HBase应该知道的
1 摘要
本文是一篇HBase学习综述,将会介绍HBase的特点、对比其他数据存储技术、架构、存储、数据结构、使用、过滤器等。
关于Phoenix on HBase,即Sql化的HBase服务,可以参考Phoenix学习
未完成
2 HBase基础概念
2.1 HBase是什么
-
起源
HBase源于Google 2005年的论文Bigtable。由Powerset公司在2007年发布第一个版本,2008年成为Apache Hadoop子项目,2010年单独升级为Apache顶级项目。 -
设计目标
HBase的设计目标就是为了那些巨大的表,如数十亿行、数百万列。 -
一句话概括
HBase是一个开源的、分布式的、版本化、列式存储的非关系型数据库。 -
面向列
准确的说是面向列族。每行数据列可以不同。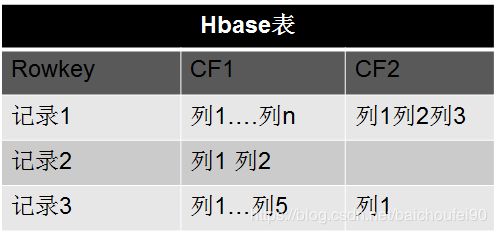
2.2 HBase相对于RDMBS能解决什么问题
| 扩展性 | 表设计 | 负载均衡 | failover | 事务 | 适用数据量 | |
|---|---|---|---|---|---|---|
| RDBMS | 差 | 灵活性较弱 | 差 | 同步实现 | 支持 | 万级 |
| HBase | 强 | 十亿级行,百万级列;动态列,每行列可不同。且引入列族和数据多版本概念。 | 强 | 各组件都支持HA | MVCC, Produce LOCK;行级事务 | 亿级 |
2.3 HBase特点
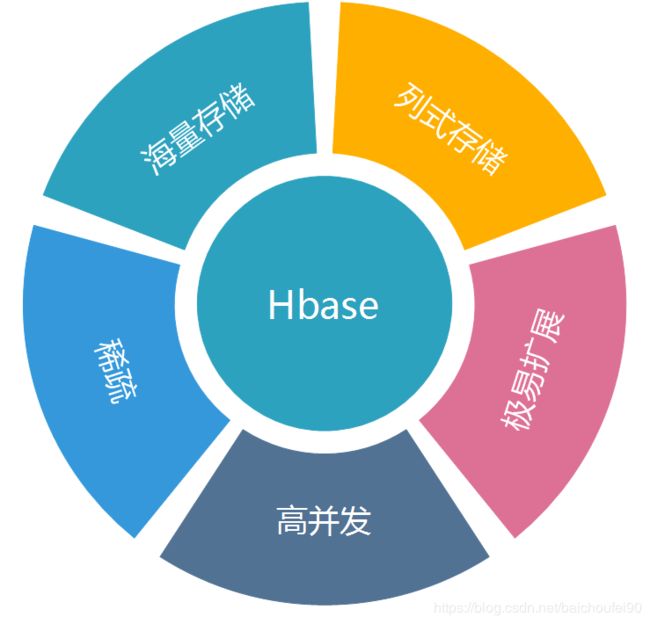
- HDFS支持的海量存储,链家PC存储PB级数据仍能有百毫秒内的响应速度。(扩展性十分好)
- 极易扩展(可添加很多RS节点进行处理能力扩展,也可添加多个HDFS DataNode进行存储能力扩展),表自动分片,且支持自动Failover
- 高效地、强一致性地读写海量数据,CP
- MapReduce可读写HBase
- JavaAPI, Thrift / REST API, Shell
- 依赖Blockcache和布隆过滤器提供实时查询
- 服务端侧的过滤器实现谓词下推,加速查询
- 可通过JMX监控HBase各指标
- 面向列,列式存储,且列可以按需动态增加
- 稀疏。空Cell不占空间
- 数据多版本
- 数据类型单一,都是字符串,无类型(要用类型可用Phoenix实现)
2.4 HBase与Hadoop
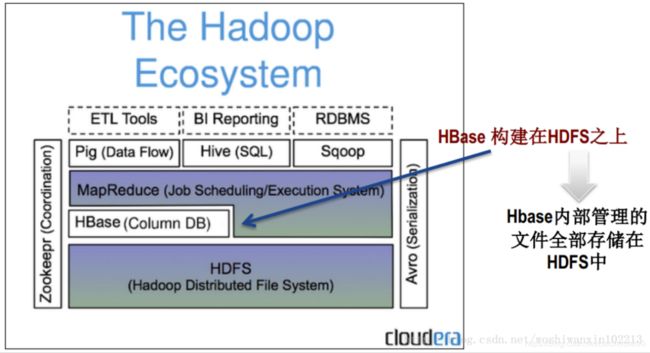
作为曾经Hadoop项目的子项目,HBase还是与Hadoop生态关系密切。HBase底层存储用了HDFS,并可直接用MapReduce操作HBase
2.5 HBase与CAP
2.5.1 CAP简介
CAP定理指出,分布式系统可以保持以下三个特征中的两个:
- Consistency,一致性
请求所有节点都看到相同的数据 - Availability,可用性
每个请求都能及时收到响应,无论成功还是失败。 - Partition tolerance,分区容忍
即使其他组件无法使用,系统也会继续运行。
2.5.2 HBase的取舍-CP
HBase选择的是一致性和分区容忍即CP。
这篇文章给出了为什么分区容忍重要的原因you-cant-sacrifice-partition-tolerance。
已经有测试证明 HBase面对网络分区情况时的正确性。
2.6 HBase使用场景
2.6.1 适用场景
- 持久化存储大量数据(TB、PB)
- 对扩展伸缩性有要求
- 需要良好的随机读写性能
- 简单的业务KV查询(不支持复杂的查询比如表关联等)
- 能够同时处理结构化和非结构化的数据
订单流水、交易记录、需要记录历史版本的数据等
2.6.2 不适用场景
- 几千、几百万那种还不如使用RDBMS
- 需要类型列(不过已经可以用Phoniex on HBase解决这个问题)
- 需要跨行事务,目前HBase只支持单行事务,需要跨行必须依赖第三方服务
- SQL查询(不过可以用Phoniex on HBase解决这个问题)
- 硬件太少,因为HBase依赖服务挺多,比如至少5个HDFS DataNode,1个HDFS NameNode(为了安全还需要个备节点),一个Zookeeper集群,然后还需要HBase自身的各节点
- 需要表间Join。HBase只适合Scan和Get,虽然Phoenix支持了SQL化使用HBase,但Join性能依然很差。如果非要用HBase做Join,只能再客户端代码做
2.7 行/列存储
2.7.1 简介
HBase是基于列存储的。本节对比下行列两种存储格式。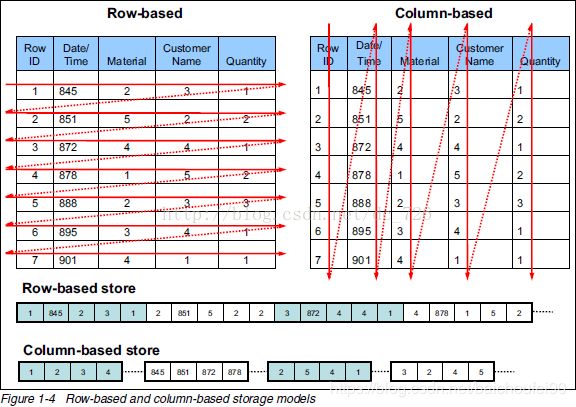
从上图可以看到,行列存储最大的不同就是表的组织方式不同。
2.7.2 数据压缩
列式存储,意味着该列数据往往类型相同,可以采用某种压缩算法进行统一压缩存储。
比如下面这个例子,用字典表的方式压缩存储字符串:
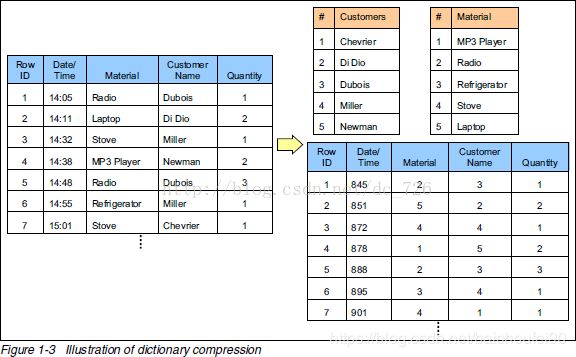
查询Customers列为Miller且Material列为Regrigerator的流程如下: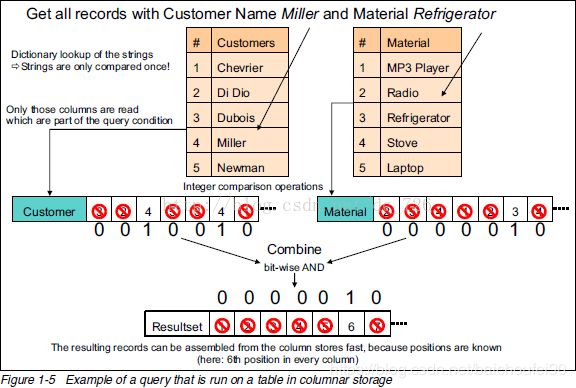
- 分别去两列的字典表找到对应的数字
- 将该数字回原表查询,得到行号组成的BitSet,即满足条件的行号位置的bit设为1,其余为0
- 将两个BitSet相与,得到最终结果BitSet
- 得到最终行号为6,去字典表拿出结果组装返回即可
2.7.3 行列存储对比
| 行 | 列 | |
|---|---|---|
| 优点 | 1.便于按行查询数据,OLTP往往是此场景 2.便于行级插入、删除、修改 3.易保证行级一致性 |
1.便于按列使用数据,如对列分组、排序、聚合等,OLAP很多是这样 2.列数据同类型,便于压缩 3.表设计灵活,易扩展列 |
| 缺点 | 1.当只需查询某几个列时,还是会读整行数据 2.扩展列代价往往较高 |
1.不便于按行使用数据 2.很难保证行级一致性 |
| 优化思想 | 读取过程尽量减少不需要的数据 | 提高读写效率 |
| 优化措施 | 1.设计表时尽量减少冗余列 2.内存中累积写入到阈值再批量写入 |
1.多线程方式并行读取不同列文件 2.行级一致性,可通过加入RDBMS中回滚机制、校验码等 3.内存中累积写入到阈值再批量写入 |
| 应用场景 | OLTP | OLAP |
3 HBase架构
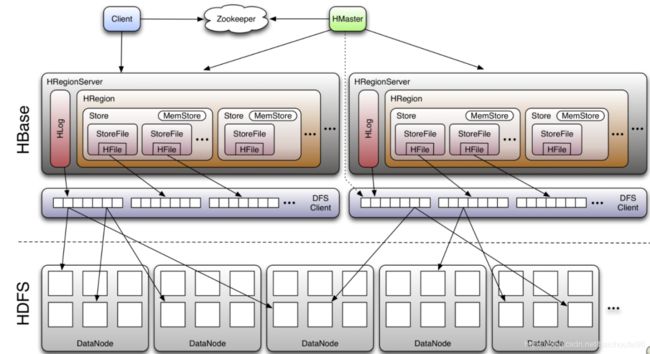
3.1 Client
Client有访问Hbase的接口,会去meta表查询目标region所在位置(此信息会放入缓存),并连接对应RegionServer进行数据读写。
当master rebalance region时,Client会重新进行查找。
3.2 Zookeeper
- HMaster和RegionSerer都注册到ZK上,使HMaster可感知RegionServer上下线。
- 选举,保证HMaster HA。
- 保存
.META.表所在RegionServer位置
3.3 HMaster
- 监控RegionServe状态,并为之分配Region,以维护整个集群的负载均衡
- 通过HMasterInterface接口维护集群的元数据信息,管理用户对table的增删改查操作
- Region Failover:发现失效的Region,就到正常的RegionServer上恢复该Region
- RegionSever Failover:由HMaster对其上的region进行迁移
3.4 HRegionServer
3.4.1 主要职责
- 处理用户读写请求,并和底层HDFS的交互。我们说RegionServer拥有某个region意思是这个region读写、flush之类的操作都是由当前regionserver管理的。如果该RegionServer本地没有HDFS DataNode 底层数据就要从其他DataNode节点远程读写。
- 负责Region变大以后的split
- 负责Storefile的合并工作
3.4.2 HRegionServer组件
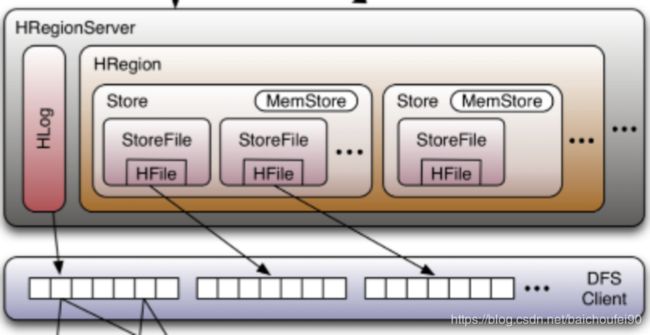
-
一个RegionServer上存在多个Region和一个HLog读写实例。
-
HLog的就是WAL(Write-Ahead-Log),相当于RDBMS中的redoLog,写数据时会先写一份到HLog。可以配置
MultiWAL,多Region时使用多个管道来并行写入多个WAL流。一个RS共用一个HLog的原因是减少磁盘IO开销,减少磁盘寻道时间。
-
Region属于某个表水平拆分的结果(初始一个Region),每个表的Region分部到多个RegionServer。
-
Region上按列族划分为多个Store
-
每个Store有一个MemStore,当有读写请求时先请求MemStore
-
每个Store又有多个StoreFile
-
HFiles是数据的实际存储格式,他是二进制文件。StoreFile对HFile进行了封装。HBase的数据在底层文件中时以KeyValue键值对的形式存储的,HBase没有数据类型,HFile中存储的是字节,这些字节按字典序排列。
-
BlockCache
3.5 HDFS
为HBase提供最终的底层数据存储服务,多副本保证高可用性 .
