损失函数loss大总结(一)
分类任务loss:
二分类交叉熵损失sigmoid_cross_entropy:

TensorFlow 接口:
-
tf.losses.sigmoid_cross_entropy(
-
multi_class_labels,
-
logits,
-
weights=
1.0,
-
label_smoothing=
0,
-
scope=
None,
-
loss_collection=tf.GraphKeys.LOSSES,
-
reduction=Reduction.SUM_BY_NONZERO_WEIGHTS
-
)
-
tf.nn.sigmoid_cross_entropy_with_logits(
-
_sentinel=
None,
-
labels=
None,
-
logits=
None,
-
name=
None
-
)
keras 接口:
binary_crossentropy(y_true, y_pred)
二分类平衡交叉熵损失balanced_sigmoid_cross_entropy:
该损失也是用于2分类的任务,相比于sigmoid_cross_entrop的优势在于引入了平衡参数 ,可以进行正负样本的平衡,得到比sigmoid_cross_entrop更好的效果。

多分类交叉熵损失softmax_cross_entropy:
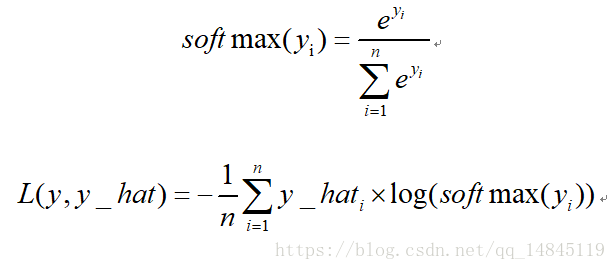
TensorFlow 接口:
-
tf.losses.softmax_cross_entropy(
-
onehot_labels,
-
logits,
-
weights=
1.0,
-
label_smoothing=
0,
-
scope=
None,
-
loss_collection=tf.GraphKeys.LOSSES,
-
reduction=Reduction.SUM_BY_NONZERO_WEIGHTS
-
)
-
tf.nn.softmax_cross_entropy_with_logits(
-
_sentinel=
None,
-
labels=
None,
-
logits=
None,
-
dim=
-1,
-
name=
None
-
)
-
tf.nn.sparse_softmax_cross_entropy_with_logits(
-
_sentinel=
None,
-
labels=
None,
-
logits=
None,
-
name=
None
-
)
keras 接口:
focal loss:
focal loss为凯明大神的大作,主要用于解决多分类任务中样本不平衡的现象,可以获得比softmax_cross_entropy更好的分类效果。

论文中α=0.25,γ=2效果最好。

dice loss:
2分类任务时使用的loss,本质就是不断学习,使得交比并越来越大。
TensorFlow 接口:
-
def dice_coefficient(y_true_cls, y_pred_cls):
-
'''
-
dice loss
-
:param y_true_cls:
-
:param y_pred_cls:
-
:return:
-
'''
-
eps =
1e-5
-
intersection = tf.reduce_sum(y_true_cls * y_pred_cls )
-
union = tf.reduce_sum(y_true_cls ) + tf.reduce_sum(y_pred_cls) + eps
-
loss =
1. - (
2 * intersection / union)
-
tf.summary.scalar(
'classification_dice_loss', loss)
-
return loss
合页损失hinge_loss:
也叫铰链损失,是svm中使用的损失函数。
由于合页损失优化到满足小于一定gap距离就会停止优化,而交叉熵损失却是一直在优化,所以,通常情况下,交叉熵损失效果优于合页损失。

