useradd后是用户的名字
-m代表创建用户的同时创建该用户的home目录
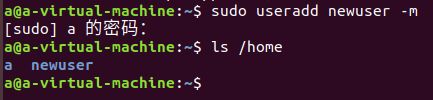
- 提示没有权限,使用sudo授权创建
sudo useradd newuser -m
查看/home目录已经有了新用户newuser的文件夹
用第一步的查看/etc/passwd文件内容,也有了newuser用户
创建用户时候,会自动创建该用户所在组,默认组名和用户名一样。通过
cat /etc/group
查看

![]()
- 切换到newuser用户,命令如下
su - newuser

- 不能正常切换,需要先设置密码,命令如下:
sudo passwd newuser
再次进行切换,可以正常登录
su - newuser
‘-’的意义是切换过来直接到用户的主目录
可以使用pwd查看当前目录
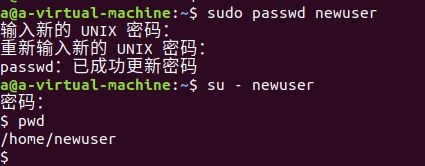
- 默认新建的用户没有sudo权限,要赋给sudo权限要在有sudo权限的用户使用以下命令
sudo usermod -a -G adm newuser
sudo usermod -a -G sudo newuser
这两句是将newuser用户添加到adm组和sudo组

- 再切回newuser用户使用sudo创建文件夹就可以了
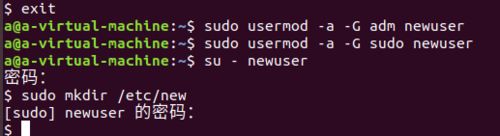
- 配置C语言编程环境,完成hello world程序运行。
先在虚拟机上安装Vim软件,用于编写代码。
编写一个test1.cpp的程序,
Ctrl + Alt + T打开Ubuntu下的cmd。
使用cd命令打开test1.cpp所在的文件夹的位置。
再对其进行编译。使用g++ test.cpp -o test1(如果是C则为gcc)
所使用的语言 + 文件名.文件类型 + -o 文件名
会出现test1这个文件,在cmd上运行这个文件即可。

- 使用fork()系统调用进行进程创建,查看创建的进程。
实验代码:
#include
#include
#include
int main()
{
printf("1\n");
printf("PID = %d ",getpid());
fork();
printf("PID = %d, PPID = %d\n",getpid(),getppid());
printf("2\n");
return 0;
}
对其进行编译:
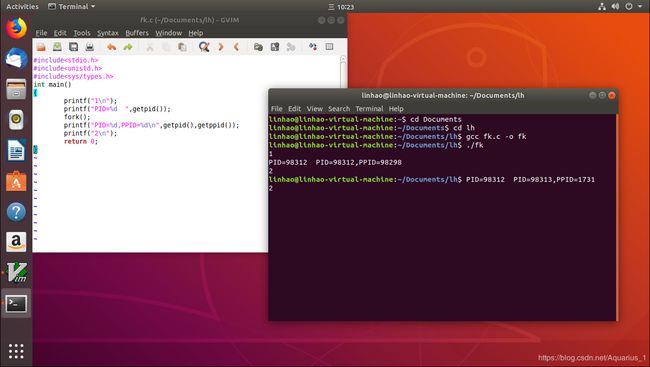
我们执行完fork.c文件后发现多一个2
这是我们获取进程的代码,PID为当前进程ID,PPID为父进程ID
生成两个进程,其中一个进程是原先的进程,而且父进程不一样
分析内核:fork系统之前只有一个进程,fork之后又两个进程,其实在fork之前有一个PCB(内核state_struct)指向代码段,数据段,堆栈段,fork之后生成新的PCB,复制一份代码段,数据段,堆栈段,PCB函数指针指向代码段,数据段,堆栈段。此时有两个PCB,则有两个进程。复制前PCB函数指针指向fork系统调用,复制完也是指向系统调用。故代码都是从fork系统调用开始跑,所以fork之后的代码实现两次(两个进程各自实现一次)。
然后我们对fork()函数进行分析。
实验代码:
#include
#include
#include
int main()
{
int cnt = 0;
int flag = fork();;
if(flag > 0)
{
printf("cnt = %d\n",cnt);
printf("cnt address = 0x%x\n",&cnt);
}
else if(falg == 0)
{
cnt =10;
printf("cnt = %d\n",cnt);
printf("cnt address = 0x%x\n",&cnt);
}
else
{
printf("ERROR!\n");
}
return 0;
}
实验截图:

实验分析:
我们必须知道fork系统调用有返回值,返回值为0则是子进程,大于0为父进程
我们可以看到结果是值不一样,但是地址却是一样的,值不一样是因为我们赋值了,所以拷贝的时候也变化了,但是地址还是一样
内核分析:其实内核里面有一个逻辑内存又成虚拟内存,父进程指向虚拟内存访问到变量count,当拷贝的时候,子进程拷贝了父进程的虚拟内存,所以他们的地址是一样。当我们变量改变的时候,其实物理内存是改变了,但是是虚拟内存指向的变量,而我们在终端只能看到虚拟内存,并不能看到物理内存。(这种方式称为copy-on-write 写入时候才拷贝,访问的时候还是原来变量)为什么要有这种方式呢?有时候父进程太大,子进程又用得内存不多,原样拷贝父进程浪费太多内存,所以在写的时候才来分配内存。
- 创建如下的进程关系,并解释创建过程。
我们知道,Linux下父进程可以使用fork 函数创建子进程,但是当父进程先退出后,子进程会不会也退出呢?
实验代码:
#include
#include
#include
#include
int main()
{
int pronum;
int pid = fork();
int cnt = 0;
while(pid == 0)
{
printf("PPID = %d\n",++pronum);
cnt++;
if(cnt>=3)
{
exit(0);
}
}
printf("PID = %d\n",pronum);
return 0;
}
实验截图:

代码分析:
首先按代码解释应该先顺序执行三个子进程,即pronum为1001,1002和1003.而后创建完三个子进程后,系统被强制退出exit(0);父进程1000不执行。
但是由执行结果可知:
可以看出父进程1000首先退出,退出前子程序的pronum为1003, 退出后子进程的PPID变为了 1.说明在执行子进程前,系统会先执行父进程,父进程退出后的子进程由 init 超级进程1领养。而该进程是不绝不会退出的。