- HBase表的HDFS目录结构如下
/hbase
/data
/ (集群里的Namespaces)
/ (该集群的Tables)
/ (该table的Regions)
/ (该Region的列族)
/ (该列族的StoreFiles)
- HLog的HDFS目录结构如下
/hbase
/WALs
/ (RegionServers)
/ (WAL files for the RegionServer)
3.6 Region
3.6.1 概述
一个Region水平切分的示例:
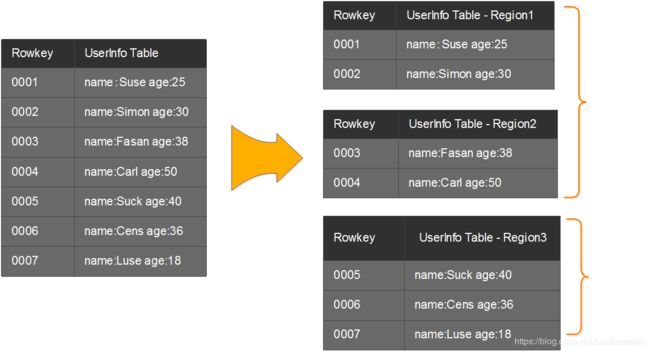
- 一个RegionServer上存在多个Region和一个Hlog实例。
- Region属于某个表水平拆分的结果(初始一个Region),每个表的Region分部到多个RegionServer。
- Region上按列族划分为多个Store
- 每个Store有一个MemStore,当有读写请求时先请求MemStore。MemStore内部是根据
RowKey, Column, Version排序
- 每个Store又有多个StoreFile
3.6.2 Region分配
- HMaster使用
AssignmentManager,他会通过.META.表检测Region分配的合法性,当发现不合法(如RegionServer挂掉)时,调用LoadBalancerFactory来重分配Region到其他RS。
- 分配完成并被RS打开后,需要更新
.META.表。
3.6.3 Region Merge(合并)
可参考:
- HBase Compaction的前生今世-身世之旅
3.6.3.1 手动合并
注意,这里说的是Region级别的合并,一旦手动触发,HBase会不做很多自动化检查,直接执行合并。
- 手动合并目的
通常是为了执行major compaction,一般有三种目的:
- 线上业务可能因为自动
major compaction影响读写性能,因此选择低峰期手动触发;
- 用户在执行完
alter操作之后希望立刻生效;
- 管理员发现硬盘容量不够,手动触发major compaction删除大量过期数据;
该过程对Client来说是异步的,是Master和RegionServer共同参与,步骤如下:
- Client通过RPC发送请求给Master
- Master将regions移动到目标RS
- Master发送合并请求给此RS
- RS运行合并
3.6.3.2 自动合并
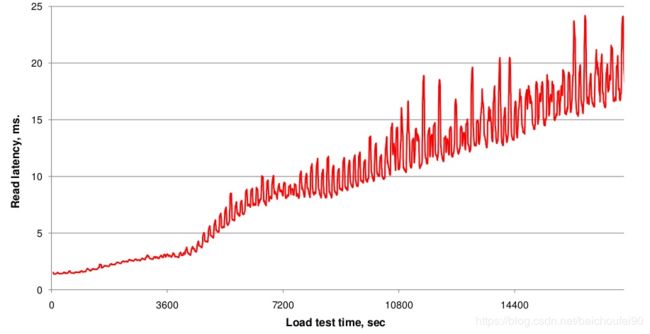
这里指的是StoreFile级别的合并。
-
原因
当MemStore不断flush到磁盘,StoreFile会越来越多,从而导致查询时IO次数增加,效率降低。如下图
-
时机
合并根据许多因素,可能有益于形同表现也有可能是负面影响。
- Memstore Flush
flush后会检查该Store的StoreFile数量是否超过阈值,超过就将该Region下的所有Store的StoreFile进行Compact。还需要注意的是,Flush后如果该Store的StoreFile数量如果超过了hbase.hstore.blockingStoreFiles,则会阻塞该Region的更新写入操作,直到有Compact发生减少了StoreFile数量或等待until hbase.hstore.blockingWaitTime超时,然后继续正常Flush。
- 后台线程周期性检查
除了判断StoreFile数是否超限还要检查Store中最早的StoreFile更新时间是否早于某个值,这样的目的是为了删除过期数据。
- 手动触发
比如避免业务高峰期MajorCompact影响业务、使用Alter命令后需要立刻生效、硬盘不够需要紧急删除大量过期、无效数据。
-
Compact过程
HBase Compact过程,就是RegionServer定期将多个小StoreFile合并为大StoreFile,具体如下:
- 筛选出需要合并的HFile list。
- HRegion创建StoreFileScannaer,来将待合并文件中的所有KeyValue读出再按从小到大排序后写入位于
./tmp目录下的临时文件。此时就会忽略TTL过期数据。
- 将该临时文件移动至对应Region的数据目录。
- 将Compact输入(合并前的StoreFile)/输出(合并后的StoreFile)文件路径封装为KeyValue后写入WAL,并打上Compact标记,然后强制sync刷入磁盘。
- 最后将合并前的StoreFile删除即可。这也就是LSM小树合并为大树思想。
-
Compact影响
-
读放大
合并操作的目的是增加读的性能,否则搜索时要读取多个文件,当然合并过程会有短时间的IO消耗所以影响读响应时间造成所谓读放大,但可以是的后续查询延迟降低,如下图:
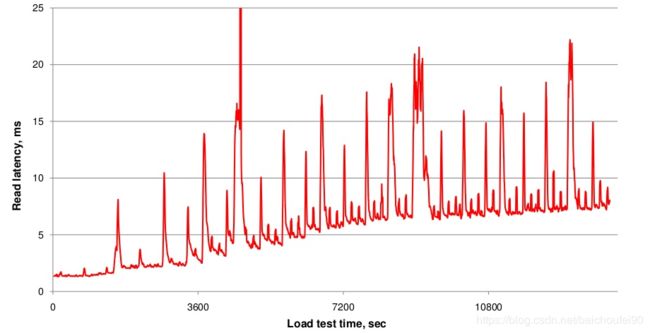
-
写放大
如果在合并时不限制写请求,当HFile生成速度大于合并速度时可能使得HFile越来越多,读性能不断下降,所以必须对此时写请求进行限制。具体来说,如果任何一个Region的Store中存在超过hbase.hstore.blockingStoreFiles的StoreFiles,则会阻塞此Region的更新,直到Compact使得文件数低于该值或阻塞时间超出hbase.hstore.blockingWaitTime。这种阻塞行为可在RS的日志中查看到。
-
影响小结
Compact会使得数据读取延迟一直比较平稳,但付出的代价是大量的读延迟毛刺和一定的写阻塞。
自动合并分为Minor Compact和Major Compact:
Minor Compact
-
合并概述:
仅会挑选Store内少量小的、临近的StoreFile进行合并,最理想是选到IO负载高但size较小的文件,合并后就能读取较少的文件。Minor Compact结果是更少、更大的StoreFile。
Minor Compact会合并TTL过期的数据:合并时会删除这些TTL过期数据,不再写入合并后的StoreFile。(注意TTL删除的数据无墓碑)
Minor Compact一般速度很快,对业务的影响也比较小,就是使用短时间的IO消耗以及带宽消耗换取后续查询的低延迟。
-
合并过程
- 分别读取出待合并的StoreFile文件的KeyValues,并顺序地写入到位于./tmp目录下的临时文件中
- 将临时文件移动到对应的Region目录中
- 将合并前的待合并文件路径和输出的已合并文件路径封装成KeyValues写入WAL日志,并打上compaction标记,最后强制自行sync
- 将对应region数据目录下的合并的输入文件全部删除,合并完成
-
输出
每个Store合并完成的输出是少量较大的StoreFile。
Major Compact
- 合并过程
将一个Store下的所有StoreFile为一个StoreFile,此时会删除那些无效的数据,耗费大量资源,持续时间较长,可能对服务能力有较大影响。一般来说线上业务会关闭自动Major Compact,而是选择在业务低峰期手动来触发:
- 有更新时,老的数据就无效了,最新的那个
就被保留
- 被删除的数据,将墓碑
和旧的都删掉
- 通过maxVersion制定了最大版本的数据,超出的旧版本数据会在合并时被清理掉不再写入合并后的StoreFile
- 有Split的父Region的数据会迁移到拆分后的子Region
- 输出
每个Store合并完成的输出是一个较大的StoreFile。
3.6.3.3 合并策略
3.6.3.3.1 关于Major Compact
默认Major Compact 7天执行一次,可能会导致异常开销,影响系统表现,所以可以进行手动调优。
3.6.3.3.2 ExploringCompactionPolicy
当前版本(1.2.0版)采用的合并策略为ExploringCompactionPolicy,挑选最佳的StoreFiles集合以使用最少量的工作进行压缩,可以减少合并带来的消耗。使用ExploringCompactionPolicy,主要Major Compact的频率要低得多,因为Minor Compaction效率更高。
流程如下:
-
列出目标Store中所有现有的StoreFiles,待过滤此列表以提出将被选择用于Compact的HFile子集。
-
如果这是手动执行的Compact,则尝试执行手动请求的压缩类型。
请注意,即使用户请求Major Compact,也可能无法执行。原因可能是列族中某些StoreFiles不可Compact,或者因为列族中的StoreFiles太多。
-
某些StoreFiles会被自动排除掉:
- 大于
hbase.hstore.compaction.max.size的StoreFile
- 使用
hbase.mapreduce.hfileoutputformat.compaction.exclude排除的批量加载操作的StoreFile
-
遍历步骤1中的列表,并列出所有可合并的StoreFiles Set,将他们合并成一个StoreFile。这里的Set是指那些列表中的按hbase.hstore.compaction.min大小连续分组的StoreFile。对于每个备选Set执行一些检查来确定最佳合并Set:
- 排除那些StoreFile数小于
hbase.hstore.compaction.min或大于hbase.hstore.compaction.max的Set
- 比较该Set和list中已检查过的最小的Set,如果本Set更小就作为
算法卡住时的fall back。
- 依次对这组Set中的StoreFile进行基于大小的检查:
- 排除大小大于
hbase.hstore.compaction.max.size的StorFile
- 如果大小大于或等于
hbase.hstore.compaction.min.size,则根据基于文件的比率进行健全性检查,以查看它是否太大而排除掉。 如果符合以下条件,则完整性检查成功:
- 此Set中只有一个StoreFile
- 对于每个StoreFile的文件大小,需要小于该Set中的其他所有HFile的总大小乘以
hbase.hstore.compaction.ratio(如果配置非高峰时间且检查时恰好是非高峰时间,则为hbase.hstore.compaction.ratio.offpeak)的结果。(比如FileX = 5MB, FileY = 2MB, FileZ = 3MB,此时5 <= 1.2 x (2 + 3)=6,所以FileX筛选通过;FileX大小大于6MB就不通过Compact筛选。)
-
如果该Set通过筛选,请将其与先前选择的最佳Compact Set进行比较。如果更好就替换。
-
当处理完整个潜在CompactFileList后,执行我们已经找到的最佳Compact。
-
如果没有成功选择出Compact Set,但存在多个StoreFiles,则认为此事属于算法卡住,就执行步骤4.2中找到的最小Set进行Compact。
RatioBasedCompactionPolicy想找到第一个”可行解“即可,而ExploringCompactionPolicy却在尽可能的去寻求一种自定义评价标准中的”最优解“。
3.6.3.3.3 RatioBasedCompactionPolicy
HBase 0.96.x之前使用RatioBasedCompactionPolicy,从老到新扫描潜在可选CompactStoreFile,选择那些没有在CompactQueue且比比正在Compact的StoreFile更新的StoreFile组成List且按SequenceId排序。此时如果算法卡住,则强制执行开销巨大的Major Compact。作为对比,更优的ExploringCompactionPolicy则是Minor Compact最小Set。
接下来的步骤和ExploringCompactionPolicy基本相同。
但如果剩余未遍历的待合并文件list数量少于hbase.hstore.compaction.min,则放弃Minor Compact。一旦找到满足条件的第一个StoreFile Set就停止扫描并开始Compact。Minor Compact的peak规则如下:
- 此StoreFile大小 < 其他StoreFile总大小 *
hbase.hstore.compaction.ratio。也可使用hbase.hstore.compaction.ratio.offpeak, hbase.offpeak.start.hourhbase.offpeak.end.hour配置非高峰期选项。
最后,如果检查到最近一次Major Compact是很久以前的并且目前需要合并多个StoreFile,则会运行一个Major Compact,即使本应是Minor Compact。
3.6.3.3.4 DateTieredCompaction
以上合并策略选取文件未考虑最近写入数据往往也更容易被读取这一特点,所以还是有缺陷。大量合并那些读的很少的老文件是没有必要的,因为他们合并后也不会对读性能有很多提升。
DateTieredCompaction(日期分层合并)是一种日期感知的StoreFile合并策略,将StoreFile按日期分为多个不同分区,并加入时间窗口概念,有利于的时序数据的time-range scan。
性能提升:
- Compact提升:
具体来说,这样可使得新老数据在不同的Date分区,Compact也发生在不同的Date分区。
- 老的数据很少读不需要频繁Compact,且特别老的数据永不再合并。
- 新的数据读频繁,合并后可减少扫描的文件数,减少了Compact开销。
- 读提升
读数据也可直接从指定的Date分区读取,在按时间读取数据时候的效率提升不少,不需再遍历所有文件。
适合场景:
- 有限时间范围的数据读取,尤其是对最近数据的scam
- 比如微信朋友圈或者微博,新发的最有可能被别人看,但很长时间以前发的没人或很少有人阅读。这类HFile就可以分为旧和新两类数据,将较新的和新的HFile合并,旧的一起合并。
不适合的场景:
- 无界的时间范围的随机Get
- 频繁删除和更新
- 由于频繁的乱序数据写入会导致长尾,尤其是具有未来时间戳的写入
- 频繁的批量加载,且时间范围有很大重叠
性能提升:
- DateTieredCompaction性能测试表明,time-range scan的性能在有限的时间范围内有很大改善,特别是对最近数据的scan。
要为表或列族启用DateTieredCompaction:
- 需将
hbase.hstore.engine.class设置为org.apache.hadoop.hbase.regionserver.DateTieredStoreEngine。
- 需将
hbase.hstore.blockingStoreFiles设置为较大数字,例如60,而不是默认值12)。
- 需将
hbase.hstore.compaction.max设置为与hbase.hstore.blockingStoreFiles相同的值,避免Major Compat时发生写入阻塞。
DateTieredCompaction主要参数如下:
参数
含义
默认值
hbase.hstore.compaction.date.tiered.max.storefile.age.millis
Storefile的最大Timestamp值比该参数还小的永不会被合并
Long.MAX_VALUE
hbase.hstore.compaction.date.tiered.base.window.millis
毫秒级的基础时间窗口大小,后面会越来越大
6小时
hbase.hstore.compaction.date.tiered.windows.per.tier
每个层级的增加的窗口倍数,比如为2,则窗口大小变动为6小时->12小时->24小时
4
hbase.hstore.compaction.date.tiered.incoming.window.min
在incoming窗口中Compact的最小文件数。 将其设置为窗口中预期的文件数,以避免浪费资源进行极少文件Compact
6
hbase.hstore.compaction.date.tiered.window.policy.class
在同一时间窗口内挑选Storefile的策略,该策略不适用于incoming窗口。
ExploringCompactionPolicy
hbase.regionserver.throughput.controller
推荐将Compact节流阀设为org.apache.hadoop.hbase.regionserver.compactions.PressureAwareCompactionThroughputController,因为分层Compact中所有急群众的RS会同时提升窗口到高层级
-
下面是基础窗口为1小时,窗口成长倍数为2,最小合并文件数为3的一个例子:
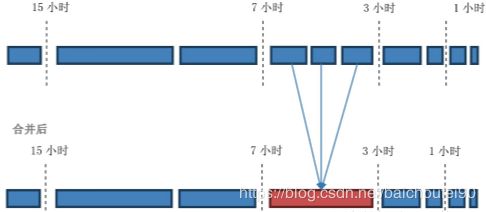
可以看到 [0-1)->[1->3)->[3-7) 三个窗口依次寻找,只有[3-7)这个窗口有3个文件满足了最小合并文件数,所以会被Compact。
如果HFile跨窗口,则会被计入时间更老的窗口。
3.6.3.3.5 StripeCompactionPolicy
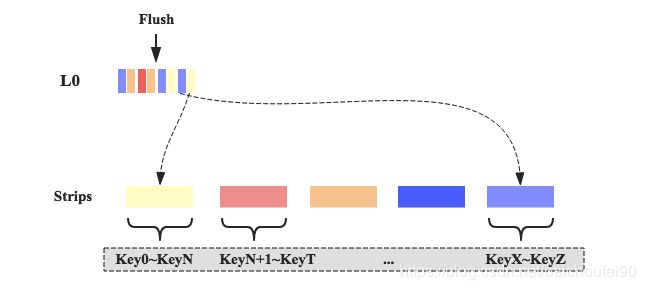
StripeCompactionPolicy使用分层策略,分为L0和L1层:
-
MemStore数据Flush后的HFile属于L0,当L0的文件数达到可配的阈值后触发写入,即将L0数据读取后写入L1。
-
L1的数据按ROWKEY范围进行划分,划分结果是多个户不重叠的Stripe,思想可类比将Region拆分多个子Region。
从L0写入L1的KeyValue数据就是根据Key来定位到具体的某个Stripe。
StripeCompactionPolicy提升如下:
- Compact提升
注意,Stripe可类比子Region,所以Stripe内部也是会执行Minor/Major Compaction。但是因为做了拆分,所以相对来说说Compact操作消耗较小。具体来说,原来Major Compact需要合并Store下所有StoreFile,而现在只需要合并某Stripe内部所有StoreFile。
- 读取提升
数据读取的时候,直接根据Key来查找Stripe并查找即可
- 读写稳定性提升
StripeCompactionPolicy的适用场景:
- Region巨大。
小的Region使用Stripe切分反而带来额外不必要开销。一般考虑的Region大小阈值为2GB。
- RowKey需要具有统一格式,才能进行Stripe切分。比如时间格式Key数据,就可以让老的数据不合并,只合并接收新数据的那些Stripe。
3.6.3.4 CompactThreadPool
HBase CompactSplitThead线程负责Compact和Split,内部又分为Split线程池和用于Compact的largeCompactions、smallCompactions线程池。分入哪个线程池的判断依据:
- 待compact的文件总大小大于
hbase.regionserver.thread.compaction.throttle,则用largeCompactions。该阈值默认值为2 x hbase.hstore.compaction.max(默认10) x hbase.hregion.memstore.flush.size(默认128MB)
- 否则使用smallCompactions
- 这两个Compact线程池默认单线程,可通过
hbase.regionserver.thread.compaction.large和hbase.regionserver.thread.compaction.small修改。
3.6.3.5 合并/scan并发问题
当scan查询时遇到合并正在进行,解决此问题方案点这里
3.6.3.5 合并限流
Compact或多或少会影响HBase其他功能的表现,所以HBase在1.5之后有对Compact进行限流,2.x后默认会自动限流Compact,在压力大时降低合并吞吐量,压力小时增加。需要注意的是Compact限流是RegionServer级别,而非Compact级别。
具体来说:
- HBase根据系统外部压力(即相当对于最大文件数阈值的当前StoreFile数量,越多则压力越高),调整允许的合并时的吞吐量阈值(每秒写入的字节范围),可在给定的上下界之间变动(Compact实际会工作在吞吐量为
lower + (higer – lower) * pressureRatio的限制下,其中ratio是一个取值范围在(0,1),它由当前store中待参与Compation的Hfile数量动态决定。文件数量越多,ratio越小,反之越大)。
- 如果HFile数量达到了
hbase.hstore.blockingStoreFiles限制则阻塞MemStore Flush,直到Compact使得文件数低于该值或阻塞时间超出hbase.hstore.blockingWaitTime。
- 如果MemStore Flush达到
hbase.hregion.memstore.block.multiplier 乘以 hbase.hregion.memstore.flush.size字节时,会阻塞写入,主要是为了防止在update高峰期间MemStore大小失控,造成其flush的文件需要很长时间来compact或split,甚至造成OOM服务直接down掉。内存足够大时,可调大该值。
- 关于pressureRatio
上文提到的pressureRatio默认为flushPressure,throughput.controller设为PressureAwareCompactionThroughputController时为compactionPressure。
- compactionPressure=(当前HFile数-minFilesToCompact)/(blockingStoreFiles-minFilesToCompact),其中
minFilesToCompact为hbase.hstore.compaction.min。所以该值越大说明堆积的HFile越多,越可能达到阈值导致写入阻塞,需要加快合并,所以吞吐量限制阈值会变高。当pressureRatio大于1时,即当前HFile数大于blockingStoreFiles,发生写入阻塞,此时会直接不再限制合并吞吐量,疯狂Compact。如果当前HFile数小于minFilesToCompact则不会发生合并。
- flushPressure= globalMemstoreSize(当前MemStore总大小) / memstoreLowerLimitSize(hbase.regionserver.global.memstore.lowerLimit,RS级别MemStore flush下界)
即MemStore总大小越大或memstoreLowerLimitSize越小则flush限制越宽松,发生flush后的HFile数越多,更可能造成flush阻塞。
主要配置如下:
参数
释义
默认值
hbase.hstore.compaction.throughput.lower.bound
吞吐量下界,默认50MB/s
52428800
hbase.hstore.compaction.throughput.higher.bound
吞吐量上界,默认100MB/s
104857600
hbase.regionserver.throughput.controller
RS吞吐量控制器,若想无限制设为org.apache.hadoop.hbase.regionserver.throttle.NoLimitThroughputController;控制合并相关指标org.apache.hadoop.hbase.regionserver.compactions.PressureAwareCompactionThroughputController;
控制刷写相关指标:PressureAwareFlushThroughputController
hbase.hstore.blockingStoreFiles
如果任何一个Region的Store中存在超过hbase.hstore.blockingStoreFiles的StoreFiles,则会阻塞此Region的MemStore flush,直到Compact使得文件数低于该值或阻塞时间超出hbase.hstore.blockingWaitTime。这种阻塞行为可在RS的日志中查看到。
16
hbase.hstore.compaction.ratio
对于MinorCompac,此比率用于确定大于hbase.hstore.compaction.min.size的StoreFile是否有资格进行Compact,目的是限制大型StoreFile Compact。
1.2F
hbase.offpeak.start.hour
非高峰期的起始小时,[0-23]
-1(禁用)
hbase.offpeak.end.hour
非高峰期的终止小时,[0-23]
-1(禁用)
hbase.hstore.compaction.ratio.offpeak
非高峰时段使用的Compact ratio,默认很激进的策略,用来决定非高峰期时段内大型StoreFile被涵盖在Compact内的策略。 表示为浮点小数。 这允许在设定的时间段内更积极(或更低级,如果您将其设置为低于hbase.hstore.compaction.ratio)的Compact。 如果禁用非高峰时则忽略本参数。 本参数与hbase.hstore.compaction.ratio的工作方式相同。具体可以参考ExploringCompactionPolicy
5.0F
3.6.4 Region Split(拆分)
可参考Region切分细节
默认情况下,HBase表初始创建时只有一个Region,放在一个RegionServer上。HBase有自动Split,也可以pre-split或手动触发split。
3.6.4.1 自动Split策略
本段转自Hbase 技术细节笔记(下)
用到的参数主要是hbase.hregion.max.filesize,即HFile大小超过此值就Split。
HBase Region的拆分策略有比较多,比如除了3种默认过的策略,还有DelimitedKeyPrefixRegionSplitPolicy、KeyPrefixRegionSplitPolicy、DisableSplitPolicy等策略,这里只介绍3种默认的策略。分别是ConstantSizeRegionSplitPolicy策略、IncreasingToUpperBoundRegionSplitPolicy策略和SteppingSplitPolicy策略。
-
ConstantSizeRegionSplitPolicy
是0.94版本之前的默认拆分策略,这个策略的拆分规则是:当region大小达到hbase.hregion.max.filesize(默认10G)后拆分。
这种拆分策略对于小表不太友好,按照默认的设置,如果1个表的Hfile小于10G就一直不会拆分。注意10G是压缩后的大小,如果使用了压缩的话。如果1个表一直不拆分,访问量小也不会有问题,但是如果这个表访问量比较大的话,就比较容易出现性能问题。这个时候只能手工进行拆分。还是很不方便。
-
IncreasingToUpperBoundRegionSplitPolicy
是Hbase的0.94~2.0版本默认的拆分策略,这个策略相较于ConstantSizeRegionSplitPolicy策略做了一些优化,该策略的算法为:min(r^2*flushSize,maxFileSize ),最大为maxFileSize 。
从这个算是我们可以得出flushsize为128M、maxFileSize为10G的情况下,可以计算出Region的分裂情况如下:
第一次拆分大小为:min(10G,11128M)=128M
第二次拆分大小为:min(10G,33128M)=1152M
第三次拆分大小为:min(10G,55128M)=3200M
第四次拆分大小为:min(10G,77128M)=6272M
第五次拆分大小为:min(10G,99128M)=10G
第六次拆分大小为:min(10G,1111128M)=10G
从上面的计算我们可以看到这种策略能够自适应大表和小表,但是这种策略会导致小表产生比较多的小region,对于小表还是不是很完美。
-
SteppingSplitPolicy
SteppingSplitPolicy是在Hbase 2.0版本后的默认策略,拆分规则为:
if region=1
then: flush size * 2
else: MaxRegionFileSize
还是以flushsize为128M、maxFileSize为10场景为列,计算出Region的分裂情况如下:
第一次拆分大小为:2*128M=256M
第二次拆分大小为:10G
从上面的计算我们可以看出,这种策略兼顾了ConstantSizeRegionSplitPolicy策略和IncreasingToUpperBoundRegionSplitPolicy策略,对于小表也有比较好的适配。
一般情况下使用默认切分策略即可,也可以在cf级别设置region切分策略,命令为:
create ’table’, {NAME => ‘cf’, SPLIT_POLICY => ‘org.apache.hadoop.hbase.regionserver. ConstantSizeRegionSplitPolicy'}
3.6.4.2 自动Split
可参考
- Hadoop之HBase
注意:Split过程是RegionServer进行的,没有Master参与。
- 当Region大小超过一定阈值后,RS会把该Region拆分为两个(Split),
- 将原Region做离线操作
- 把新生成的Region放入
.META.表。
- 打开新Region,以使得可访问
- 通知Master该次Split,可按需用自动平衡等机制迁移子Region到其他RegionServer。
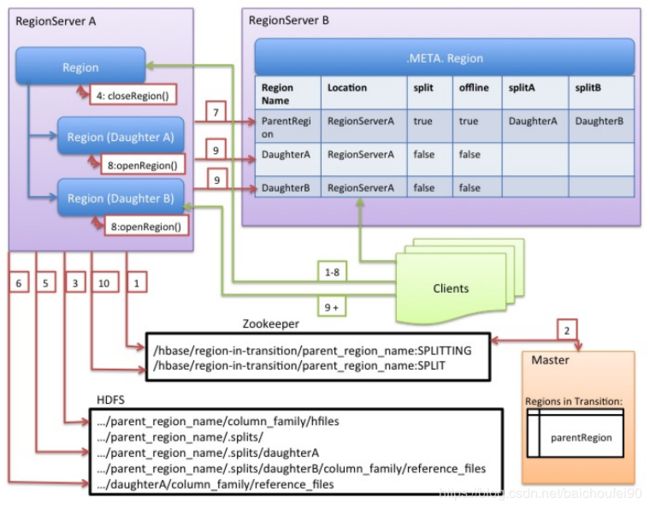
上图中,绿色箭头为客户端操作;红色箭头为Master和RegionServer操作:
-
RegionServer决定拆分Region,并准备拆分。此时,Split事务已经开始。RegionServer在表上获取共享读锁,以防止在他人在拆分过程中修改表的schema;然后在ZK的/hbase/region-in-transition/region-name下创建一个znode,并将该节点状态设置为SPLITTING。
-
Master在/hbase/region-in-transition设置了Watcher,所以会感知到这个znode变更,从而得知该split事件,在Master页面RIT模块可以看到region执行split的状态信息。
-
RegionServer在HDFS的/hbase/region-in-transition/region-name目录下创建一个名为.splits的子目录。
-
RegionServer关闭该待split的Region,并在其本地数据结构中将该Region标记为离线状态。被分裂的Region现在处于离线状态。此时,如果客户端请求该Region将抛出NotServingRegionException,客户端将自动重试。
-
RegionServer在父Region.splits目录下为子Region A和B创建目录和必要的数据结构。然后它将拆分StoreFiles,在子Region目录中为每个父Region的StoreFile创建两个指针reference文件来指向父Region的文件。
reference文件名的前半部分是父Region对应的HFile文件名,.号后的部分是父Region名称。
文件内容主要有两部分构成:
- 切分点splitkey
- boolean类型的变量(true或者false),true表示该reference文件引用的是父文件的上半部分(top),而false表示引用的是下半部分 (bottom)。
-
RegionServer为子Region们在HDFS中创建实际的Region目录,并移动每个子Region的指针文件。
-
RegionServer向.META表发送Put请求,将父Region设置为离线,并添加子Region的信息(此时客户端不可见)。在.META表更新即将父Region Offline列设为true,Region拆分将由Master推进。

如果在 RPC 成功之前 region server 就失败了,master和下次打开parent region的region server 会清除关于这次split的脏状态。但是当RPC返回结果给到parent region ,即.META.成功更新之后,region split的流程还会继续进行下去。相当于是个补偿机制,下次在打开这个parent region的时候会进行相应的清理操作。
-
RegionServer并行打开子Region A和B.