TensorFlow 接口:
-
tf.losses.hinge_loss(
-
labels,
-
logits,
-
weights=
1.0,
-
scope=
None,
-
loss_collection=tf.GraphKeys.LOSSES,
-
reduction=Reduction.SUM_BY_NONZERO_WEIGHTS
-
)
keras 接口:
hinge(y_true, y_pred)
Connectionisttemporal classification(ctc loss):
对于预测的序列和label序列长度不一致的情况下,可以使用ctc计算该2个序列的loss,主要用于文本分类识别和语音识别中。
TensorFlow 接口:
-
tf.nn.ctc_loss(
-
labels,
-
inputs,
-
sequence_length,
-
preprocess_collapse_repeated=
False,
-
ctc_merge_repeated=
True,
-
ignore_longer_outputs_than_inputs=
False,
-
time_major=
True
-
)
keras 接口:
-
tf
.keras
.backend
.ctc_batch_cost(
-
y_true,
-
y_pred,
-
input_length,
-
label_length
-
)
编辑距离 edit loss:
编辑距离,也叫莱文斯坦Levenshtein 距离,指的是两个字符串之间,由一个转换成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
该损失函数的优势在于类似于ctc loss可以计算2个长度不等的序列的损失。
TensorFlow 接口:
-
tf.edit_distance(
-
hypothesis,
-
truth,
-
normalize=
True,
-
name=
'edit_distance'
-
)
KL散度:
KL散度( Kullback–Leibler divergence),也叫相对熵,是描述两个概率分布P和Q差异的一种方法。它是非对称的,这意味着D(P||Q) ≠ D(Q||P)。特别的,在信息论中,D(P||Q)表示当用概率分布Q来拟合真实分布P时,产生的信息损耗,其中P表示真实分布,Q表示P的拟合分布。
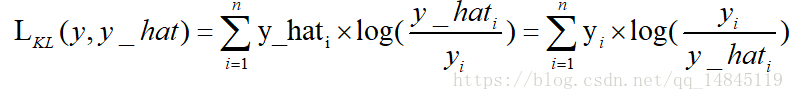

从上面式子可以看出,kl散度,也就是相对熵,其实就是交叉熵+一个常数项。
TensorFlow 接口:
-
tf.distributions.kl_divergence(
-
distribution_a,
-
distribution_b,
-
allow_nan_stats=
True,
-
name=
None
-
)
-
-
tf.contrib.distributions.kl(
-
dist_a,
-
dist_b,
-
allow_nan =
False,
-
name=
None
-
)
最大间隔损失large margin softmax loss:
用于拉大类间距离的损失函数,可以训练得到比传统softmax loss更好的分类效果。

最大间隔损失主要引入了夹角cos值进行距离的度量。假设bias为0的情况下,就可以得出如上的公式。
其中fai(seita)需要满足下面的条件。

为了进行距离的度量,在cos夹角中引入了参数m。该m为一个正整数,可以起到控制类间间隔的作用。M越大,类间间隔越大。当m=1时,等价于传统交叉熵损失。基本原理如下面公式

论文中提供的满足该条件的公式如下

中心损失center loss:
中心损失主要主要用于减少类内距离,虽然只是减少了累内距离,效果上却可以表现出累内距离小了,类间距离就可以增大的效果。该损失不可以直接使用,需要配合传统的softmax loss一起使用。可以起到比单纯softmax loss更好的分类效果。

回归任务loss:
均方误差mean squareerror(MSE)和L2范数:
MSE表示了预测值与目标值之间差值的平方和然后求平均
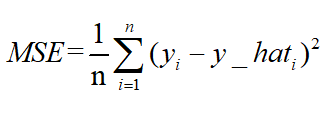
L2损失表示了预测值与目标值之间差值的平方和然后开更方,L2表示的是欧几里得距离。
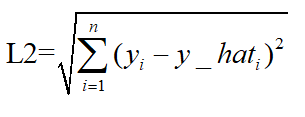
MSE和L2的曲线走势都一样。区别在于一个是求的平均np.mean(),一个是求的更方np.sqrt()

TensorFlow 接口:
-
tf.losses.mean_squared_error(
-
labels,
-
predictions,
-
weights=
1.0,
-
scope=
None,
-
loss_collection=tf.GraphKeys.LOSSES,
-
reduction=Reduction.SUM_BY_NONZERO_WEIGHTS
-
)
-
tf.metrics.mean_squared_error(
-
labels,
-
predictions,
-
weights=
None,
-
metrics_collections=
None,
-
updates_collections=
None,
-
name=
None
-
)
keras 接口:
mean_squared_error(y_true, y_pred)
平均绝对误差meanabsolute error(MAE )和L1范数:
MAE表示了预测值与目标值之间差值的绝对值然后求平均

