HIVE Streaming小结
HIVE中的查询可以结合使用非java语言的脚本(比如shell、python、perl等),达到另一种处理数据的方式。
下面通过自己亲自实践的测试程序说明Streaming的常见用法:
(1)恒等变换
(2)改变类型
(3)投影变换
(4)操作转换
(5)使用分布式内存
(6)CLUSTER BY、DISTRIBUTE BY、SORT BY
(7)计算cogroupStreaming
HIVE是通过利用或扩展Hadoop的组件功能来运行的,常见的抽象有InputFormat、OutputFormat、Mapper、Reducer,还包含一些自己的抽象接口,例如SerializerDeserializer(SerDe)、用户自定义函数(UDF)和StorageHandlers。
这些组件都是java组件,不过hive将这些复杂的底层实现隐藏起来了,而提供给用户通过SQL语句执行的方式,而不是使用java代码。
Streaming 提供了另一种处理数据的方式。在streaming job中,Hadoop StreamingAPI会为外部进程开启一个I/O管道。然后数据会被传给这个进程,然后数据从标准输入中读取数据,然后通过标准输出来写结果数据,最后返回到Streaming API job。尽管HIVE并没有直接使用Hadoop的StreamingAPI,不过他们的工作方式是一致的。
这种管道计算模型对于Unix操作系统以及其衍生系统,如Linux和Mac OS X的用户来说是非常熟悉的。
提示:
Streaming的执行效率通常会比对应的编写UDF或改写InputFormat对象的方式要低。管道中的序列化和反序列化数据通常是低效的。而且以通常的方式很难调试整个程序。不过,对于快速原型设计和支持非java编写的已有的代码是非常有用的。对于那些不想写java代码的HIVE用户来说,这也是一个高效的方式。
HIVE中提供了多个语法来使用Streaming,包括:MAP()、REDUCE()、TRANSFORM()。
需要注意的是,MAP()实际上并非可以强制在map阶段执行Streaming,同样REDUCE()实际上并非可以强制在reduce阶段执行Streaming,所以推荐使用TRANSFORM(),这样可以避免误导读者对查询语句产生疑惑。
对于我们的Streaming例子,将使用一个表名为a的小表,其中有两个字段,分别是col1和 col2,它们都是INT类型的,表中有2行数据:
hive> create table a (col1 int,col2 int)
> row format delimited fields terminated by '\t';hive> insert into a values (4,5);
hive> insert into a values (3,2);

(1)恒等变换
最基本的Streaming job就是恒等运算。/bin/cat 这个shell命令可以将传递它的数据直接输出,所以满足恒等运算。本例中,/bin/cat 这个shell假定已经安装到所有的TaskTracker节点了。实际上任意的Linux系统都会包含这个脚本的!稍后,我们将展示一些程序没有安装到集群中时,通过hive如何将这些程序“加载”到集群中。
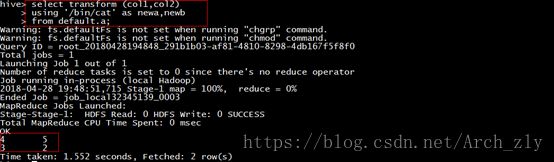
hive> select transform (col1,col2)
> using '/bin/cat' as newa,newb
> from default.a;
注意:transform 的参数字段名必需和实际定义的一致,否则会报错:
正确执行结果:
(2)改变类型
TRANSFORM返回的字段的数据类型默认是字符串类型的。不过可以通过如下语法将类型转换为其他数据类型:
hive> select transform (col1,col2)
> using '/bin/cat' as (newa int,newb double) from a;
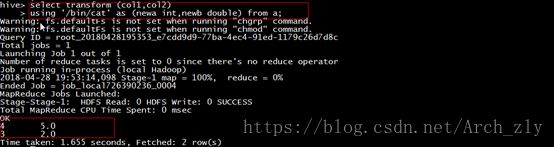
Streaming中可以使用cut命令提取或者映射出特定的字段。换句话说,可以达到和select相同的效果:
hive> select transform (col1,col2)
> using '/bin/cut -f1'
> as newa,newb from a;

可以注意到,上面的例子中,查询从外部处理过程中返回的只有一个字段,而实际期望的是两个字段,因此字段newb的值总是null。默认情况下,TRANSFORM需要两个字段,不过实际上可以为比其小的任意个字段:
hive> select transform (col1,col2)
> using '/bin/cut -f1'
> as newa from a;