-
RegionServer将子Region A和B的信息添加到.META表,具体来说在.META表更新即将子Region Offline列设为false。此时,这些子Region现在处于在线状态。在此之后,客户端可以发现新Region并向他们发出请求了。客户端会缓存.META到本地,但当他们向RegionServer或.META表发出请求时,原先的ParentRegion的缓存将失效,此时将从.META获取新Region信息。
-
RegionServer将ZooKeeper中的znode/hbase/region-in-transition/region-name更新为状态SPLIT,Master可以感知到该事件。如有必要,平衡器可以自由地将子Region重新分配给其他RegionServer。Split拆分事务现已完成。
-
拆分完成后,.META和HDFS仍将包含对父Region的引用。当子Region进行Major Compact,读取父Regionx相应数据进行数据文件重写时,才删除这些引用。当检查线程发现SPLIT=TRUE的父Region对应的子Region已经没有了索引文件时,就删除父Region文件。Master的GC任务会定期检查子Region是否仍然引用父Region的文件。如果不是,则将删除父Region。
也就是说,Region自动Split并不会有数据迁移,而只是在子目录创建了到父Region的引用。而当Major Compact时才会进行数据迁移,在此之前查询子Region数据流程如下:
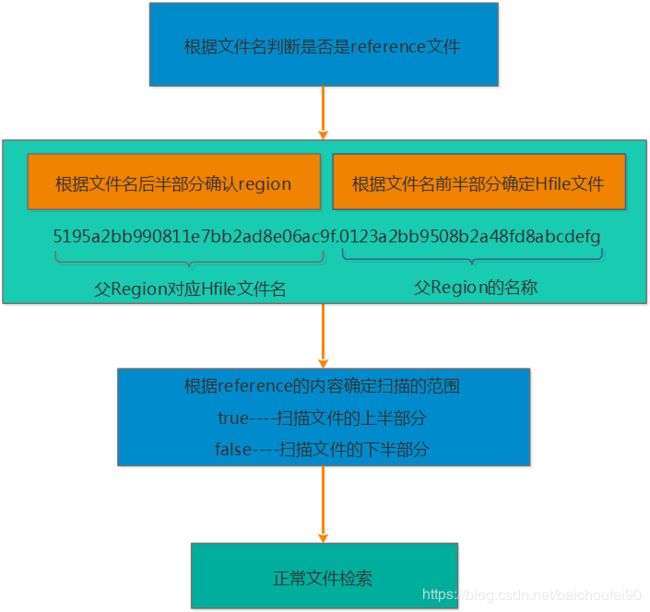
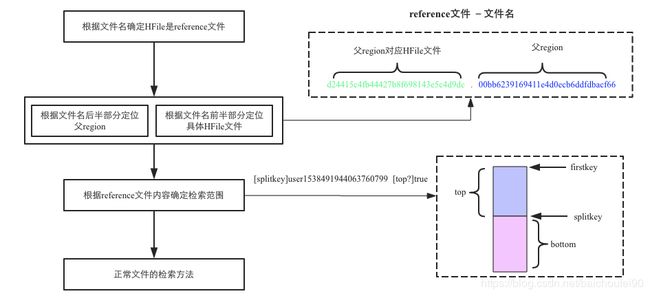
- 关于rollback:
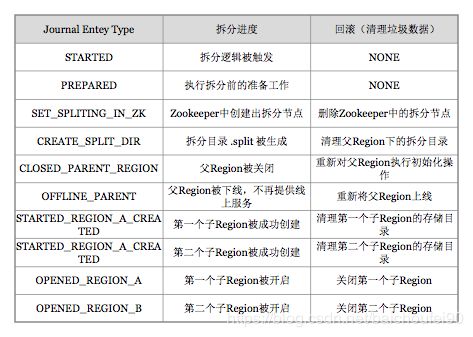
如果上述execute阶段出现异常,则将执行rollback操作,根据当前进展到哪个子阶段来清理对应的垃圾数据,代码中使用 JournalEntryType 来表征各阶段:
- 关于RegionSplit的事务性
在HBase2.0之后,实现了新的分布式事务框架Procedure V2(HBASE-12439),将会使用HLog存储这种单机事务(DDL、Split、Move等操作)的中间状态,可保证在事务执行过程中参与者发生了宕机依然可以使用HLog作为协调者对事务进行回滚操作或者重试提交
- 关于中间状态RIT和HBCK
可参考HBase HBCK2
3.6.4.3 pre-split预分区
在以下情况可以采用预分区(预Split)方式提高效率:
-
rowkey按时间递增(或类似算法),导致最近的数据全部读写请求都累积到最新的Region中,造成数据热点。
-
扩容多个RS节点后,可以手动拆分Region,以均衡负载
-
在BulkLoad大批数据前,可提前拆分Region以避免后期因频繁拆分造成的负载
-
为避免数据rowkey分布预测不准确造成的Region数据热点问题,最好的办法就是首先预测split的切分点做pre-splitting,以后都让auto-split来处理未来的负载均衡。
-
官方建议提前为预分区表在每个RegionServer创建一个Region。如果过多可能会造成很多表拥有大量小Region,从而造成系统崩溃。
-
注意合理分区方式
比如采用Admin.createTable(byte[] startKey, byte[] endKey, 10)构建的"0000000000000000" 到 "ffffffffffffffff"的预分区如下:
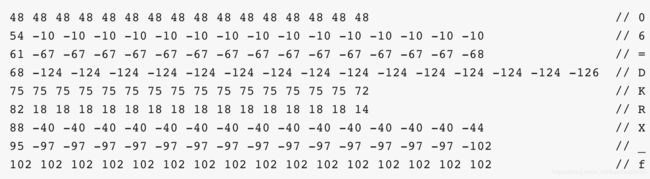
这种分区方式就会因为数据的rowkey范围是[0-9]和[a-f]从而使得仅有1,2,10号Region有数据,而其他Region无数据。
-
例子
# 创建了t1表的f列族,有4个预分区
create 'test_0807_1','cf1',SPLITS => ['10','20','30']
# 指定切分点建预分区表
create 'test_0807_2','cf1',SPLITS => ['\x10\x00', '\x20\x00', '\x30\x00', '\x40\x00']
# 建表,使用随机字节数组来进行预分4个Region
create 'test_0807_3','cf1', { NUMREGIONS => 4 , SPLITALGO => 'UniformSplit' }
# 建表,假设RowKey都是十六进制字符串来进行拆分,预分5个Region
create 'test_0807_4','cf1', { NUMREGIONS => 5, SPLITALGO => 'HexStringSplit' }
3.6.4.4 pre-split算法
一般来说,手动拆分是弥补rowkey设计的不足。我们拆分region的方式必须依赖数据的特征:
-
字母/数字类rowkey
可按范围划分。比如A-Z的26个字母开头的rowkey,可按[A, D]…[U,Z]这样的方式水平拆分Region。
-
自定义算法
HBase中的RegionSplitter工具可根据特点,传入算法、Region数、列族等,自定义拆分:
- HexStringSplit
假设RowKey都是十六进制字符串来进行拆分。
只需传入要拆分的Region数量,会将数据从00000000到FFFFFFFF之间的数据长度按照N等分,并算出每一分段的startKey和endKey来作为拆分点。
- UniformSplit
假设RowKey都是随机字节数组来进行拆分。与HexStringSplit不同的是,起始结束不是String而是byte[]。
- DecimalStringSplit
假设RowKey都是00000000到99999999范围内的十进制字符串
- 可使用SplitAlgorithm开发自定义拆分算法
3.6.4.5 手动强制split
HBase 允许客户端强制执行split,在hbase shell中执行以下命令:
//其中forced_table 为要split的table , ‘b’ 为split 点
split 'forced_table', 'b'
更多内容可以阅读这篇文章Apache HBase Region Splitting and Merging
3.6.5 Region状态
HBase的HMaster负责为每个Region维护了状态并存在META表,持久化到Zookeeper。
- OFFLINE: Region离线且未打开
- OPENING: Region正在打开过程中
- OPEN: Region已经打开,且RegionServer已经通知了Master
- FAILED_OPEN: RegionServer打开该Region失败
- CLOSING: Region正在被关闭过程中
- CLOSED: Region已经关闭,且RegionServer已经通知了Master
- FAILED_CLOSE: RegionServer关闭该Region失败
- SPLITTING: RegionServer通知了Master该Region正在切分(Split)
- SPLIT: RegionServer通知了Master该Region已经结束切分(Split)
- SPLITTING_NEW: 该Region是由正在进行的切分(Split)创建
- MERGING: RegionServer通知了Master该Region和另一个Region正在被合并
- MERGED: RegionServer通知了Master该Region已经被合并完成
- MERGING_NEW: 该Region正在被两个Region的合并所创建
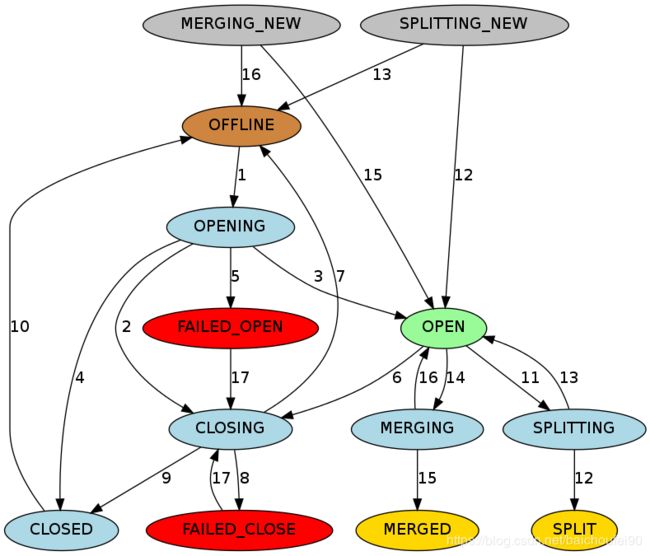
上图颜色含义如下:
- 棕色:离线状态。是一个特殊的瞬间状态。
- 绿色:在线状态,此时Region可以正常提供服务接受请求
- 浅蓝色:瞬态
- 红色:失败状态,需要引起运维人员会系统注意,手动干预
- 黄色:Region切分/合并后的引起的终止状态
- 灰色:由切分/合并而来的Region的初始状态
具体状态转移说明如下:
-
OFFLINE->OPENING
Master将Region从OFFLINE状态移动到OPENING状态,并尝试将该Region分配给RegionServer。 Master会重试发送请求直到响应通过或重试次数达到阈值。RegionServer收到该请求后开始打开该Region。
-
OPENING->CLOSING
如果Master没有重试,且之前的请求超时,就认为失败,然后将该Region设为CLOSING并试图关闭它。即使RegionServer已经开始打开该区域也会这么做。如果Master没有重试,且之前的请求超时,就认为失败,然后将该Region设为CLOSING并试图关闭它。即使RegionServer已经开始打开该区域也会这么做。
-
OPENING->OPEN
在RegionServer打开该Region后,通知Master直到Master将该Region状态变更为OPEN状态并通知RegionServer。
-
OPENING->CLOSED
如果RegionServer无法打开该Region,则会通知Master将Region转移为CLOSED,并尝试在其他的RegionServer上打开该Region。
-
OPENING->FAILED_OPEN
如果Master无法在任何RegionServer中打开该Region,则会将该Region设为到FAILED_OPEN。HBase shell进行手动干预或服务器停止之前不会再有其他操作。
-
OPEN->CLOSING
Master将Region从OPEN状态转到CLOSING状态。持有该Region的RegionServer可能已/未收到该关闭请求。Master重试发送关闭请求,直到RPC通过或重试次数达到阈值。
-
CLOSING->OFFLINE
如果RegionServer离线或抛出NotServingRegionException,则Master将该Region移至OFFLINE状态,并将其重新分配给其他RegionServer。
-
CLOSING->FAILED_CLOSE
如果RegionServer处于在线状态,但Master重试发送关闭请求达到阈值,则会将该Region设为FAILED_CLOSE状态,并且在管理员从HBase shell进行干预或服务器已停止之前不会采取进一步操作。
-
CLOSING->CLOSED
如果RegionServer获取到关闭Region请求,它将关闭该Region并通知Master将该Region设为CLOSED状态,并将其重新分配给其他RegionServer。
-
CLOSED->OFFLINE
在分配Region之前处于CLOSED状态,则Master会自动将Region移动到OFFLINE状态。
-
OPEN->SPLITING
当RegionServer即将拆分Region时,它会通知Master将要拆分的Region从OPEN切换到SPLITTING状态,并将拆分后要创建的两个新Region添加到RegionServer。这两个Region最初处于SPLITTING_NEW状态。
-
SPLITING->SPLIT
通知Master后,RegionServer开始拆分Region。一旦超过no return点,RegionServer就会再次通知Master以便更新META表。但在通知拆分完成之前,Master不会真正更新Region状态。如果拆分成功,则拆分区域将从SPLITTING移至SPLIT状态,并且两个新Region将从SPLITTING_NEW移至OPEN状态(13)。
-
SPLITTING->OPEN, SPLITTING_NEW->OFFLINE
如果拆分失败,则拆分Region将从SPLITTING移回OPEN状态,并且创建的两个新Region将从SPLITTING_NEW移至OFFLINE状态。
-
OPEN->MERGING
当RegionServer即将合并两个Region时会首先通知Master。Master将要合并的两个Region从OPEN迁移到MERGING状态,并将用来保存合并后内容的新Region添加到RegionServer。新Region最初处于MERGING_NEW状态。
-
MERGING->MERGED, MERGING_NEW->OPEN
通知Master后,RegionServer开始合并这两个Region。一旦超过no return点,RegionServer就会再次通知r,以便Master可以更新META。但在通知合并已完成之前,Master不会更新区域状态。如果合并成功,则两个合并Region从MERGING状态转移到MERGED状态;新Region从MERGING_NEW移动到OPEN状态。
-
MERGING->OPEN, MEGING_NEW->OFFLINE
如果两个Region合并失败,则他们会从MERGING移回到OPEN状态;而那个用于存放合并后内容的新Region则从MERGING_NEW转移到OFFLINE状态。
-
FAILED_CLOSE->CLOSING, FAILED_OPEN->CLOSING
对于处于FAILED_OPEN或FAILED_CLOSE状态的Region,当Master通过HBase Shell重新分配它们时会先尝试再次关闭它们。
3.6.6 负载均衡
由Master的LoadBalancer线程周期性的在各个RegionServer间移动region维护负载均衡。
3.6.7 Failover
请点击这里
3.6.8 Region不能过多
可参考官网-Why should I keep my Region count low?
