Python爬虫初体验(2):多线程的应用及爬取中的实际问题
前情提要:Python爬虫初体验(1):利用requests和bs4提取网站漫画
前几天有些放松懈怠,并没有做多少事情……这几天要加油了!7月的计划要抓紧时间完成!
今天疯狂肝这个程序,算是暑假睡得最晚的一天了……(不过程序仍然有问题)
好的废话不多说,进入正题
总结了下上次的爬虫体验。虽然能保证稳定下载,但是下载 50 张XKCD漫画花费的时间达到了将近 10 分钟,效率比较低。
所以这次学习了多线程,以求达到较快下载完全部 2000 余张漫画的目标。(另外配合 V 姓网络加速工具保证连接外网的质量)
额外加入了 threading 模块来实现多线程。
另外,改进了一下代码风格,变量名称
threading 库中,Thread() 是进行多线程操作的关键。
在这里简单的应用:threading.Thread(target=xxxx, args=(), kwargs=None)
(target 指向函数本身,args 为向目标函数传递的常规参数,kwargs 为传递的关键字参数)
然后!
一样的方法去弄就可以了……
……
其实并不行。必须要把提取—解析—下载—存储的全过程函数化,这样才能实现多线程。
于是索性把所有过程都写成了函数里……看起来虽然增加了代码量,但是用起来就会很方便。
这里出现了一个问题:我开了 5 个线程,假如图片一共有 2000 张还行,有 2003 张怎么办?
emm,前 4 个线程下载 401 张图,第 5 个下载 399 张图就可以啦!
但是,如果前 400 张图比较小,第 401-800 张图比较大,这样的话第一个线程结束时间远早于第二个,如何解决?
其实可以挨个下载:不预先分配每个线程下载哪些图片,直接
……
吐槽:居然花了我 8 个小时来搞这段代码!没想到这部分是这么难弄,
搞的来和当年学 OI 时有一样的心情了。(心情简单.jpg)
不得不说,学 OI 的时候调试代码的过程,和现在很类似。只是这里涉及更多的是实际操作而非算法。
实际操作就要考虑异常,异常处理,维护,等等。所以花时间也是避免不了的啦……
然后就可以继续等待它慢慢扒图……
……
……
然后就发现了一堆莫名其妙的错误!呜呜呜……
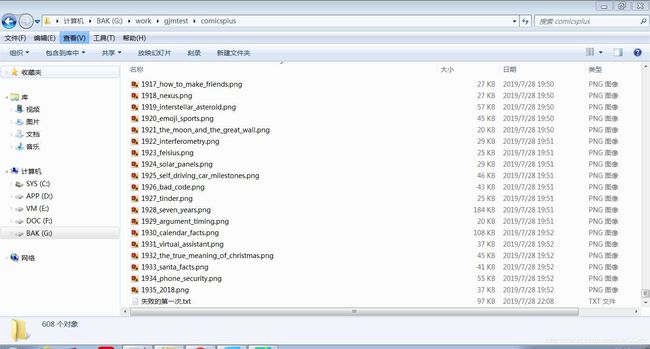

(一共下载了 607 张图片,最后 5 个线程全部断掉了……为什么我设置了超时重试都还会 Timeout Error……QAQ)
(最好笑的还是 retry 4 in 3 times……这个是如何做到的)
再来。
后来发现,抛出异常时,仅仅针对 Readtime Error 的异常来解决问题。还有 Connection Error 等没有处理。这个是最主要的问题。
某些地方写入文件会有异常?嗯,这个暂时不了解原因。好像是图片的链接读取错误?
于是加入了两种连网的错误处理。
为了防止连网出错,特意把重试次数设为了 4 次,超时 Timeout 设为了 4 秒。
……
然而还是出错了!
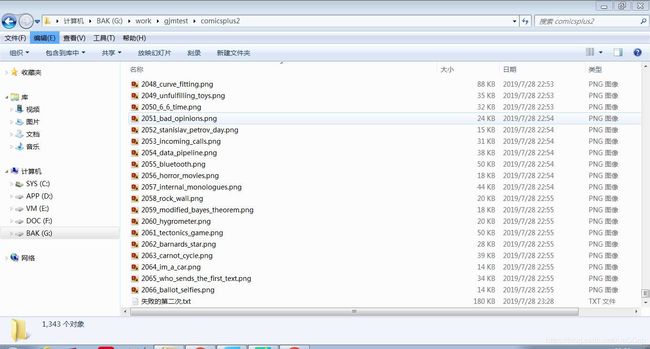
这次总算是查到了失败的原因。
XKCD漫画还真的有些不同寻常,例如:第 404 张漫画竟然……就是一个 404 not found 的网站???