(4)操作转换
/bin/sed 程序是一个 流编辑器,其可以接受输入数据流,然后按照用户的指定进行编辑,最后将编辑后的结果到输出数据流中。如下面的例子,将字符串“4”替换为字符串“10”:
hive> select transform (col1,col2)
> using '/bin/sed s/4/10/'
> as newa,newb from a;
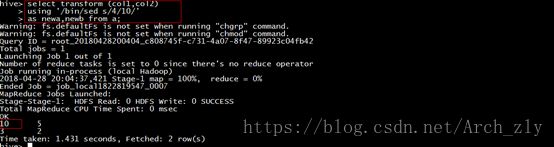
(5)使用分布式内存
到目前为止所列举的Streaming例子都是UNIX系统或其衍生系统自带的如cat或sed这样的系统脚本程序。当一个查询所需要的文件没有在每个TaskTracker上事先安装好时,用户需要使用分布式缓存将数据或者程序传输到集群中,然后在job完成后会清理掉这些缓存的数据和文件。(Hadoop的分布式缓存可以对缓存内的文件按照LRU原则进行删除,因此并非是job一结束就立即删除)。
这个功能非常有用,因为在大规模集群上安装或者卸载大量的小组件会成为一件很有负担的事情。同时,缓存中会独立保存每个job的缓存文件,而不会相互干扰。
下面是一个将摄氏度转换为华氏温度的shell程序脚本:
#!/bin/bash
while read LINE
do
res=$(echo "scale=2;((9/5) * $LINE ) + 32" | bc)
echo $res
done
可以在本地测试脚本,脚本不会提示输入,输入100,然后按回车键,这时这个进程会通过标准输出打印出 212.00;输入拎一个值,会得到另一个相应的结果。用户可以持续的输入数值,也可以通过 Ctrl +D终止输入:

HIVE的ADD FILE功能可以将文件加入到分布式缓存中。而被增加的文件会被存储到每个task节点机器的当前工作目录下。这样可以使得transform task直接使用脚本而不用确定到哪里去找这些文件:
首先把本地脚本放到hive的根目录下(每个人的配置可能不同):
[root@localhost shell_test]# cp ctof.sh /root然后可以直接使用“相对路径”的分布式文件执行脚本:
hive> add file ${env:HOME}/ctof.sh;![]()
hive> select transform (col1) using 'ctof.sh' as convert from a;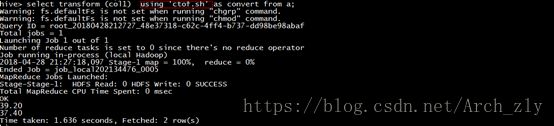
笔者在实际测试上面的例子中,遇到下面错误:
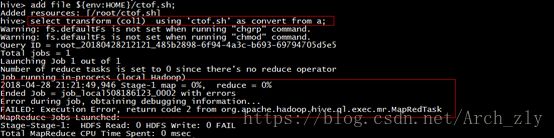
最后解决方案是,在根目录下(root)中,发现sh脚本没有可执行权限,所以增加+x可执行权限:
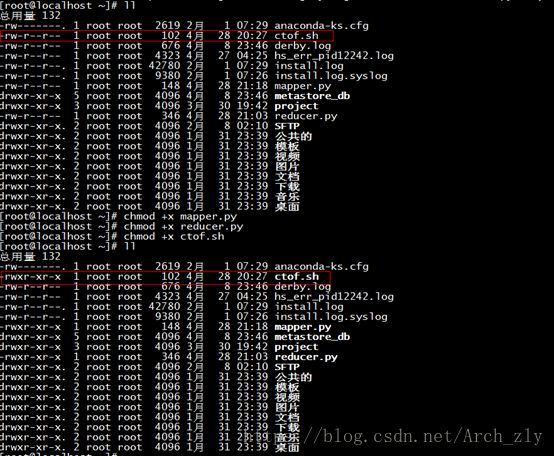
增加执行权限之后,测试程序可以正确运行。(下面的测试python脚本程序同理)
(6)CLUSTER BY、DISTRIBUTE BY、SORT BY
Hive提供了语法来控制数据是如何被分发和排序的。这些功能可以应用在大多数的查询中,不过在处理Streaming时显得特别有用。例如,具有相同键的数据需要分发到同一个处理节点中,或者数据需要按照指定的列或者指定函数进行排序。hive提供了多种方式来控制这种行为。
第一种控制方式就是cluster by 语句,其可以保证类似的数据可以分发到同一个reduce task中,而且保证数据是有序的。
为了演示cluster by的用法,我们使用一个特殊的例子:通过另一种方式来实现Word Count算法。现在,我们使用transform功能和2个python脚本,一个脚本用于将读取的每行内容分割为单词,另一个脚本用于接收字频数据流以及单词的中间计数值,然后对每个单词的次品求和汇总。
下面是第一个python脚本,其可以按照空格将每行内容分割为单词:
mapper.py(注意要增加可执行权限,同上面的ctof.sh文件)
import sys
for line in sys.stdin:
words = line.strip().split()
for word in words:
print “%s\t1” %(word.lower())
这个脚本从通用模块sys中引入常见的函数,然后循环获取“标准输入流”中的每行数据,然后按照空格划分每行的单词,生成一个单词集words,然后遍历整个集合并输出每个单词和对应的词频。
在展示第二个脚本之前,我们边讨论下传递给这个脚本的数据。我们的transform hive查询中,我们将对第一个脚本的输出词组使用cluster by 。这样可以将所有相同的单词分配到同一个组中,每行一对数据,每对的数据形式是单词\t次数:
word1 1
word1 1
word1 1
word1 1
…
因此第二个脚本会复杂些,因为其需要缓存当前处理的单词,以及迄今为止这个单词出现的次数。当处理下一个单词时,这个脚本需要输出上一个单词的频数,然后重置缓存。
下面是第二个脚本:
reducer.py(同样注意执行权限)
import sys
(last_key,last_count) = (None,0)
for line in sys.stdin:
(key,count) = line.strip().split(“\t”)
if last_key and last_key != key:
print “%s\t%d” % (last_key,last_count)
(last_key,last_count) = (key,int(count))
else:
last_key = key
last_count += int(count)
if last_key:
print “%s\t%d” % (last_key,last_count)
不妨先看一下第一个脚本的执行结果:
hive > select transform (line) using '${env:HOME}/mapper.py'
> as word,count from docs;