官方推荐每个RegionServer拥有100个左右region效果最佳,控制数量的原因如下:
-
MSLAB

HBase的一个特性MSLAB(MemStore-local allocation buffer,Memstore内存本地分配缓冲,将JVM Heap分为很多Chunk) ,它有助于防止堆内存的碎片化,减轻Full GC的问题(CMS会因为是标记-清除算法而导致老年代内存碎片,碎片过小无法分配新对象导致FullGC整理内存),默认开启,但他与MemStore一一对应,每个就占用2MB空间。比如一个HBase表有1000个region,每个region有2个CF,那也就是不存储数据就占用了3.9G内存空间,如果极多可能造成OOM需要关闭此特性。
HBase不适用TLAB线程私有化分配的原因是一个线程管理了多个Region的多个MemStore,无法隔离各个MemStore内存。比如5个Region(A-E),然后分别写入ABCDEABCEDDAECBACEBCED,然后B的MemStore发生了Flush,内存情况现在是:A CDEA CEDDAEC ACE CED,显然产生了内存碎片!如果后面的写入还是如之前一样的大小,不会有问题,但一旦超过就无法分配。也就是说,一个Region的MemStore内的内容其实在老年代内存物理地址上并不连续。于是HBase参考TLAB实现了一套以MemStore为最小分配单元的内存管理机制MSLAB。
RegionServer维护了一个全局MemStoreChunkPool实例,而每个MemStore实例又维护了一个MemStoreLAB实例,每个MemStore独占若干Chunk。所以MemStore收到KeyValue数据后先从MemStoreChunkPool中申请一个Chunk放入数据(放入curChunk并移动偏移量),放满了就重新申请Chunk来放数据。该过程是LockFree的,基于CAS。
如果MemStore因为flush而释放内存,则以chunk为单位来清理内存,避免内存碎片。注意,虽然能解决内存碎片,但会因为Chunk放小数据而降低内存利用率。
MSLAB还有一个好处是使得原本分开的MemStore内存分配变为老年代中连续的Chunk内分配。
最大的好处就是几乎完全避免了GC STW!
-
每个Region的每个列族就有一个Memstore,Region过多那么MemStore更多,总内存过大频繁触发Region Server级别阈值导致Region Server级别flush,会对用户请求产生较大的影响,可能阻塞服务响应或产生compaction storm(因为Region过多导致StoreFile也过多,不断合并)。
-
HMaster要花大量的时间来分配和移动Region,且过多Region会增加ZooKeeper的负担。
-
默认MR任务一个region对应一个mapper,region太多会造成mapper任务过多。
推荐的每个RegionServer的Region数量公式如下:
((RS memory) * (total memstore fraction)) / ((memstore size)*(# column families))
3.6.9 Region不能过大
在生产环境中如果Region过大会造成compaction尤其是major compaction严重影响性能,目前推荐的region最大10-20Gb,最优5-10Gb。参数hbase.hregion.max.filesize控制单个region的HFile总大小最大值,再大就会触发split了:
- 当
hbase.hregion.max.filesize比较小时,触发split的机率更大,系统的整体访问服务会出现不稳定现象。
- 当hbase.hregion.max.filesize比较大时,由于长期得不到split,因此同一个region内发生多次compaction的机会增加了。这样会降低系统的性能、稳定性,因此平均吞吐量会受到一些影响而下降。
3.6.10 Region-RegionServer Locality(本地性)
RegionServer本地性是通过HDFS Block副本实现。
当某个RS故障后,其他的RS也许会因为Region恢复而被Master分配非本地的Region的StoreFiles文件(其实就是之前挂掉的RS节点上的StoreFiles的HDFS副本)。但随着新数据写入该Region,或是该表被合并、StoreFiles重写等之后,这些数据又变得相对来说本地化了。
3.7 Region元数据-META表
3.7.1 概述
Region元数据详细信息存于.META.表(没错,也是一张HBase表,只是HBase shell的list命令看不到)中(最新版称为hbase:meta表),该表的位置信息存在ZK中。
该表的结构如下:
-
Key
该Region的key信息,格式:([table],[region start key],[region id])
-
Values
- info:regioninfo
该Region对应的序列化了的HRegionInfo实例
- info:server
包含该Region的RegionServer的server:port
- info:serverstartcode
包含该Region的RegionServer的进程启动时间
3.7.2 表结构
- Key
([table],[region start key],[region id])
- Values
info:regioninfo
info:server (包含该Region的RegionServer之server:port)
info:serverstartcode (包含该Region的RegionServer启动时间)
3.8 MemStore
3.8.1 概述
一个Store有一个MemStore,保存数据修改。当flush后,当前MemStore就被清理了。
注意,MemStorez中的数据按 RowKey 字典升序排序。
- MemStore存在的意义:
- HBase需要将写入的数据顺序写入HDFS,但因写入的数据流是未排序的及HDFS文件不可修改特性,所以引入了MemStore,在flush的时候按 RowKey 字典升序排序进行排序再写入HDFS。
- 充当内存缓存,在更多是访问最近写入数据的场景中十分有效
- 可在写入磁盘前进行优化,比如有多个对同一个cell进行的更新操作,那就在flush时只取最后一次进行刷盘,减少磁盘IO。
3.8.2 Flush
- 注意:
Memstore Flush最小单位是Region,而不是单个MemStore。
3.8.2.1 flush过程
为了减少flush过程对读写影响,HBase采用了类似于2PC的方式,将整个flush过程分为三个阶段:
-
prepare
遍历当前Region中的所有Memstore,将Memstore中当前数据集kvset做一个快照snapshot,对后来的读请求提供服务,读不到再去BlockCache/HFile中查找。
然后再新建一个新的kvset Memstore(SkipList),服务于后来的写入。
prepare阶段需要加一把写锁对写请求阻塞,结束之后会释放该锁。因为此阶段没有任何费时操作,因此持锁时间很短。
-
flush
遍历所有Memstore,将prepare阶段生成的snapshot持久化为临时文件,临时文件会统一放到目录.tmp下。这个过程因为涉及到磁盘IO操作,因此相对比较耗时,但不会影响读写。
-
commit
遍历Region所有的Memstore,将flush阶段生成的临时文件移到指定的ColumnFamily目录下,针对HFile生成对应的storefile和Reader,随后把storefile添加到HStore的storefiles列表中。最后清空prepare阶段生成的snapshot。
-
整个flush过程还可能涉及到compact和split
3.8.2.2 Snapshot-快照读
当Flush发生时,当前MemStore实例会被移动到一个snapshot中,然后被清理掉。在此期间,新来的写操作会被新的MemStore和刚才提到的备份snapshot接收,直到flush成功后,snapshot才会被废弃。
3.8.2.3 MemStore Flush时机
-
Region级别-跨列族
Region内的其中一个MemStore大小达到阈值(hbase.hregion.memstore.flush.size),该Region所有MemStore一起发生Flush,输入磁盘。
-
RegionServer级别
当一个RS内的全部MemStore使用内存总量所占比例达到了阈值(hbase.regionserver.global.memstore.upperLimit),那么会一起按Region的MemStore用量降序排列flush,直到降低到阈值(hbase.regionserver.global.memstore.lowerLimit)以下。
另有一个新的参数hbase.regionserver.global.memstore.size,设定了一个RS内全部Memstore的总大小阈值,默认大小为Heap的40%,达到阈值以后就会阻塞更新请求,并开始RS级别的MemStore flush,和上述行为相同。
-
HLog-WAL文件
当region server的WAL的log数量达到hbase.regionserver.max.logs,该server上多个region的MemStore会被刷写到磁盘(按照时间顺序),以降低WAL的大小。否则会导致故障恢复时间过长。
-
手动触发
通过HBase shell或Java Api手动触发MemStore flush
3.8.2.4 其他Flush重要点
-
MemStore Flush不会更新BlockCache
不会造成从BlockCache读到脏数据:
- 如果是Get最新版本,则会先搜索MemStore,如果有就直接返回,否则需要查找BlockCache和HFile且做归并排序找到最新版本返回。
- 如果是查找多个版本,则会先搜索MemStore,如果有足够的版本就返回,否则还需要查找BlockCache和HFile且做归并排序找到足够多的的最新版本返回。
-
Flush阻塞
当MemStore的数据达到hbase.hregion.memstore.block.multiplier 乘以 hbase.hregion.memstore.flush.size字节时,会阻塞写入,主要是为了防止在update高峰期间MemStore大小失控,造成其flush的文件需要很长时间来compact或split,甚至造成OOM服务直接down掉。内存足够大时,可调大该值。
所以,针对此,我们需要避免Region数量或列族数量过多造成MemStore太大。
3.8.2.5 HBase 2.0 Flush
可参考hbase实践之flush and compaction
增加了内存中Compact逻辑。MemStore变为由一个可写的Segment,以及一个或多个不可写的Segments构成。
3.8.3 Snapshot
MemStore Flush时,为了避免对读请求的影响,MemStore会对当前内存数据kvset创建snapshot,并清空kvset的内容。
读请求在查询KeyValue的时候也会同时查询snapshot,这样就不会受到太大影响。但是要注意,写请求是把数据写入到kvset里面,因此必须加锁避免线程访问发生冲突。由于可能有多个写请求同时存在,因此写请求获取的是updatesLock的readLock,而snapshot同一时间只有一个,因此获取的是updatesLock的writeLock。
3.8.4 写入
数据修改操作先写入MemStore,在该内存为有序状态。
3.8.5 读取
先查MemStore,查不到再去查StoreFile。
Scan具体读取步骤如下:
-
客户端对table发起scan操作时,HBase的RegionServer会为每个region构建一个RegionScanner
-
RegionScanner包含一个StoreScanner列表,每个列族创建了一个StoreScanner
-
StoreScanner又为每个StoreFile创建了一个StoreFileScanner构成list,以及为MemStore传了一个KeyValueScanner列表。
-
上述两个列表最终会合并为一个最小堆(其实是优先级队列),其中的元素是上述的两类scanner,元素按seek到的keyvalue大小按升序排列。
HBase中,Key大小首先比较RowKey,RowKey越小Key就越小;RowKey如果相同就看CF,CF越小Key越小;CF如果相同看Qualifier,Qualifier越小Key越小;Qualifier如果相同再看Timestamp,Timestamp越大表示时间越新,对应的Key越小;如果Timestamp还相同,就看KeyType,KeyType按照DeleteFamily -> DeleteColumn -> Delete -> Put 顺序依次对应的Key越来越大。
-
当构建StoreFileScanner后,会自动关联一个MultiVersionConcurrencyControl Read Point,他是当前的MemStore版本,scan操作只能读到这个点之前的数据。ReadPoint之后的更改会被过滤掉,不能被搜索到。这也就是所谓的读提交(RC)。
-
查询的scanner会组成最小堆,每次pop出堆顶的那个scanner seek到的KeyValue,进行如下判定:
- 检查该KeyValue的KeyType是否是Deleted/DeletedCol等,如果是就直接忽略该列所有其他版本,跳到下列(列族)
- 检查该KeyValue的Timestamp是否在用户设定的Timestamp Range范围,如果不在该范围,忽略
- 检查该KeyValue是否满足用户设置的各种filter过滤器,如果不满足,忽略
- 检查该KeyValue是否满足用户查询中设定的versions,比如用户只查询最新版本,则忽略该cell的其他版本;反之,如果用户查询所有版本,则还需要查询该cell的其他版本。
- 上一步检查KeyValue检查完毕后,会对当前堆顶scanner执行next方法检索下一个scanner,并重新组织最小堆,又会按KeyValue排序规则重新排序组织。不断重复这个过程,直到一行数据被全部查找完毕,继续查找下一行数据。
更多关于数据读取流程具体到scanner粒度的请阅读HBase原理-数据读取流程解析
3.9 Storefile
3.9.1 概述
一个Store有>=0个SotreFiles(HFiles)。
StoreFiles由块(Block)组成。块大小( BlockSize)是基于每个列族配置的。压缩是以块为单位。
3.9.2 HFile
可参考:
- Apache HBase-HFile format
- HBase – 存储文件HFile结构解析
- HBase – 探索HFile索引机制
注:目前HFile有v1 v2 v3三个版本,其中v2是v1的大幅优化后版本,v3只是在v2基础上增加了tag等一些小改动,本文介绍v2版本。
HFile格式基于BigTable论文中的SSTable。StoreFile对HFile进行了轻度封装。HFile是在HDFS中存储数据的文件格式。它包含一个多层索引,允许HBase在不必读取整个文件的情况下查找数据。这些索引的大小是块大小(默认为64KB),key大小和存储数据量的一个重要因素。
注意,HFile中的数据按 RowKey 字典升序排序。
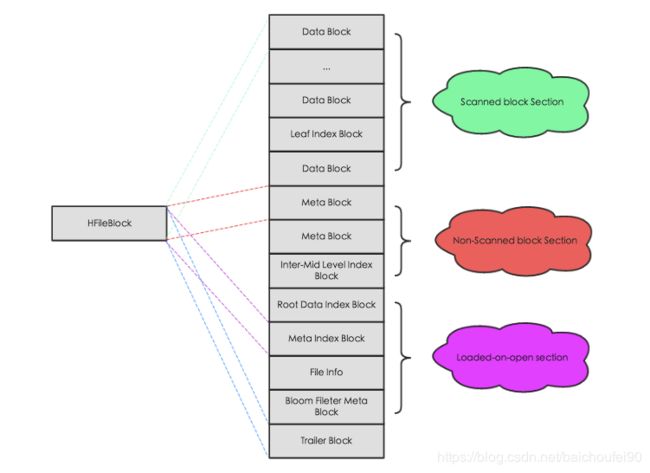
- 数据分布
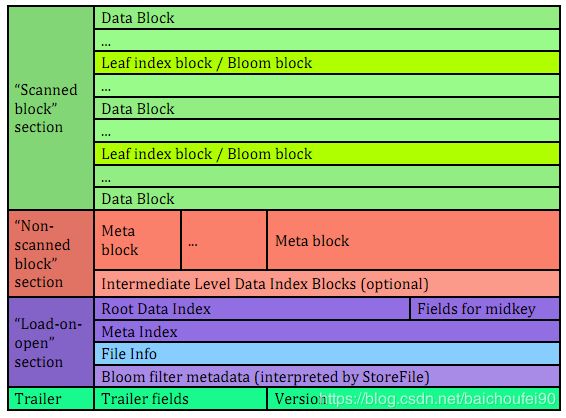
- Scanned block section
scan(顺序扫描)HFile时所有的Block将被读取
- Non-scanned block section
scan时数据不会被读取
- Load-on-open-section
RegionServer启动时需要加载到内存
- Trailer
记录了HFile的基本信息,保存了上述每个段的偏移量(即起始位置)
- HFIle Block
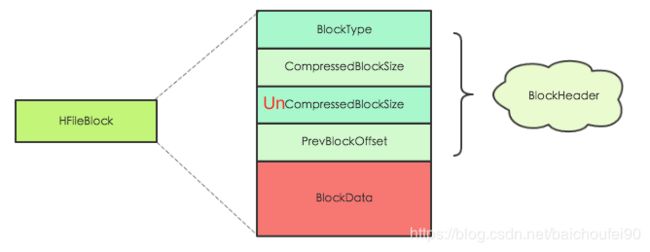
这里的Block是指一个宽泛的概念,主要包括:
- BlockHeader
- BlockType
- DATA – KeyValue数据
- ROOT_INDEX – 多层DataBlock索引中的根索引块
- INTERMEDIATE_INDEX – 多层DataBlock索引中的中间层索引块
- LEAF_INDEX – 多层DataBlock索引中的叶节点
- META – 存放元数据 ,V2后不再跟布隆过滤器相关
- FILE_INFO – 文件信息,极小的key-value元数据
- BLOOM_META – 布隆过滤器元数据
- BLOOM_CHUNK – 布隆过滤器
- TRAILER – 固定大小,记录各Block段偏移值
- INDEX_V1 – 此块类型仅用于传统的HFile v1块
- CompressedBlockSize
DataBlock不包括header的其他部分的压缩后大小,可子scan时被用来跳过当前HFile
- UncompressedBlockSize
DataBlock不包括header的其他部分的未压缩大小
- PrevBlockOffset
前一个相同类型的Block的Offset,可被用来寻找前一个Block
- BlockData
压缩后的数据(为指定压缩算法时直接存)
- HFile各部分详解
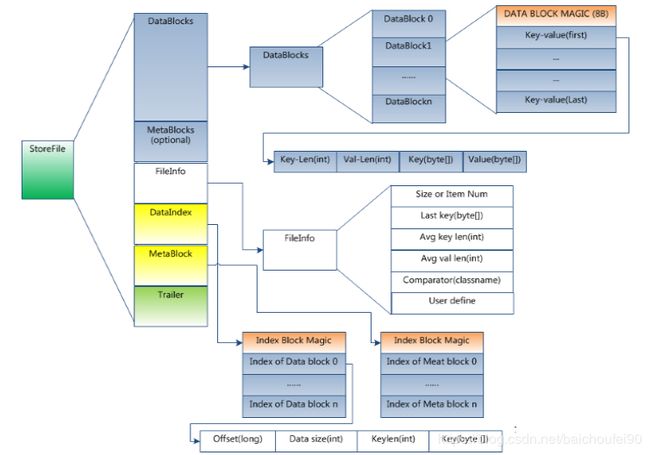
-
DataBlock
- 保存表中的数据,可被压缩,大小默认为64K(由建表时创建cf时指定或者HColumnDescriptor.setBlockSize(size))。
- 每一个DataBlock由
MagicHeader和一些KeyValue组成,key的值是严格按照顺序存储的。
- 在查询数据时,是以DataBlock为单位从硬盘load到内存,顺序遍历该块中的KeyValue。
-
DataIndex
DataBlock的索引,每条索引的key是被索引的block的第一条记录的key(StartKey),采用LRU机制淘汰,可以有多级索引。
格式为:(MagicHeader,(DataBlock在HFile的offset + DataBlockLength + DataBlockFirstKey),(DataBlock在HFile的offset + DataBlockLength + DataBlockFirstKey),……..)。