第 1350,2067 张漫画居然有用户交互的方式?
怪说不得线程又终止在这里了……
先把它们记下来,晚些时候再去解决吧。
发一个不规范的源码存档:
#! python3
# Upgraded version. Use Threading to speed-up the download process.
import os,requests,bs4,threading,math,time
url = "http://xkcd.com/"
errList = []
mutex = threading.Lock()
def createDir():
os.chdir("G:\\work\\gjmtest")
os.makedirs(".\\comicsplus2", exist_ok=True)
os.chdir(".\\comicsplus2")
def getResource(link,num=None,notify=False,tle=4): # default timeout: 3 seconds
count = 1
while count <= 4:
try:
if num is None:
res = requests.get(link, timeout=tle)
else:
res = requests.get(link+str(num), timeout=tle)
res.raise_for_status()
return res
except:
count += 1
if notify is True and count <= 4:
print("Timeout. Retry %d in 3 times..." % count)
if num is None:
raise TimeoutError("Can't connect to "+url+".Please check your Internet configuration.")
else:
raise TimeoutError("Can't connect to "+url+str(num)+".Please check your Internet configuration.")
def getSoup(res):
soup = bs4.BeautifulSoup(res.text, features="html.parser")
return soup
def getImageNum(soup):
b = soup.select("#middleContainer") # find image num
picNumString = b[0].text
picNumPosStart = picNumString.find("xkcd.com")
picNumPosEnd = picNumString.find("Image URL")
picNum = picNumString[(picNumPosStart + 9):(picNumPosEnd - 2)]
return picNum
def getImageUrl(soup):
k = soup.select("#comic img")
picUrl = k[0].get("src") # //img.xxxxxx
return picUrl
def writeFile(num, pic_res, pic_link, path="G:\\work\\gjmtest\\comicsplus2\\"):
f = open(path + num + '_' + os.path.basename(pic_link), "wb")
for chunk in pic_res.iter_content(100000):
f.write(chunk)
f.close()
def errorRetry():
for i in errList: # for each picture number (error occurred)
download(i)
def download(i): # download particular picture
print("Downloading picture %d..." % i)
try:
res = getResource(url, num=i, notify=True)
except:
mutex.acquire()
errList.append(i)
print("Error occurred: picture %d !!!" % i)
mutex.release()
return
print("Parsing webpage of picture %d..." % i)
soup = getSoup(res)
num = getImageNum(soup)
picurl = getImageUrl(soup) # picture resources
picres = requests.get("http:" + picurl)
print("Writing picture %d..." % i)
writeFile(num, picres, picurl)
print("Succeeded in picture %d." % i)
def downloadSeq(start, end): # [start, end)
for i in range(start, end):
download(i)
def createThread(total_num):
count = 1
th = 0
thread_list = []
remain = total_num
while remain > groupNum:
thread_list.append(threading.Thread(target=downloadSeq, args=(count, count + groupNum)))
thread_list[th].start()
remain -= groupNum
count += groupNum
th += 1
thread_list.append(threading.Thread(target=downloadSeq, args=(count, total_num)))
thread_list[th].start()
for t in thread_list:
t.join()
def getTotalImage(): # one-time use
try:
res = getResource(url)
except:
print("Your network is too bad!")
exit()
soup = getSoup(res)
num = int(getImageNum(soup))
print("Total image number is %d." % num)
print("Downloading process started.")
return num
if __name__ == "__main__":
startTime = time.time()
createDir()
totalNum = getTotalImage()
threads = 5
groupNum = math.ceil(totalNum / threads)
createThread(totalNum)
errorRetry()
endTime = time.time()
timeCost = round(endTime - startTime, 1)
print("Done. Total time: %s sec." ,str(timeCost))
我保证,以后一定要 11 点准时睡觉 = =||
不说了,累死啦~赶快滚去睡