L1表示了预测值与目标值之间差值的绝对值,L1也叫做曼哈顿距离

MAE和L1的区别在于一个求了均值np.mean(),一个没有求np.sum()。2者的曲线走势也是完全一致的。

TensorFlow 接口:
-
tf.metrics.mean_absolute_error(
-
labels,
-
predictions,
-
weights=
None,
-
metrics_collections=
None,
-
updates_collections=
None,
-
name=
None
-
)
keras 接口:
mean_absolute_error(y_true, y_pred)
MSE,MAE对比:
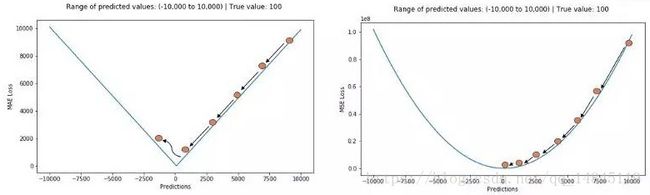
MAE损失对于局外点更鲁棒,但它的导数不连续使得寻找最优解的过程低效;MSE损失对于局外点敏感,但在优化过程中更为稳定和准确。
Huber Loss和smooth L1:
Huber loss具备了MAE和MSE各自的优点,当δ趋向于0时它就退化成了MAE,而当δ趋向于无穷时则退化为了MSE。

Smooth L1 loss也具备了L1 loss和L2 loss各自的优点,本质就是L1和L2的组合。

Huber loss和Smooth L1 loss具有相同的曲线走势,当Huber loss中的δ等于1时,Huber loss等价于Smooth L1 loss。
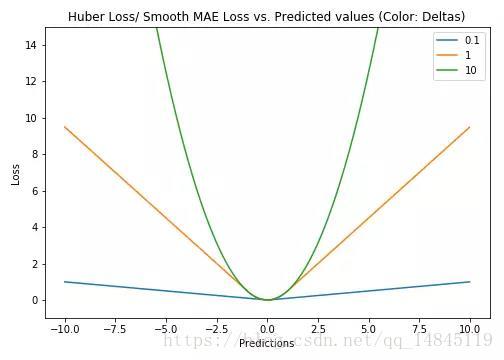
对于Huber损失来说,δ的选择十分重要,它决定了模型处理局外点的行为。当残差大于δ时使用L1损失,很小时则使用更为合适的L2损失来进行优化。
Huber损失函数克服了MAE和MSE的缺点,不仅可以保持损失函数具有连续的导数,同时可以利用MSE梯度随误差减小的特性来得到更精确的最小值,也对局外点具有更好的鲁棒性。
但Huber损失函数的良好表现得益于精心训练的超参数δ。
TensorFlow接口:
-
tf.losses.huber_loss(
-
labels,
-
predictions,
-
weights=
1.0,
-
delta=
1.0,
-
scope=
None,
-
loss_collection=tf.GraphKeys.LOSSES,
-
reduction=Reduction.SUM_BY_NONZERO_WEIGHTS
-
)
对数双曲余弦logcosh:

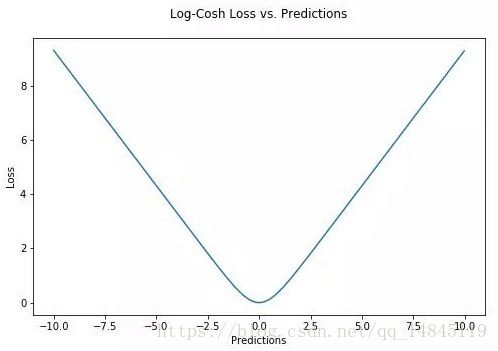
其优点在于对于很小的误差来说log(cosh(x))与(x**2)/2很相近,而对于很大的误差则与abs(x)-log2很相近。这意味着logcosh损失函数可以在拥有MSE优点的同时也不会受到局外点的太多影响。它拥有Huber的所有优点,并且在每一个点都是二次可导的。
keras 接口:
logcosh(y_true, y_pred)