-
MetaBlock (可选的)
保存用户自定义的KeyValue,可被压缩,如BloomFilter就是存在这里。该块只保留value值,key值保存在元数据索引块中。每一个MetaBlock由header和value组成,可以被用来快速判断指定的key是否都在该HFile中。
-
MetaIndex (可选的)
MetaBlock的索引,只有root级索引,保存在MetaBlock。
格式为:(MagicHeader,(MetaBlock在HFile的offset + MetaBlockLength + MetaBlockName),(MetaBlock在HFile的offset + MetaBlockLength + MetaBlockName),……..)。
-
BloomIndex
作为布隆过滤器MetaData的一部分存储在RS启动时加载区域。
-
FileInfo
HFile的元数据,固定长度,不可压缩,它纪录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等,用户也可以在这一部分添加自定义元数据。
-
Trailer
Trailer是定长的,保存了上述每个段的偏移量(即起始位置),所以读取一个HFile时会先读取Trailer,(段的MagicHeader被用来做安全check),随后读取DataBlockIndex到内存中。
这样一来,当检索某个key时,不需要扫描整个HFile,而只需从内存中的DataBlockIndex找到key所在的DataBlock,随后通过一次磁盘io将整个DataBlock读取到内存中,再找到具体的KeyValue。
Trailer部分格式为:

其中CompressionCodec为int,压缩算法为enum类型,表示压缩算法:LZO-0,GZ-1,NONE-2。
3.9.3 HFile-Block
HFileBlock默认大小是64KB,而HadoopBlock的默认大小为64MB。顺序读多的情况下可配置使用较大HFile块,随机访问多的时候可使用较小HFile块。
不仅是DataBlock,DataBlockIndex和BloomFilter都被拆成了多个Block,都可以按需读取,从而避免在Region Open阶段或读取阶段一次读入大量的数据而真正用到的数据其实就是很少一部分,可有效降低时延。
HBase同一RegionServer上的所有Region共用一份读缓存。当读取磁盘上某一条数据时,HBase会将整个HFile block读到cache中。此后,当client请求临近的数据时可直接访问缓存,响应更快,也就是说,HBase鼓励将那些相似的,会被一起查找的数据存放在一起。
注意,当我们在做全表scan时,为了不刷走读缓存中的热数据,记得关闭读缓存的功能(因为HFile放入LRUCache后,不用的将被清理)
更多关于HFile BlockCache资料请查看HBase BlockCache 101
3.9.4 HFile索引
初始只有一层,数据多时分裂为多层索引(最多可支持三层索引,即最底层的Data Block Index称之为Leaf Index Block,可直接索引到Data Block;中间层称之为Intermediate Index Block,最上层称之为Root Data Index,Root Data index存放在一个称之为"Load-on-open Section"区域,Region Open时会被加载到内存中),使用LruBlockCache::
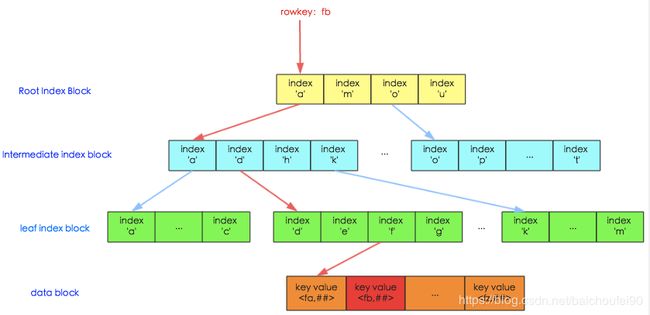
- Load-on-open Section
存放Root Data index,Region打开时就会被加载到内存中
- Scanned Block Section
DataBlock、存放Data Block索引的Leaf Index Block与Bloom Block(Bloom Filter数据)交叉存在
3.9.5 HFile生成
-
初始HFile无Block,数据在MemStore
-
flush发生,HFileWriter初始,DataBlock生成,此时Header为空
-
开始写入,Header被用来存放该DataBlock的元数据信息
-
MemStore的KeyValue,写入DataBlock。如果设置了Data Block Encoding,此时需要进行编码。
-
KeyValue达到Block大小,停止写入
-
对KeyValue进行压缩,再进行加密
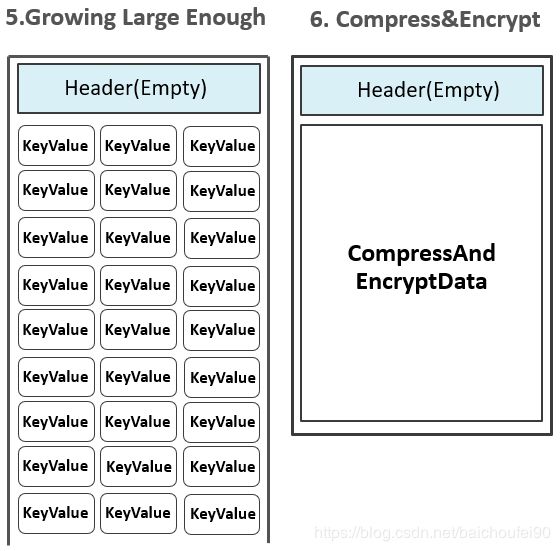
-
在Header区写入对应DataBlock元数据信息,包含{压缩前的大小,压缩后的大小,上一个Block的偏移信息,Checksum元数据信息}等信息。
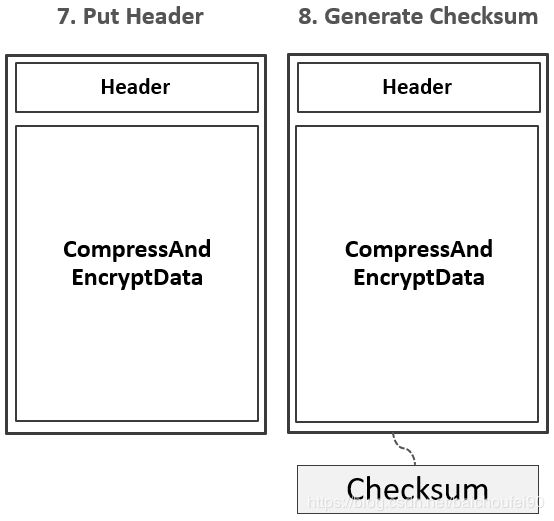
-
生成Checksum校验和信息
-
通过HFileWriter将DataBlock/Checksum写入HDFS
-
为DataBlock生成包含StartKey,Offset,Size等信息的索引,先写入内存中的Block Index Chunk,累积到阈值后刷入HDFS,形成Leaf Index Block。
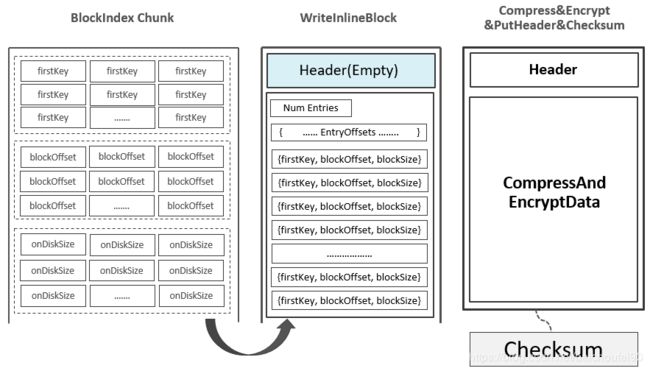
-
DataBlock和DataBlockIndex(Leaf Index Block)在Scanned Block Section交叉存在。
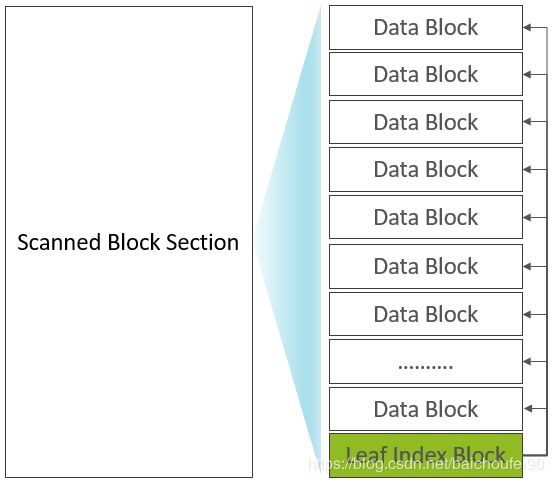
-
而HBase中还存在Root Index Chunk用来记录每个DataBlockIndex的信息,即为DataBlock的索引的索引。
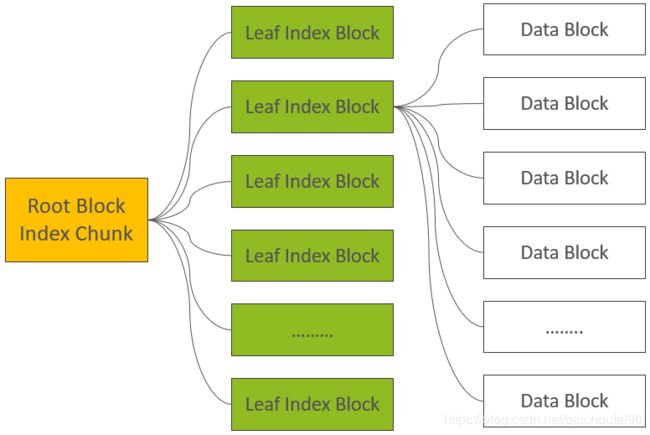
-
当MemStore Flush中最后一个KeyValue写入到最后一个DataBlock即最后一个DataBlockIndex时,随机开始flush Root Index Chunk。
注意,如果Root Index Chunk大小超出阈值,则会生成位于Non-Scanned Block Section区域的Intermediate Index Block,由Root Index生成索引来指向。
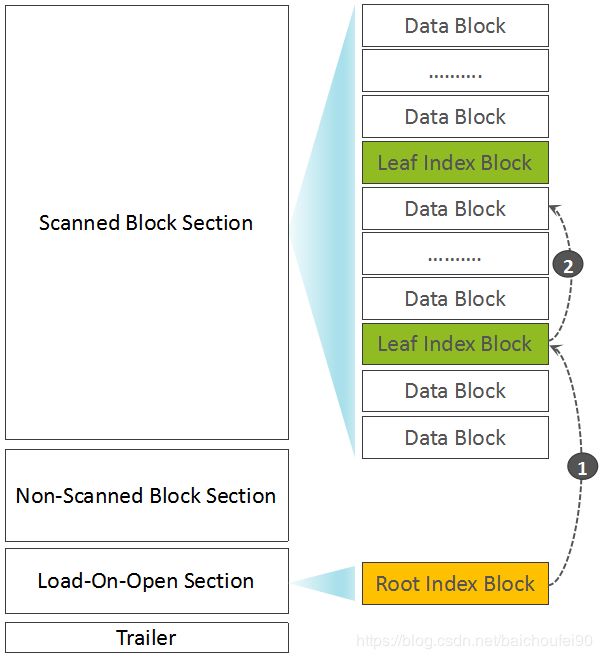
无论如何,都会输出位于的Load-On-Open Section的Root Index Block。
-
生成FileInfo,记录HFile的元数据
-
写入BloomFilter元数据与索引数据
-
最后写入Trailer部分信息
3.9.6 BloomFilter
-
目的
HBase中的BloomFilter提供了一个轻量级的内存结构,以便将给定Get(BloomFilter不能与Scans一起使用,而是Scan中的每一行来使用)的磁盘读取次数减少到仅可能包含所需Row的StoreFiles,而且性能增益随着并行读取的数量增加而增加。
-
和BlockIndex区别
一个Region有多个Store,一个Store需要扫描多个StoreFile(HFile),每个HFile有一个BlockIndex,粒度较粗,需要通过key range扫描很多BlockIndex来判断目标key是否可能在该文件中,但仍需要加载该HFile中的若干Block并scan才能确定是否真的存在目标key。(比如一个1GB的HFile,就包含16384个64KB的Block,且BlockIndex只有StartKey信息。查询一个给点key则可能落在两个Block的StartKey范围之间,需要全部load-scan)。
而BloomFilter对于Get操作以及部分Scan操作可以过滤掉很多肯定不包含目标Key的HFile文件,大大减少实际IO次数,提高随机读性能。
-
使用场景
每个数据条目大小至少为KB级
-
存储位置
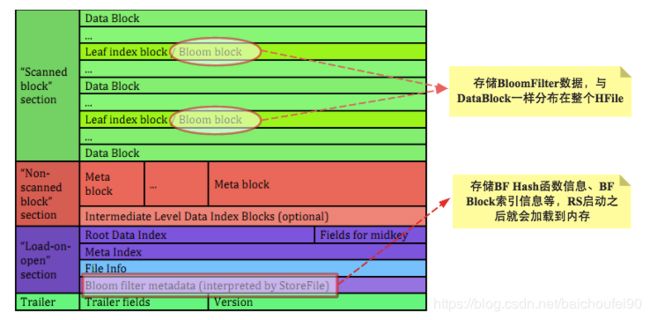
BloomFilter的Hash函数和BloomFilterIndex存储在每个HFile的启动时加载区中;而具体的存放数据的BloomFilterBlock,会随着数据变多而变为多个Block以便按需一次性加载到内存,这些BloomFilterBlock散步在HFile中扫描Block区,不需要更新(因为HFile的不可变性),只是会在删除时会重建BloomFilter,所以不适合大量删除场景。
-
加载时机
当因为Region部署到RegionServer而打开HFile时,BloomFilter将加载到内存。
-
HBase中的BloomFilter实现
KeyValue在写入HFile时,经过若干hash函数的映射将对应的数组位改为1。当Get时也进行相同hash运算,如果遇到某位为0则说明数据肯定不在该HFile中,如果都为1则提示高概率命中。
当然,因为HBase为了权衡内存使用和命中率等,将BloomFilter数组进行了拆分,并引入了BloomIndex,查找时先通过StartKey找到对应的BloomBlock再进行上述查找过程。
-
BloomFilterIndex
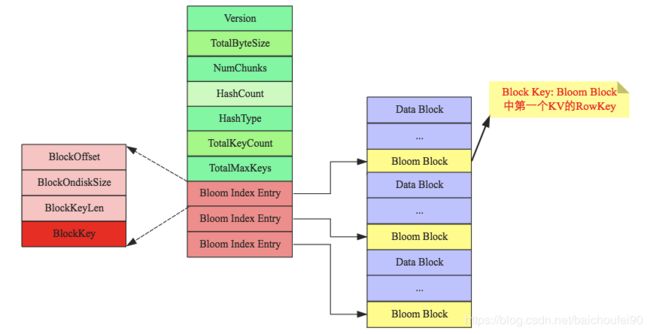
如上图,BloomFilterIndex中的BloomIndexEntry中有个BlockKey存有真实数据KeyValue的StartKey,所以每次需要据此来查找BloomFilterBlock进行使用。
-
弹性
HBase包括一些调整机制,用于折叠(fold)BloomFilter以减小大小并将误报率保持在所需范围内。
-
行-列模式
- 行模式
默认使用行模式BloomFilter,使用RowKey来过滤HFile,适用于行Scan、行+列Get,不适用于大量列Put场景(一行数据此时因为按列插入而分布到多个HFile,这些HFile上的BF会为每个该RowKey的查询都返回true,增加了查询耗时)。
- 行+列模式
可设置某些表使用行+列模式的BloomFilter。除非每行只有一列,否则该模式会为了存储更多Key而占用更多空间。不适用于整行scan。
- 可禁用BloomFilter
- 例子
假设某表有3个HFile文件:
h1:[ kv1(r1 -> cf1:c1,v1), kv2(r2 -> cf1:c1,v2)]
h2:[ kv3(r3 -> cf1:c1,v3), kv4(r4 -> cf1:c1,v4)]
h3:[ kv5(r1 -> cf1:c2,v5), kv6(r2 -> cf1:c2,v6)]
- 行模式BloomFilter,Get(r1)时可过滤掉h2;Get(r4)时可过滤掉h1和h3;Get(r1,c1)也只会过滤掉h2而不会过滤h3
- 行+列模式BloomFilter,Get(r1,c1)过滤掉h2和h3
-
指标
blockCacheHitRatio可观察到RegionServer上的BlockCache缓存命中率,如果开启BloomFilter来过滤那些不包含目标key的Block,则blockCacheHitRatio应该增加。
-
创建BloomFilter
创建HBase表时可用HColumnDescriptor.setBloomFilterType(NONE/ROW (default)/ ROWCOL)或用以下命令创建BloomFilter:
create 'mytable',{NAME => 'colfam1', BLOOMFILTER => 'ROWCOL'}
3.10 BlockCache
可参考HBase BlockCache系列 - 探求BlockCache实现机制
HBase提供两种不同的BlockCache实现,来缓存从HDFS读取的数据:
- 堆内的LRUBlockCache。
- 内存由JVM管理,LRU规则,具体是由
MinMaxPriorityQueue实现
- 默认占HBase用的Java堆大小的40%
- 分为
single-access区(25%,存随机读入的Block块)、mutil-access区(50%,single区中数据被多次读就移入本区)、in-memory区(25%,存储访问频繁且量下的数据,如元数据)
- 数据、META表(永远开启缓存)、HFile、key、BloomFilter等大量使用LRUBlockCache。
- 默认情况下,对所有用户表都启用了块缓存,也就是说任何读操作都将加载LRU缓存。
- 缺点是随着
multi-access区的数据越来越多,会造成CMS FULL GC,导致应用程序长时间暂停
- 通常在堆外的BucketCache
- 申请多种不同规格的多个Bucket,每种存储指定Block大小的DataBlock。当某类Bucket不够时,会从其他Bucket空间借用内存,提高资源利用率。如下就是两种规格的Bucket,注意他们的总大小都是2MB。
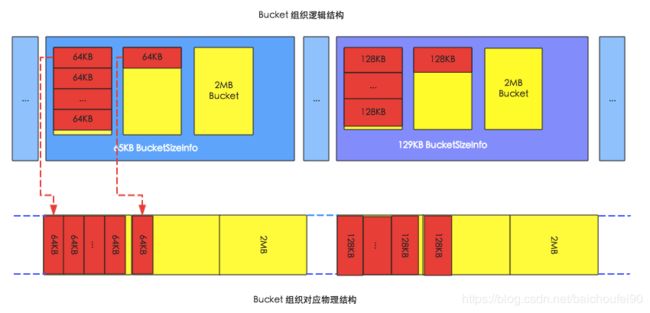
- 三种工作模式:
- heap
表示从JVM Heap中申请的Bucket,有GC开销,分配内存需要从OS分配后拷贝到JVM heap过程。
- offheap
使用NIO DirectByteBuffer技术,实现堆外内存管理。读缓存时需要从OS拷贝到JVM heap读取。
- file
使用类似SSD的高速缓存文件来存储DataBlock ,可存储更多数据,提升缓存命中。
- 实践
- 一般可用LRUBlockCache保存
DataBlockIndex 和BloomFilter,其他数据(比如最主要的DataBlock)放在BucketCache
3.11 KeyValue
3.11.1 概述
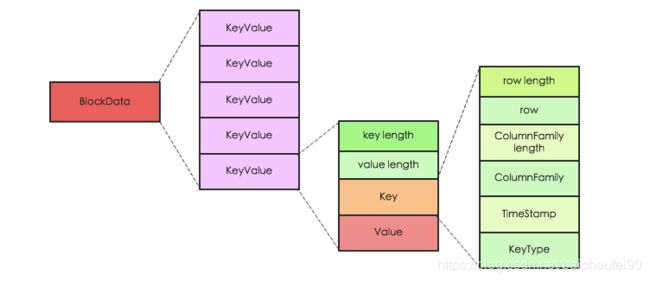
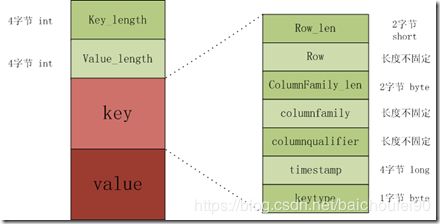
-
KeyValue的构成
KeyValue是HBase的最核心内容。他主要由keylength, valuelength, key, value 四部分组成:
- key
包括了RowKey、列族、列(ColumnQualifier)、时间戳、KeyType(Put、Delete、 DeleteColumn和DeleteFamily)等信息
- value
二进制格式存储的数据主体信息
-
KeyValue与BloomFilter
KeyValue在写入HFile时会用到BloomFilter,经过若干Hash函数计算将某些位置设为1。当查询时也是针对目标RowKey,拿出要查询的HFile上的BloomFilter进行相同hash运算,如果遇到某位置的数为0说明肯定目标数据肯定不存在该HFile中。
当然,实际上HBaseHFile可能特别大,那么所使用的数组就会相应的变得特别大,所以不可能只用一个数组,所以又加入了BloomIndexBlock来查找目标RowKey位于哪个BloomIndex,然后是上述BloomFilter查找过程。
3.11.2 例子
一个put操作如下:
Put #1: rowkey=row1, cf:attr1=value1
他的key组成如下:
rowlength -----------→ 4
row -----------------→ row1
columnfamilylength --→ 2
columnfamily --------→ cf
columnqualifier -----→ attr1
timestamp -----------→ server time of Put
keytype -------------→ Put
3.11.3 小结
所以我们在设计列族、列、rowkey的时候,要尽量简短,不然会大大增加KeyValue大小。
3.12 WAL(Write-Ahead Logging)-HLog
3.12.1 基本概念
-
WAL(Write-Ahead Logging)是一种高效的日志算法,相当于RDBMS中的redoLog,几乎是所有非内存数据库提升写性能的不二法门,基本原理是在数据写入之前首先顺序写入日志,然后再写入缓存,等到缓存写满之后统一落盘。
之所以能够提升写性能,是因为WAL将一次随机写转化为了一次顺序写加一次内存写。提升写性能的同时,WAL可以保证数据的可靠性,即在任何情况下数据不丢失。假如一次写入完成之后发生了宕机,即使所有缓存中的数据丢失,也可以通过恢复日志还原出丢失的数据(如果RegionServer崩溃可用HLog重放恢复Region数据)。
-
一个RegionServer上存在多个Region和一个WAL实例,注意并不是只有一个WAL文件,而是滚动切换写新的HLog文件,并按策略删除旧的文件。
-
一个RS共用一个WAL的原因是减少磁盘IO开销,减少磁盘寻道时间。
-
可以配置MultiWAL,多Region时使用多个管道来并行写入多个WAL流。
-
当WAL文件数量达到最大个数的时候,就触发该RegionServer上的所有MemStore 按FIFO顺序进行Flush,直到WAL数量降到hbase.regionserver.max.logs以下。此后,那些对应的HLog被视为过期,会被移动到.oldlogs,随后被自动删除
-
WAL的意义就是和Memstore一起将随机写转为一次顺序写+内存写,提升了写入性能,并能保证数据不丢失。
3.12.2 生命周期
注:本段转自Hbase 技术细节笔记(上)
Hlog从产生到最后删除需要经历如下几个过程:
-
产生
所有涉及到数据的变更都会先写HLog,除非是你关闭了HLog
-
滚动
HLog的大小通过参数hbase.regionserver.logroll.period控制,默认是1个小时,时间达到hbase.regionserver.logroll.period 设置的时间,HBase的一个后台线程就会创建一个新的Hlog文件。这就实现了HLog滚动的目的。HBase通过hbase.regionserver.maxlogs参数控制Hlog的个数。滚动的目的,为了控制单个HLog文件过大的情况,方便后续的过期和删除。
-
过期与sequenceid
Hlog的过期依赖于对sequenceid的判断。HBase会将HLog的sequenceid和HFile最大的sequenceid(刷新到的最新位置)进行比较,如果该Hlog文件中的sequenceid比flush的最新位置的sequenceid要小,那么这个HLog就过期了,对应HLog会被移动到.oldlogs目录。
这里有个问题,为什么要将过期的Hlog移动到.oldlogs目录,而不是直接删除呢?