执行完整的hive查询,并将结果存入word_count结果表中:
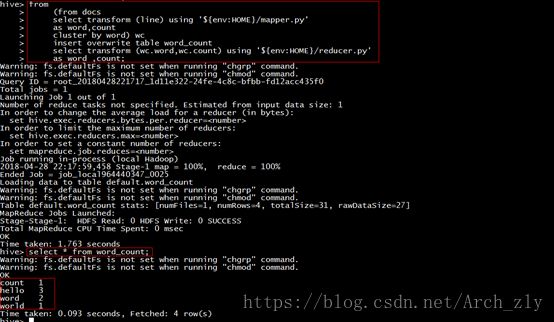
using语句指定了python脚本的绝对路径。
替代cluster by 的最方便的方式就是使用 distribute by 和sort by ,使用它们的常用场景是:用户希望将数据按照某个字段划分,然后按另一个字段排序。
实际上cluster by word等价于distribute by word sort by word asc。
如下面的程序就是按照降序排序:
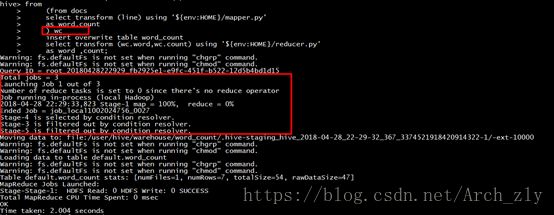
from
(from docs
select transform (line) using '${env:HOME}/mapper.py'
as word,count
distribute by word sort by word desc) wc
insert overwrite table word_count
select transform (wc.word,wc.count) using '${env:HOME}/reducer.py'
as word ,count;
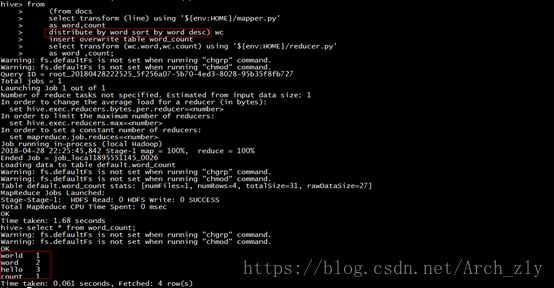
可以对比和cluster by word执行的结果。
world 1
word 2
hello 3
count 1对比之前cluster by 的结果:
count 1
hello 3
word 2
world 1使用cluster by 或者使用结合sort by 的distribute by是非常重要的,因为如果没有这些指示,hive可能无法合理的并行执行job,所有的数据可能都会分发到同一个reducer上,这样会导致整体job执行时间延长。
如果没有指定cluster by 或者使用结合sort by 的distribute by,那么最后的结果是不正确的:
from
(from docs
select transform (line) using '${env:HOME}/mapper.py'
as word,count
) wc
insert overwrite table word_count
select transform (wc.word,wc.count) using '${env:HOME}/reducer.py'
as word ,count;
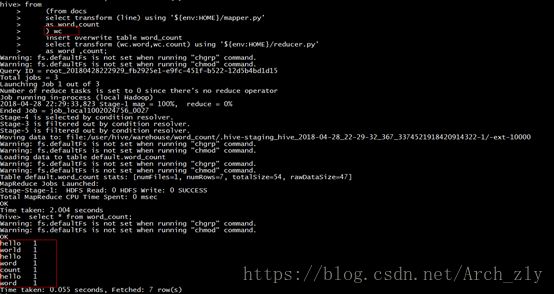
可以对比一下两者的查询日志信息:

对比日志信息可以发现,没有reduce过程。
通常情况下,使用Streaming是为了将非java代码结合到hive中。使用java编写Streaming也是可以的,Hive中包含了GenericMR API 来试图为Streaming提供类似于MapReduce API的接口。
(7)计算cogroup
在MapReduce程序中,经常会对多数据进行join连接处理,然后使用transform进行处理。使用union all和cluster by,我们可以实现cogroup by操作的常见效果。
假设我们有多个不同源的日志文件,它们具有相同的schema。我们希望将它们合并起来,然后通过一个reduce_script进行分析:(这仅是一个模板)
from(
from(
from log1 o1
select o1.id,o1.order_id ……
union all
from log2 o2
select o2.id,o2.order_id ……
) union_msg
select union_msg.id, union_msg.order_di ….
cluster by union_msg.id
) map
insert overwrite table log_analysis
select transform(map.id,map.order_id…) using ‘reduce_script’
as (id,order_id …);