reinforcement learing for visual object detection - 阅读笔记
2016CVPR的文章,从结构上来看和一般的强化学习 似乎有一些不一样。
在给定一张图像的情况下(目标区域蕴含在当前图像中)我们需要从图像的子区块中找到和目标区块最接近的子区块。图像的子区块可以使用简单的bounding-box,也可以使用现在比较新的建议生成方法(我们仅对bounding-box的情况进行讨论,子区块的
选择方式并不影响算法效果)
reinforcement learing for visual object detection
检测流程
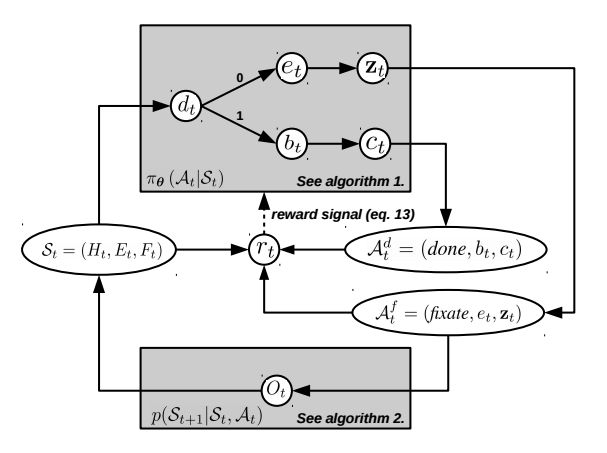
检测整体流程如图。从当前检测区域的状态描述 St 开始,分类器会对当前状态进行评估并给出终止信号。如果终止信号0,则选取新的evidence region( et )并以 et 为参考输出下一步需要执行的动作,并观察执行效果得到新的状态。如果终止信号为1,说明当前区域包含有需要检测的目标,此时将依据信度最高的窗口执行选定bounding box的动作。并退出迭代。
下面,我们将就流程中的每一个状态模块进行介绍。
当前状态 St
当前状态 St 是由观测区域的历史记录 Ht ,选择的证据区域(evidence region)的历史记录 Et 以及修订历史(fixation history) Ft 决定。
Ht :搜索区域的历史记录,每个搜索窗口都会计算对应的置信度。并且作为证据区域的候选区域。
Et :模型使用选择验证区域来决定下一步要探索的区域。其是在搜索区域的历史记录中选择出来的,为了保证选择多样性,所有的选择验证区域只能够最多被使用一次。所以 Et 实际上是记录被使用过的区域的集合
Ft :搜索动作的历史记录
终止信号
终止信号是由当前搜索状态产生的,其表达式为:
而 v(St) 为当前状态的描述,具体表达式为:
其中, asmax({fc(ri)}r∈Ht) 为所有搜索窗口中似然度最大窗口的值, t 为当前执行的步数, |Ht||R| 为当前已搜索区域占整个图像区域的比值,1为偏置系数 。
这样设置状态描述的原因是为了取得在正确率和搜索复杂度之间的均衡。当搜索步长过高或者搜索区域满足条件时,程序都会释放终止信号。终止信号的将决定下一步要执行 动作的不同。
执行动作
终止动作
Adt=(done,bt,ct) ,其中 bt 依然为目标标签, ct 为当前的区域为目标区域的置信度
终止信号为1时即执行终止动作,终止动作将依据搜索的历史记录计算目标的包围盒(bounding box),并计算响应最高的搜索窗口及其信度。
修订动作
修订(fixate)动作被记为: Aft=(fixate,et,zt) ,其中 et∈B 表示验证区域的下标。 zt∈R 表示下一步探索区域在图像中的位置。
当系统判断搜索没有终止的时候,系统会从以往的搜索历史中(若该窗口曾经作为验证区域使用过,则重新选择)寻找信度最大的窗口 et 作为验证区域,并通过该验证区域计算下一步应该执行的动作。
一旦选择了某个窗口作为验证区域,该区域会被用来决定一个下一步应该执行动作 zt 的高斯分布。
有:
新的验证区域的中心将作为下一次搜索的中心
新的验证区域方差
所以新的分布定义为:
其中 ∑Δ(et) 为之前所有验证区域产生方差的和。而 fp(et)=Δ(et)θTpq(et)+μ(et) 其中 θTpq(et) 为验证区域特征的一个线性组合。
所以:
交互与学习
每个迭代周期,系统会最终得到搜索的区域 bt 以及可信度 ct
在学习阶段,我们希望通过一系列的图像(记作 Bj ),随着信度方程 fc 得到最高信度区域。我们希望找到一组系数 θ=(θc,θd,θe,θp,∑p,σc) 来最大化寻找到区域的似然度。与此同时,我们希望最小化搜索区域,避免因为搜索区域增加而引起的搜索负担。最终我们的reward设置为:
其中 iou 为搜索区域与目标区域重叠部分的归一化。本文中系数 β=10−3 , α=30
第一个分支表示在未能搜索到目标且搜索动作未停止的时候获得和搜索区域相关的负reward
第二和第三组分支分布代表在终止信号出现寻找到目标和没有寻找到目标时候的reward
最终我们的优化目标在于:
结果分析
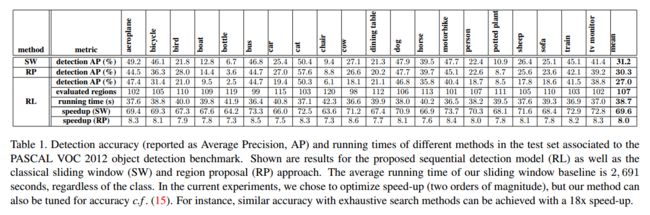

其他问题:
这些问题的详细表述在同一团队15年的论文【Multiple Instance Reinforcement Learning for Efficient Weakly-Supervised Detection in Images】中。
区域似然度的判别
判断各个区域是否存在内在的联系,从标注的角度来理解,其很难进行有效的数据标注。而且很多数据集并没有训练目标的ground truth。所以文章提出了采用眼动轨迹的方法来间接描述各个部分的似然度。根据实验,文献指出眼动仪的轨迹有30%的凝视数据刚好处于真实的目标区域中。文章希望利用这作为一个弱分类器的指标,得到画面到目标的似然度函数。