答案是因为HBase还有一个主从同步的功能,这个依赖Hlog来同步HBase的变更,有一种情况不能删除HLog,那就是HLog虽然过期,但是对应的HLog并没有同步完成,因此比较好的做好是移动到别的目录。再增加对应的检查和保留时间。
-
删除
如果HLog开启了replication,当replication执行完一个Hlog的时候,会删除Zoopkeeper上的对应Hlog节点。在Hlog被移动到.oldlogs目录后,HBase每隔hbase.master.cleaner.interval(默认60秒)时间会去检查.oldlogs目录下的所有Hlog,确认对应的Zookeeper的Hlog节点是否被删除,如果Zookeeper 上不存在对应的Hlog节点,那么就直接删除对应的Hlog。
hbase.master.logcleaner.ttl(默认10分钟)这个参数设置Hlog在.oldlogs目录保留的最长时间。
3.12.3 WAL持久化等级
- SYNC_WAL: 默认. 所有操作先被执行sync操作到HDFS(不保证落盘),再返回.
- FSYNC_WAL: 所有操作先被执行fsync操作到HDFS(强制落盘),再返回。最严格,但速度最慢。
- SKIP_WAL: 不写WAL。提升速度,但有极大丢失数据风险!
- ASYNC_WAL: 异步写WAL,可能丢失数据。
3.12.4 WAL数据结构
前面提到过,一个RegionServer共用一个WAL。下图是一个RS上的3个Region共用一个WAL实例的示意图:
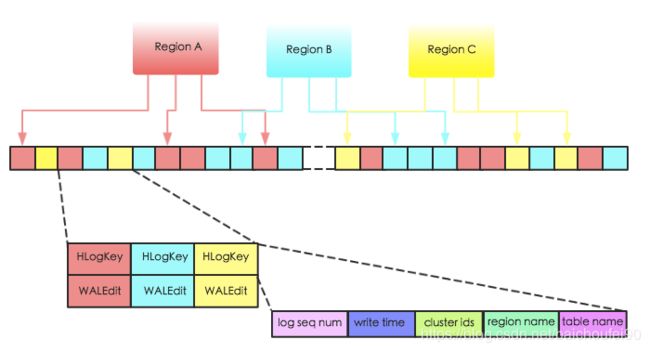
数据写入时,会将若干数据对
-
HLogKey主要包括:
- LogSequenceNumber(SequenceId)
日志写入时分配给数据的一个Region级别的自增数字,决定了HLog的过期,也就决定了HLog的生命周期
- WriteTime
- RegioNname
- TableName
- ClusterIds
用于将日志复制到集群中其他机器上
-
WALEdit
用来表示一个事务中的更新集合,在目前的版本,如果一个事务中对一行row R中三列c1,c2,c3分别做了修改,那么HLog为了行级事务原子性日志片段如下所示:
:
其中WALEdit会被序列化为格式<-1, # of edits, , , > ,比如<-1, 3, , , > ,其中-1作为标示符表征这种新的日志结构。
3.12.5 WAL写入流程
见这里
4 HBase数据模型
4.1 逻辑模型
4.1.1 逻辑视图与稀疏性
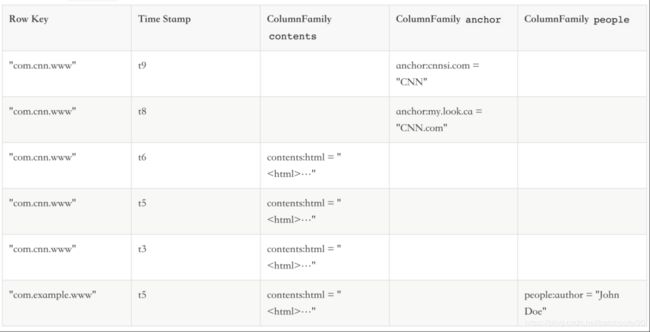
上表是HBase逻辑视图,其中空白的区域并不会占用空间。这也就是为什么成为HBase是稀疏表的原因。
4.1.2 HBase数据模型基本概念
-
Namespace
类似RDBMS的库。建表时指定,否则会被分配default namespace。
-
Table
类似RDBMS的表
-
RowKey
- 是Byte Array(字节数组),是表中每条记录的“主键”,即唯一标识某行的元素,方便快速查找,RowKey的设计非常重要。
- MemStore和HFile中按RowKey的字典升序排列。
- 且RowKey符合最左匹配原则。如设计RowKey为
uid + phone + name,那么可以匹配一下内容:
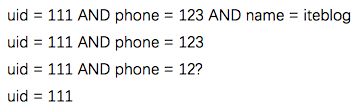
但是无法用RowKey支持以下搜索:

-
Column Family
即列族,拥有一个名称(string),包含一个或者多个列,物理上存在一起。比如,列courses:history 和 courses:math都是 列族 courses的成员.冒号(:)是列族的分隔符。建表时就必须要确定有几个列族。每个
-
Column
即列,属于某个columnfamily,familyName:columnName。列可动态添加
-
Version Number
即版本号,类型为Long,默认值是系统时间戳timestamp,也可由用户自定义。相同行、列的cell按版本号倒序排列。多个相同version的写,只会采用最后一个。
-
Value(Cell)
{row, column, version} 组一个cell即单元格,其内容是byte数组。
-
Region
表水平拆分为多个Region,是HBase集群分布数据的最小单位。
4.2 物理模型
-
HBase表的同一个region放在一个目录里

-
一个region下的不同列族放在不同目录


4.3 有序性
每行的数据按rowkey->列族->列名->timestamp(版本号)逆序排列,也就是说最新版本数据在最前面。
4.4 ACID
请查看事务章节。
5 HBase 容错
5.1 RegionServer

- Region Failover:发现失效的Region,先标记这些Region失效,然后到正常的RegionServer上恢复他们
- RegionSever Failover:由HMaster对其上的region进行迁移
具体来说
-
RegionServer定时向Zookeeper发送心跳
-
RegionServer挂掉后一段时间(SessionTimeout),在ZK注册的临时节点会被删除,此时该RS上的Region立刻变得不可用
-
HMaster监听到ZK事件得知该RS挂掉,HMaster会认为其上的Region分配非法,开启Region重分配流程。
将该RegionServer在HDFS上的那个HLog文件按Region进行切分,并待不可用的那些Region重分配到其他RegionServer后,对HLog按照Region和sequenceid由小到大进行重放补足HLog中的数据。
-
在此过程中的客户端查询会被重试,不会丢失
详细流程可以参考:
- Hbase 技术细节笔记(下)
- HBase原理-RegionServer宕机数据恢复
5.2 Master Failover
Zookeeper选举机制选出一个新的Leader Master。但要注意在没有Master存活时:
- 数据读写仍照常进行,因为读写操作是通过
.META.表进行。
- 无master过程中,region切分、负载均衡等无法进行(因为master负责)
5.3 Zookeeper容错
Zookeeper是一个可靠地分布式服务
5.4 HDFS
HDFS是一个可靠地分布式服务
6 HBase数据流程
6.1 客户端Region定位和Scan流程
注意,该过程中Client不会和Master联系,只需要配置ZK信息。
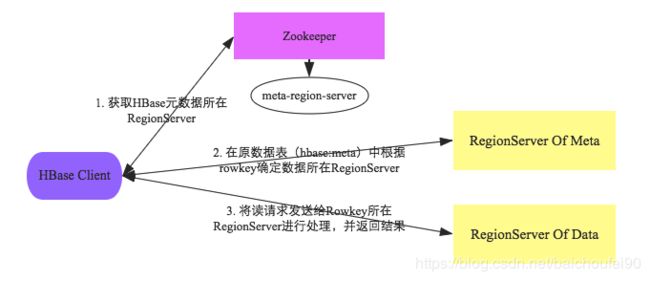
-
Client访问Zookeeper,找到hbase:meta表所在RegionServer
-
根据所查数据的Namespace、表名和rowkey在hbase:meta表顺序查找找到对应的Region信息,并会对该Region位置信息进行缓存。
如果Region由master负载均衡重新分配,或因为相关RegionServer挂掉,则Client将重新查询hbase:meta表以确定Region的新位置然后放入缓存。
-
下一步就可以请求Region所在RegionServer了,会初始化三层scanner实例来一行一行的每个列族分别查找目标数据:
- RegionScanner
根据列族个数构建对应数量的StoreScanner
- StoreScanner
- 统筹扫描对应列族数据,构建一个MemStoreScanner和StoreFile个StoreFileScanner。
- 随后还需要根据TimeRange/KeyRange/BloomFilter 过滤掉肯定不包含目标Key的 StoreFileScanner和MemStoreScanner。
- MemStoreScanner
真正执行扫描MemStore中的数据
- StoreFileScanner
真正执行扫描对应StoreFile(HFile)数据,例子可见这里:
- 定位DataBlock:从BlockCache中读取该HFile的索引结构,确定目标Key所在的DataBlock的Offset
- 加载DataBlock:根据Offset,首先在BlockCache中查找,若没找到就IO读取HFile来加载目标DataBlock
- 定位Key:在DataBlock中二分查找定位目标Key
- 随后将上述MemStoreScanner和StoreFileScanner合并,并用
PriorityQueue优先级队列来构建最小堆,排序规则是RowKey分别比较RowKey(小优先),ColumnFamily(小优先),Qualifier(小优先),TimeStamp(大优先),KeyType(DeleteFamily -> DeleteColumn -> Delete -> Put),这样便于客户端取数据(比如需要获取最新版本数据时只需要再按版本号排次序即可)
- 将堆顶数据出堆,进行检查,比如是否ttl过期/是否KeyType为
Delete*/是否被用户设置的其他Filter过滤掉,如果通过检查就加入结果集等待返回。如果查询未结束,则剩余元素重新调整最小堆,继续这一查找检查过程,直到结束。
-
RegionScanner将多个StoreScanner按列族小优先规则来合并构建最小堆
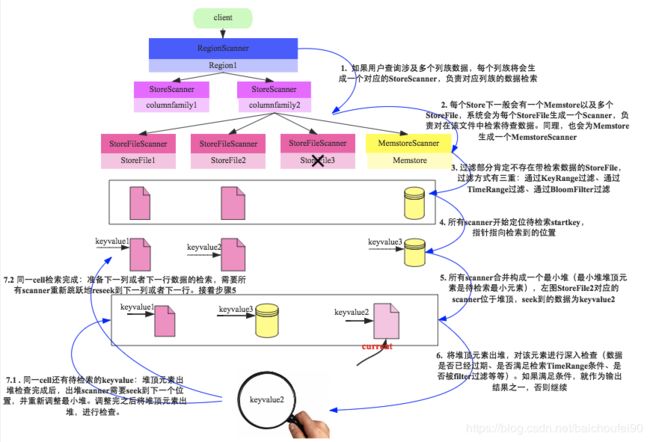
- 具体例子可参考:
-
网易范欣欣-HBase-数据读取流程解析
-
网易范欣欣-HBase-迟到的‘数据读取流程’部分细节
-
StoreFileScanner查找磁盘。为了加速查找,使用了快索引和布隆过滤器:
-
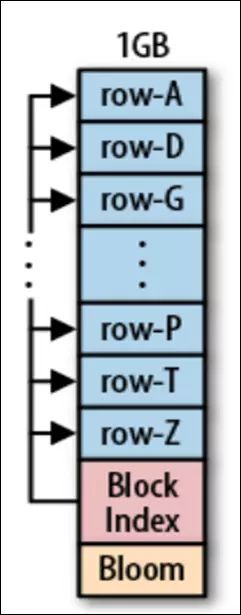
块索引
块索引存储在HFile文件末端,查找目标数据时先将块索引读入内存。因为HFile中的KeyValue字节数据是按字典序排列,而块索引存储了所有HFile block的起始key,所以我们可快速定位目标数据可能所在的块,只将其读到内存,加快查找速度。
-
布隆过滤器
虽然块索引减少了需要读到内存中的数据,但依然需要对每个HFile文件中的块执行查找。
而布隆过滤器则可以帮助我们跳过那些一定不包含目标数据的文件。和块索引一样,布隆过滤器也被存储在文件末端,会被优先加载到内存中。另外,布隆过滤器分行式和列式两种,列式需要更多的存储空间,因此如果是按行读取数据,没必要使用列式的布隆过滤器。布隆过滤器如下图所示:
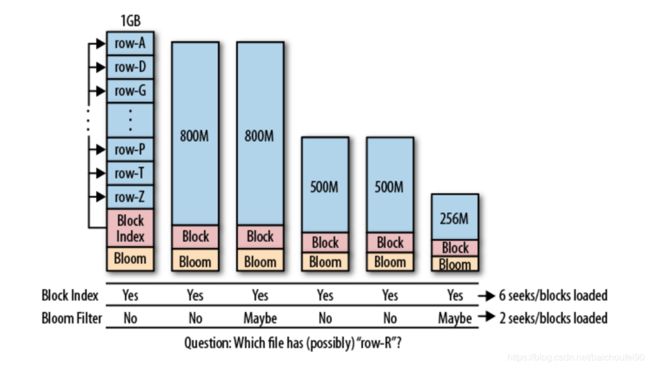
块索引和布隆过滤器对比如下:
块索引
布隆过滤器
功能
快速定位记录在HFile中可能的块
快速判断HFile块中是否包含目标记录
- 读写请求一般会先访问MemStore
6.2 写流程
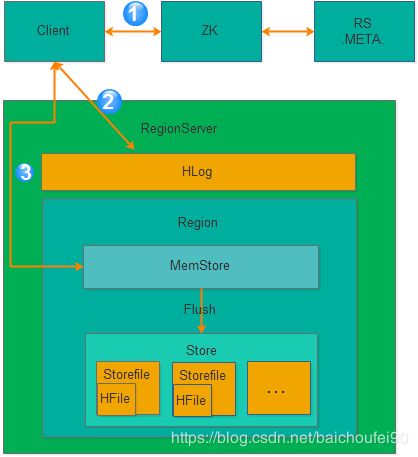
6.2.1 Client
- Client默认设置
autoflush=true,表示put请求直接会提交给服务器进行处理;也可设置autoflush=false,put请求会首先放到本地buffer,等到本地buffer大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会异步批量提交。很显然,后者采用批处理方式提交请求,可极大地提升写入性能,但因为没有保护机制,如果该过程中Client挂掉的话会因为内存中的那些buffer数据丢失导致提交的请求数据丢失!
- Client定位到数据所在RegionServer。若是批量请求,还会将rowkey按
HRegionLocation分组,每个分组可对应一次RPC请求MultiServerCallable|
。
- Client为通过
rpcCallerFactory. newCaller() 执行调用,忽略掉失败重新提交和错误处理。
6.2.2 Server
- Server尝试获取行锁(行锁可保证行级事务原子性)来锁定目标行(或多行),检索当前的
WriteNumber(可用于MVCC的非锁读),并获取Region更新锁,写事务开始。
- Server把数据构造为WALEdit对象,然后按顺序写一份到WAL(一个RegionServer共用一个WAL实例)。当RS突然崩溃时且事务已经写入WAL,那就会在其他RS节点上重放。
- Server把数据再写一份到MemStore(每个Store一个MemStore实例),此时会把获取到的
WriteNumber附加到KeyValue。
- Flush
Server待MemStore达到阈值后,会把数据刷入磁盘,形成一个StoreFile文件。若在此过程中挂掉,可通过HLog重放恢复。成功刷入磁盘后,会清空HLog和MemStore。
- Compact
Server待当多个StoreFile文件达到一定的大小后,会触发Compact合并操作
- Split
Server当Region大小超过一定阈值后,会触发Split拆分操作
- Server提交该事务。随后,
ReadPoint(即读线程能看到的WriteNumber)就能前移,从而检索到该新的事务编号,使得scan和get能获取到最新数据
- Server释放行锁和共享锁。选择这个时间释放行锁的原因是可尽量减少持有互斥的行级写锁时间,提升写性能。
- Server SyncHLog。此时如果Sync操作失败,会对写入Memstore内的数据进行移除,即回滚。
- 如果上一步提交,则flush memstore
6.3 读流程
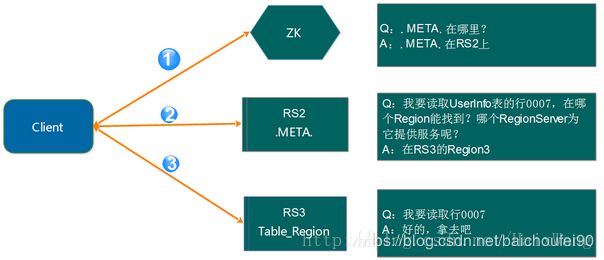
此过程不需要HMbaster参与:
- 定位到数据所在RegionServer进行读请求
- 先从写缓存MemStore找数据
- 如果没有,再到读缓存HFile BlockCache上读
- 如果还是没有,再到HFile文件上读
- 若Region元数据如位置发生了变化,那么使用
.META.表缓存区访问RS时会找不到目标Region,会进行重试,重试次数达到阈值后会去.META.表查找最新数据并更新缓存。
6.4 删除
- 在执行
delete命令时,hbase只是添加
- 有墓碑时,该key对应数据被查询时就会被过滤掉。
- 在
Major Compact中被删除的数据和此墓碑标记才从StoreFile会被真正删除。
6.5 TTL过期
-
CF默认的TTL值是FOREVER,也就是永不过期。
-
过期数据不会创建墓碑,如果一个StoreFile仅包括过期的rows,会在Minor Compact的时候被清理掉,不再写入合并后的StoreFile。
-
TTL分为两类即Cell和CF:
- Cell TTL 以毫秒为单位,不可超过CF级别的TTL
- CF TTL以秒为单位
-
注意:修改表结构之前,需要先disable 表,否则表中的记录被清空!
-
还可参考:
- HBase的TTL介绍
- 官网-HBase-TTL
6.6 WAL写入
总的来说,分为三个步骤:
- 若干
- Buffer Flush到HDFS,此时不保证落盘
- HDFS fsync落盘
-
老写入模型
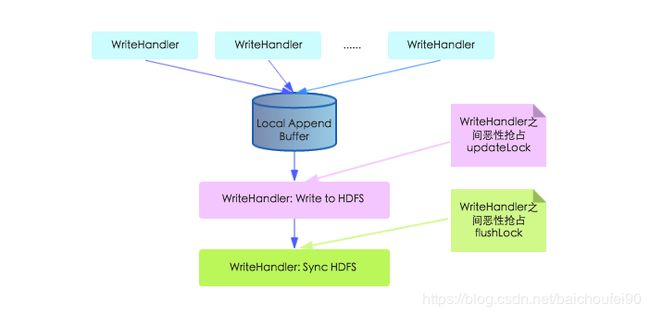
在老的写入模型中,每个写入线程的WriteHandler都需要分别竞争updateLock和flushLock,效率较低。
-
新写入模型
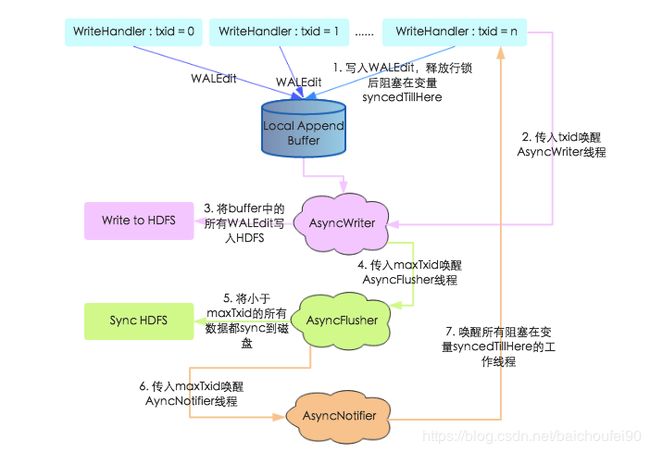
新写入模型采取了多线程模式独立完成写HDFS、HDFS fsync,避免了之前多工作线程恶性抢占锁的问题。并引入一个Notify线程通知WriteHandler线程是否已经fsync成功,可消除旧模型中的锁竞争。
同时,工作线程在将WALEdit写入本地Buffer之后并没有马上阻塞,而是释放行锁之后阻塞等待WALEdit落盘,这样可以尽可能地避免行锁竞争,提高写入性能。
关于此过程详细可参考网易范欣欣-HBase - 数据写入流程解析
7 HBase数据结构
7.1 概述
B树存在的问题:
- 查找
从原理来说,b+树在查询过程中应该是不会慢的,但如果数据插入杂乱无序时(比如插入顺序是5 -> 10000 -> 3 -> 800,类似这样跨度很大的数据),就需要先找到这个数据应该被插入的位置然后再插入数据。这个查找过程如果非常离散,且随着新数据的插入,叶子节点会逐渐分裂成多个节点,逻辑上连续的叶子节点在物理上往往已经不再不连续,甚至分离的很远。就意味着每次查找的时候,所在的叶子节点都不在内存中。这时候就必须使用磁盘寻道时间来进行查找了,相当于是随机IO了。
- 写入
且B+树的更新基本与插入是相同的,也会有这样的情况。且还会有写数据时的磁盘IO。
总的来说,B树随机IO会造成低效的磁盘寻道,严重影响性能。
7.2 LSM树简介
可参考LSM树
7.3 LSM树在HBase的应用
HFile格式基于Bigtable论文中SSTable。
7.3.1 写入
- 先写入WAL的HBase实现 -> HLog,方式是顺序磁盘追加
- 然后写入对应列簇的Store中的MemStore
- MemStore大小达到阈值后会被刷入磁盘成为StoreFile。注意此文件内部是根据
RowKey, Version, Column排序,但多个StoreFile之间在合并前是无序的。
- HBase会定时把这些小的StoreFile合并为大StoreFile(B+树),减少读取开销(类似于LSM中的树合并)
7.3.2 读取
- 先搜索内存小树即MemStore,
- 不存在就到StoreFile中寻找
7.3.3 读取优化
- 布隆过滤器。
可快速得到是否数据不在该集合,但不能100%肯定数据在这个集合,即所谓假阳性。
- 合并
合并后,就不用再遍历繁多的小树了,直接找大树
7.3.4 删除
添加标记,称为墓碑。
在Major Compact中被删除的数据和此墓碑标记才会被真正删除。
7.3.5 合并
HBase Compact过程,就是RegionServer定期将多个小StoreFile合并为大StoreFile,也就是LSM小树合并为大树。这个操作的目的是增加读的性能,否则搜索时要读取多个文件。
HBase中合并有两种:
- Minor Compact
仅合并少量的小HFile
- Major Compact
合并一个Region上的所有HFile,此时会删除那些无效的数据(更新时,老的数据就无效了,最新的那个就被保留;被删除的数据,将墓碑和旧的都删掉)。很多小树会合并为一棵大树,大大提升度性能。
7.3.4 LSM与B+树
RDBMS使用B+树,需要大量随机读写;
而LSM树使用WALog和Memstore将随机写操作转为顺序写。
8 HBase事务
可参考数据库事务系列-HBase行级事务模型
8.1 ACID
HBase和RDBMS类似,也提供了事务的概念,只不过HBase的事务是行级事务,可以保证行级数据的ACID性质。
8.1.1 A-原子性
- 针对同一行(就算是跨列)的所有修改操作具有原子性,所有put操作要么全成功要么全失败。
- HBase有类似CAS的操作:
boolean checkAndPut(byte[] row, byte[] family, byte[] qualifier,
byte[] value, Put put) throws IOException;
- 原子性的原理
因为写入时MemSotre中异常容易回滚,所以原子性的关键在于WAL。而前面提到过WAL原子性保证原理
8.1.2 C/I-一致性/隔离性
-
一致性概述
- Get一致性
查询得到的所有行都是某个时间点的完整行。
- Scan一致性
- scan不是表的一致性视图,但返回结果中的每一行是一致性的视图(该行数据同一时间的版本)
- scan结果总是能反映scan开始时的数据版本(包括肯定反映之前的数据修改后状态和可能反映在scanner构建中的数据修改状态)
以上的时间不是cell中的时间戳,而是事务提交时间。
-
隔离性-读提交
当构建StoreFileScanner后,会自动关联一个MultiVersionConcurrencyControl Read Point,他是当前的MemStore版本,scan操作只能读到这个点之前的数据。ReadPoint之后的更改会被过滤掉,不能被搜索到。
这类事务隔离保证在RDBMS中称为读提交(RC)
-
不保证任何 Region 之间事务一致性
注意:由于 HBase 不保证任何 Region 之间(每个 Region 只保存在一个 Region Server 上)的一致性,故 MVCC 的数据结果只需保存在每个 RegionServer 各自的内存中。
当一台 RegionServer 挂掉,如果 WAL 已经完整写入,所有执行中的事务可以重放日志以恢复,如果 WAL 未写完,则未完成的事务会丢掉(相关的数据也丢失了)
8.1.3 V-可见性
当没有使用writeBuffer时,客户端提交修改请求并收到成功响应时,该修改立即对其他客户端可见。原因是行级事务。
HBase读数据时的scanner有一个Readpoint,该取值是写数据线程写入WriteNumber到KeyValue并提交事务后更新的。scan结果中会滤掉所有大于该 ReadPoint 的 KeyValues。
当一个 KeyValue 的 memstore timestamp(WriteNumber) 比最老的scanner(实际是 scanner 持有的 ReadPoint)还要老时,会被清零(置为0),这样该 KeyValue会对所有的 scanner 可见,当然,此时比该 KeyValue 原 memstore timestamp 更早的 scanner 都已经结束了。
8.1.4 D-持久性
所有可见数据也是持久化的数据。也就是说,每次读请求不会返回没有持久化的数据(注意,这里指hflush而不是fsync到磁盘)。
而那些返回成功的操作,就已经是持久化了;返回失败的,当然就不会持久化。
8.1.5 可调性
HBase默认要求上述性质,但可根据实际场景调整,比如修改持久性为定时刷盘。
关于ACID更多内容,请参阅HBase-acid-semantics和ACID in HBase
8.2 事务原理
可参考:
- 网易范欣欣-数据库事务系列-HBase行级事务模型
8.2.1 简介
HBase支持单行ACID性质,但在HBASE-3584新增了对多操作事务支持,还在HBASE-5229新增了对跨行事务的支持。HBase所有事务都是串行提交的。
为了实现事务特性,HBase采用了各种并发控制策略,包括各种锁机制、MVCC机制等,但没有实现混合的读写事务。
8.2.2 行级锁CountDownLatch
HBase采用CountDownLatch行锁实现更新的原子性,要么全部更新成功,要么失败。
所有对HBase行级数据的更新操作,都需要首先获取该行的行锁,并且在更新完成之后释放,等待其他线程获取。因此,HBase中对多线程同一行数据的更新操作都是串行操作。
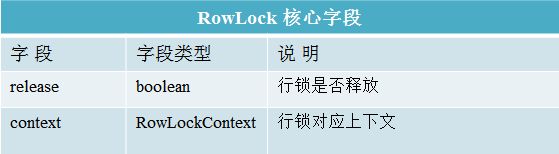
行锁主要相关类为RowLock和RowLockContext:
RowLockContext存储行锁内容包括持锁线程、被锁对象以及可以实现互斥锁的CountDownLatch对象等
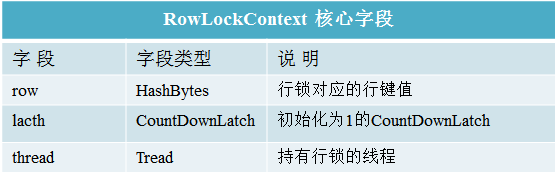
- RowLock包含表征行锁是否已经释放的release字段以及一个RowLockContext对象。
行锁加锁流程:
- 使用rowkey以及自身Thread对象生成RowLockContext对象,此时共享的CountDownLatch对象初始化计数为1
- 将rowkey作为key,RowLockContext对象作为value,
putIfAbsert到全局map lockedRows中,会返回一个existingContext对象,有三种情况:
- null
表示该行锁没有被其他线程持有,可用刚刚创建的RowLockContext来持有该锁,其他线程必然插入失败。
- 本线程创建的RowLockContext
直接使用该RowLockContext对象持有该锁即可。批量更新时可能对某一行数据多次更新,需要多次尝试持有该行数据的行锁。这也被称为可重入锁的情况。
- 其他线程创建的RowLockContext
则该线程会调用latch.await方法阻塞在此RowLockContext对象上,直至该行锁被释放或者阻塞超时。待行锁释放,该线程会重新竞争该锁,一旦竞争成功就持有该行锁,否则继续阻塞。而如果阻塞超时,就会抛出异常,不会再去竞争该锁。
释放流程
在线程更新完成操作之后,必须在finally方法中执行行锁释放rowLock.release()方法,其主要逻辑为:
- 从全局map中将该row对应的RowLockContext移除
- 调用latch.countDown()方法,唤醒其他阻塞在await上等待该行锁的线程
CountDownLatch在加锁时的应用
8.2.3 读写锁ReentrantReadWriteLock
另一种是基于ReentrantReadWriteLock实现的读写锁,该锁可以给临界资源加上read-lock或者write-lock。其中read-lock允许并发的读取操作,而write-lock是完全的互斥操作。HBase利用读写锁实现了Store级别、Region级别的数据一致性
-
Region更新读写锁
HBase在执行数据更新操作之前都会加一把Region级别的读锁(共享锁),所有更新操作线程之间不会相互阻塞;然而,HBase在将memstore数据落盘时会加一把Region级别的写锁(独占锁)。因此,在memstore数据落盘时,数据更新操作线程(Put操作、Append操作、Delete操作)都会阻塞等待至该写锁释放。
-
Region Close保护锁
HBase在执行close操作以及split操作时会首先加一把Region级别的写锁(独占锁),阻塞对region的其他操作,比如compact操作、flush操作以及其他更新操作,这些操作都会持有一把读锁(共享锁)
-
Store snapshot保护锁
HBase在执行flush memstore的过程中首先会基于memstore做snapshot,这个阶段会加一把store级别的写锁(独占锁),用以阻塞其他线程对该memstore的各种更新操作;清除snapshot时也相同,会加一把写锁阻塞其他对该memstore的更新操作。
8.2.4 MVCC
8.2.4.1 概述
HBase还提供了MVCC机制实现数据的读写并发控制。
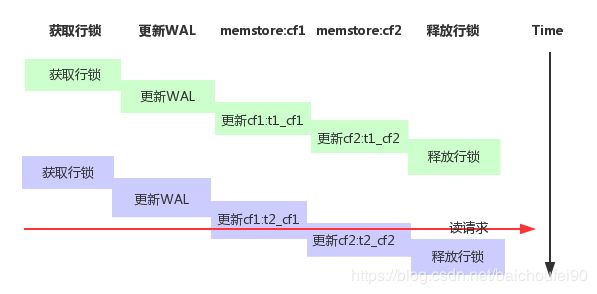
上图中的写行锁机制,如果在第二次更新时读到更新列族1cf1:t2_cf1同时读到列族2cf2:t1_cf2,这就产生了行数据不一致的情况。但如果想直接采用读写线程公用行锁来解决此问题,会产生严重性能问题。
HBase采用了一种MVCC思想,每个RegionServer维护一个严格单调递增的事务号:
- 当写入事务(一组
PUT或DELETE命令)开始时,它将检索下一个最高的事务编号。这称为WriteNumber。每个新建的KeyValue都会包括这个WriteNumber,又称为Memstore timestamp,注意他和KeyValue的timestamp属性不同。
- 当读取事务(一次
SCAN或GET)启动时,它将检索上次提交的事务的事务编号。这称为ReadPoint。
因为HBase事务不能跨Region,所以这些MVCC信息就分别保存在RegionServer内存中。
8.2.4.2 事务写流程
具体来说,MVCC思想优化后的写流程如下:
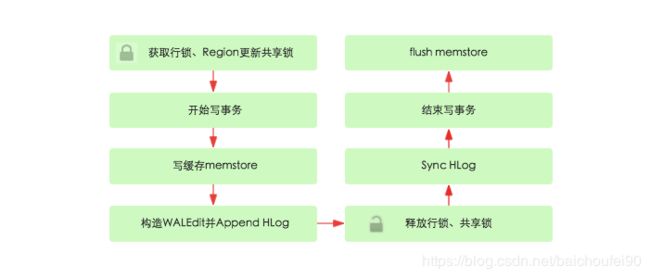
上图是服务端接收到写请求后的写事务流程:
- 锁定行(或多行),事务开始。行锁可保证行级事务原子性。
- 开始写事务,检索当前的
WriteNumber
- 将更新应用于WAL。当RS突然崩溃时且事务已经写入WAL,那就会在其他RS节点上重放。
- 将更新应用于Memstore,具体来说是把获取到的
WriteNumber附加到KeyValue
- 提交该事务。随后,
ReadPoint(即读线程能看到的WriteNumber)就能前移,从而检索到该新的事务编号,使得scan和get能获取到最新数据
- 释放行锁。选择这个时间释放行锁的原因是可尽量减少持有互斥的行级写锁时间,提升写性能。
- SyncHLog。此时如果Sync操作失败,会对写入Memstore内的数据进行移除,即回滚。
- 如果上一步提交,则flush memstore
8.2.4.3 事务读流程
- 打开
scanner
- 获取的当前
ReadPoint。ReadPoint的值是所有的写操作完成序号中的最大整数
- scan时,过滤掉那些
WriteNumber(Memstore timestamp) 大于 ReadPoint的 KeyValue
- scan完毕,返回结果 。一次读操作的结果就是读取点对应的所有cell值的集合
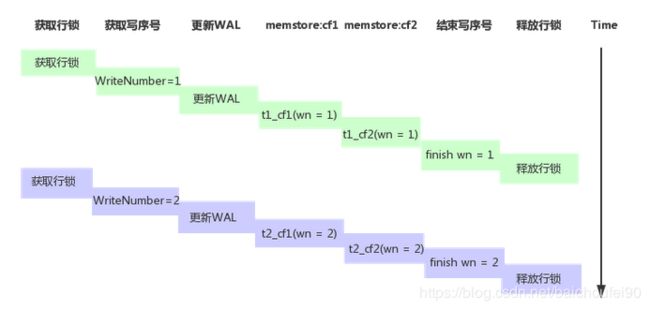
例子: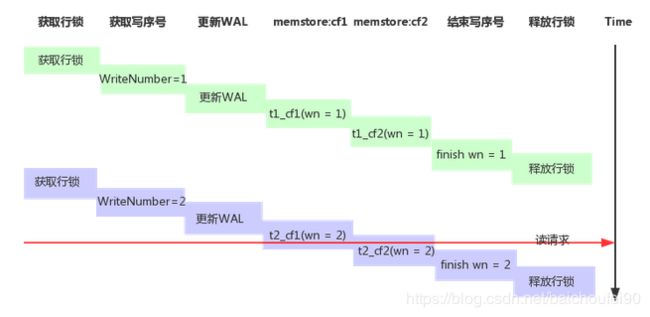
如上图所示,第一次更新获取的写序号为1,第二次更新获取的写序号为2。读请求进来时写操作完成序号中的最大整数为wn(WriteNumber) = 1,因此对应的读取点为wn = 1,读取的结果为wn = 1所对应的所有cell值集合,即为第一次更新锁写入的t1_cf1和t1_cf2,这样就可以实现以无锁的方式读取到行一致的数据。
更多详细讨论可见HBase之七:事务和并发控制机制原理
8.3 隔离性+锁实现
8.3.1 写写并发
- 写时先获取行锁
CountDownLatch
- 获取到锁的执行写操作
- 没获取到的自旋重试等待
- 写操作完成后,释放锁
- 其他等待锁的写入者竞争锁
8.3.3 批量写写并发
- 写入前统一获取所有行的行锁,获取到才进行操作。
- 执行写操作
- 完成后统一释放所有行锁,避免死锁。
8.3.3 读写并发
-
读写并发控制原因
如果不进行控制,可能读到写了一半的数据,比如a列是上个事务写入的数据,b列又是下一个事务写入的数据,这就出大问题了。
-
实现思想
读写并发采用MVCC思想,每个RegionServer维护一个严格单调递增的事务号。
- 当写入事务(一组
PUT或DELETE命令)开始时,它将检索下一个最高的事务编号。这称为WriteNumber。
- 当读取事务(一次
SCAN或GET)启动时,它将检索上次提交的事务的事务编号。这称为ReadPoint。
-
原理
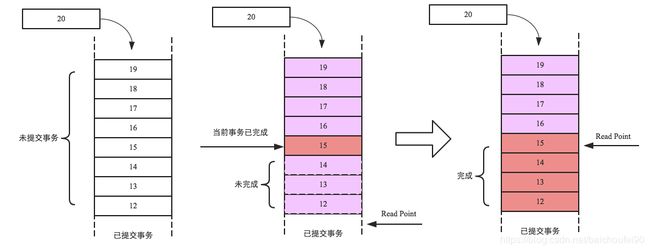
写事务会加入到Region级别的自增序列即sequenceId并添加到队列。当sequenceId更大的事务已提交但较小的事务未提交时,更大的事务也必须等待,对读请求不可见。例子如下图:
8.4 scan和合并
当scan时遇到合并正在进行,HBase处理方案如下:
- 跟踪
scanner使用的最早的ReadPoint,不返回Memstore timestamp大于该ReadPoint的那些KeyValue。
- 该
Memstore timestamp删除的时机就是当它比最早的那个scanner还早时,因为这个时候所有scanner都能获取该数据。
8.5 第三方实现
通过集成Tephra,Phoenix可以支持ACID特性。Tephra也是Apache的一个项目,是事务管理器,它在像HBase这样的分布式数据存储上提供全局一致事务。HBase本身在行层次和区层次上支持强一致性,Tephra额外提供交叉区、交叉表的一致性来支持可扩展性、一致性。
9 HBase协处理器
可参考官方博客-coprocessor_introduction
9.1 简介
协处理器可让我们在RegionServer服务端运行用户代码,实现类似RDBMS的触发器、存储过程等功能。
9.2 风险
- 运行在协处理器上的代码能直接访问数据,所以存在数据损坏、中间人攻击或其他恶意数据访问的风险。
- 当前没有资源隔离机制,所以一个初衷良好的协处理器可能实际上会影响集群性能和稳定性。
9.3 使用场景
在一般情况下,我们使用Get或Scan命令,加上Filter,从HBase获取数据然后进行计算。这样的场景在小数据规模(如几千行)和若干列时性能表现尚好。然而当行数扩大到十亿行、百万列时,网络传输如此庞大的数据会使得网络很快成为瓶颈,而客户端也必须拥有强大的性能、足够的内存来处理计算这些海量数据。
在上述海量数据场景,协处理器可能发挥巨大作用:用户可将计算逻辑代码放到协处理器中在RegionServer上运行,甚至可以和目标数据在相同节点。计算完成后,再返回结果给客户端。
9.4 类比
9.4.1 触发器和存储过程
-
Observer协处理器
它类似RDBMS的触发器,可以在指定事件(如Get或Put)发生前后执行用户代码,不需要客户端代码。
-
Endpoint协处理器
它类似RDBMS的存储过程,也就是说可以在RegionServer上执行数据计算任务。Endpoint需要通过protocl来定义接口实现客户端代码进行rpc通信,以此来进行数据的搜集归并。
具体来说,在各个region上并行执行的Endpoint代码类似于MR中的mapper任务,会将结果返回给Client。Client负责最终的聚合,算出整个表的指标,类似MR中的Reduce。
9.4.2 MR任务
MR任务思想就是将计算过程放到数据节点,提高效率。思想和Endpoint协处理器相同。
9.4.3 AOP
将协处理看做通过拦截请求然后运行某些自定义代码来应用advice,然后将请求传递到其最终目标(甚至更改目标)。
9.4.4 过滤器
过滤器也是将计算逻辑移到RS上,但设计目标不太相同。
9.5 协处理器的实现
9.5.1 概览
- 实现某个协处理器接口,如
Coprocessor(协处理器祖先接口), RegionObserver(Observer), CoprocessorService(Endpoint)
- 配置文件静态方式或动态加载协处理器
- 通过客户端代码调用协处理器,由HBase处理协处理器执行逻辑
9.6 协处理器分类
9.6.1 Observer
9.6.1.1 简介
-
类似RDBMS的触发器,可以在指定事件(如Get或Put)发生前(preGet)后(postGet)执行用户代码。
-
具体执行调用过程由HBase管理,对用户透明。
-
一般来说Observer协处理器又分为以下几种:
- RegionObserver
可观察Region级别的如Get等各类操作事件
- RegionServerObserver
可观察RegionServer级别的如开启、停止、合并、提交、回滚等事件
- MasterObserver
可观察Master的如表创建/删除、schema修改等事件
- WalObserver
可观察WAL相关事件
9.6.1.2 应用
- 权限验证
可以在preGet或prePost中执行权限验证。
- 外键
利用prePut,在插入某个表前插入一条记录到另一张表
- 二级索引
详见HBase Secondary Indexing,可看后文二级索引
9.6.2 Endpoint
9.6.2.1 简介
-
可在数据位置执行计算。
-
具体执行调用过程必须继承通过客户端实现CoprocessorService接口的方法,显示进行代码调用实现。
-
Endpoint通过protobuf实现
-
Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些 Endpoint 协处理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常见的用法就是进行聚集操作。
-
如果没有协处理器,当用户需要找出一张表中的最大数据,即 max 聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到 Client 端统一执行,势必效率低下。
利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出,仅仅将该 max 值返回给客户端。在客户端进一步将多个 Region 的最大值进一步处理而找到其中的最大值。这样整体的执行效率就会提高很多。
9.6.2.2 应用
- 在一个拥有数百个Region的表上求均值或求和
9.7 加载方法
9.7.1 静态加载(系统级全局协处理器)
- 加载
-
hbase-site.xml中配置一个SumEndPoint:
hbase.coprocessor.region.classes
org.myname.hbase.coprocessor.endpoint.SumEndPoint
-
HBase在服务端用默认的ClassLoader加载上述配置的协处理器,所以说我们必须将协处理器和相关依赖代码打成jar后要放到RegionServer上的classpath才能运行。
-
这种方式加载的协处理器对所有表的所有Region可用,所以可称为system Coprocessor。
-
列表中首个协处理器拥有最高优先级,后序的优先级数值依次递增。注意,优先级数值越高优先级越低。调用协处理器时,HBase会按优先级顺序调用回调方法。
-
重启HBase即可
- 卸载
- 从
hbase-site.xml中去掉协处理器配置
- 重启HBase
- 按需从HBase lib目录删除不用的协处理器 JAR文件
9.7.2 动态加载(表级协处理器)
该种方式加载的协处理器只能对加载了的表有效。加载协处理器时,表必须离线。
动态加载,需要先将包含协处理器和所有依赖打包成jar,比如coprocessor.jar,放在了HDFS的某个位置(也可放在每个RegionServer的本地磁盘,但是显然很麻烦)。
然后加载方式有以下三种:
-
HBase Shell
-
将需要加载协处理器的表离线禁用:
hbase> disable 'users'
-
加载协处理器:
下面各个参数用|分隔。其中1073741823代表优先级;arg1=1,arg2=2代表协处理器参数,可选。
hbase alter 'users',
METHOD => 'table_att',
'Coprocessor'=>'hdfs://:/user//coprocessor.jar| org.myname.hbase.Coprocessor.RegionObserverExample|1073741823|arg1=1,arg2=2'
-
恢复表可用
hbase(main):003:0> enable 'users'
-
验证协处理器可用性
hbase(main):04:0> describe 'users'
可以在user表的TABLE_ATTRIBUTES属性中看到已加载的协处理器。
-
Java API
TableName tableName = TableName.valueOf("users");
Path path = new Path("hdfs://:/user//coprocessor.jar");
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
admin.disableTable(tableName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
hTableDescriptor.addCoprocessor(RegionObserverExample.class.getCanonicalName(), path,
Coprocessor.PRIORITY_USER, null);
admin.modifyTable(tableName, hTableDescriptor);
admin.enableTable(tableName);
-
动态卸载
-
HBase Shell
-
将需要加载协处理器的表离线禁用:
hbase> disable 'users'
-
移除协处理器:
alter 'users', METHOD => 'table_att_unset', NAME => 'coprocessor$1'
-
恢复表可用
hbase(main):003:0> enable 'users'
-
Java API
TableName tableName = TableName.valueOf("users");
String path = "hdfs://:/user//coprocessor.jar";
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
admin.disableTable(tableName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
// columnFamily2.removeCoprocessor()
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
admin.modifyTable(tableName, hTableDescriptor);
admin.enableTable(tableName);
9.8 代码例子
9.8.1 背景
官方文档例子。
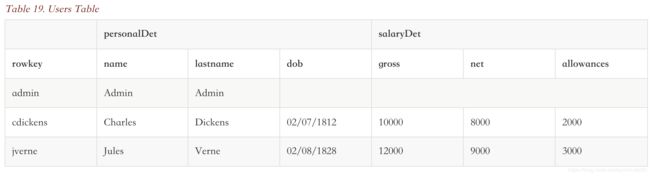
一个users表,拥有两个列族personalDet(用户详情) 和 salaryDet(薪水详情)
9.8.2 Observer例子
该协处理器能阻止在对users表的Get或Scan操作中返回用户admin的详情信息:
- 实现
RegionObserver接口方法preGetOp(),在该方法中加入代码判断客户端查询的值是admin。如果是,就返回错误提示,否则就返回查询结果:
public class RegionObserverExample implements RegionObserver {
private static final byte[] ADMIN = Bytes.toBytes("admin");
private static final byte[] COLUMN_FAMILY = Bytes.toBytes("details");
private static final byte[] COLUMN = Bytes.toBytes("Admin_det");
private static final byte[] VALUE = Bytes.toBytes("You can't see Admin details");
@Override
public void preGetOp(final ObserverContext e, final Get get, final List results)
throws IOException {
if (Bytes.equals(get.getRow(),ADMIN)) {
Cell c = CellUtil.createCell(get.getRow(),COLUMN_FAMILY, COLUMN,
System.currentTimeMillis(), (byte)4, VALUE);
results.add(c);
e.bypass();
}
}
@Override
public RegionScanner preScannerOpen(final ObserverContext e, final Scan scan,
final RegionScanner s) throws IOException {
// 使用filter从scan中排除ADMIN结果
// 这样的缺点是会覆盖原有的其他filter
Filter filter = new RowFilter(CompareOp.NOT_EQUAL, new BinaryComparator(ADMIN));
scan.setFilter(filter);
return s;
}
@Override
public boolean postScannerNext(final ObserverContext e, final InternalScanner s,
final List results, final int limit, final boolean hasMore) throws IOException {
Result result = null;
Iterator iterator = results.iterator();
while (iterator.hasNext()) {
result = iterator.next();
if (Bytes.equals(result.getRow(), ADMIN)) {
// 也可以通过postScanner方式从结果中移除ADMIN
iterator.remove();
break;
}
}
return hasMore;
}
}
|
- 将协处理器和依赖一起打包为
.jar文件
- 上传该jar文件到HDFS
- 用我们之前提到过的一种方式来加载该协处理器
- 写一个
Get、Scan测试程序来验证
9.8.3 Endpoint例子
该例子实现一个Endpoint协处理器来计算所有职员的薪水之和:
-
以protobuf标准,创建一个描述我们服务的.proto文件:
option java_package = "org.myname.hbase.coprocessor.autogenerated";
option java_outer_classname = "Sum";
option java_generic_services = true;
option java_generate_equals_and_hash = true;
option optimize_for = SPEED;
message SumRequest {
required string family = 1;
required string column = 2;
}
message SumResponse {
required int64 sum = 1 [default = 0];
}
service SumService {
rpc getSum(SumRequest)
returns (SumResponse);
}
-
对以上.proto文件执行protoc命令来生成java代码Sum.java到src目录:
$ mkdir src
$ protoc --java_out=src ./sum.proto
-
Endpoint协处理器代码编写
继承刚才生成的类,并实现Coprocessor和CoprocessorService接口的方法:
public class SumEndPoint extends Sum.SumService implements Coprocessor, CoprocessorService {
private RegionCoprocessorEnvironment env;
@Override
public Service getService() {
return this;
}
@Override
public void start(CoprocessorEnvironment env) throws IOException {
if (env instanceof RegionCoprocessorEnvironment) {
this.env = (RegionCoprocessorEnvironment)env;
} else {
throw new CoprocessorException("Must be loaded on a table region!");
}
}
@Override
public void stop(CoprocessorEnvironment env) throws IOException {
// do nothing
}
@Override
public void getSum(RpcController controller, Sum.SumRequest request, RpcCallback done) {
Scan scan = new Scan();
// 列族
scan.addFamily(Bytes.toBytes(request.getFamily()));
// 列
scan.addColumn(Bytes.toBytes(request.getFamily()), Bytes.toBytes(request.getColumn()));
Sum.SumResponse response = null;
InternalScanner scanner = null;
try {
scanner = env.getRegion().getScanner(scan);
List| results = new ArrayList<>();
boolean hasMore = false;
long sum = 0L;
do {
hasMore = scanner.next(results);
// 按cell(rowkey/列/timestamp)遍历结果
for (Cell cell : results) {
// 累加结果
sum = sum + Bytes.toLong(CellUtil.cloneValue(cell));
}
results.clear();
} while (hasMore);
// 构建带结果的相应
response = Sum.SumResponse.newBuilder().setSum(sum).build();
} catch (IOException ioe) {
ResponseConverter.setControllerException(controller, ioe);
} finally {
if (scanner != null) {
try {
// 用完记得关闭scanner
scanner.close();
} catch (IOException ignored) {}
}
}
// 返回结果
done.run(response);
}
}
|
-
客户端调用代码:
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
TableName tableName = TableName.valueOf("users");
Table table = connection.getTable(tableName);
// 构建 对salaryDet列族 gross列 求和 的rpc请求
final Sum.SumRequest request = Sum.SumRequest.newBuilder().setFamily("salaryDet").setColumn("gross").build();
try {
// 调用Entpoint协处理器方法,得到结果
Map results = table.coprocessorService(
Sum.SumService.class,
null, /* start key */
null, /* end key */
// 回调方法
new Batch.Call() {
@Override
public Long call(Sum.SumService aggregate) throws IOException {
BlockingRpcCallback rpcCallback = new BlockingRpcCallback<>();
// 得到结果
aggregate.getSum(null, request, rpcCallback);
Sum.SumResponse response = rpcCallback.get();
return response.hasSum() ? response.getSum() : 0L;
}
}
);
// 遍历打印结果
for (Long sum : results.values()) {
System.out.println("Sum = " + sum);
}
} catch (ServiceException e) {
e.printStackTrace();
} catch (Throwable e) {
e.printStackTrace();
}
-
加载Endpoint协处理器
-
执行上述客户端代码,进行测试
9.8.3 HBase同步数据到ES
- 使用Hbase协作器(Coprocessor)同步数据到ElasticSearch
- 通过HBase Observer同步数据到ElasticSearch
10 过滤器
可参考Apache HBase Filter
过滤器使用不当会造成性能下降,必须经过严格测试才能投入生产环境。
过滤器可按RowKey/CF/Column/Timestamp等过滤数据,他们在于Scan/Get等配合使用时可直接在服务端就过滤掉不需要的数据,大大减少传回客户端的数据量。
11 HBase网络和线程模型
12 HBase实践
12.1 API
可参考
- HBase基本操作-java api
- HBase Java API
12.1.1 scan
按指定条件获取范围数据
-
scan时会综合StoreFile和MemStore scanner扫描结果。当构建scanner时,会关联一个MultiVersionConcurrencyControl Read Point,只能读到这个点之前的数据。ReadPoint之后的更改会被过滤掉,不能被搜索到。
-
注意点
- scan可以通过
setCaching, setBatch, setMaxResultSize等方法以空间换时间的思想来提高效率;
- setCaching => .setNumberOfRowsFetchSize (客户端每次 rpc fetch 的行数,默认Integer.MAX_VALUE)
- setMaxResultSize => .setMaxResultByteSize (客户端缓存的最大字节数,默认2MB)
- setBatch => .setColumnsChunkSize (客户端每次获取的列数,默认-1代表所有列)
详细说明可以参考这篇:文章
- scan可以通过setStartRow与setEndRow来限定范围([start,end)start是闭区间,end是开区间)。范围越小,性能越高。
通过巧妙的RowKey设计使我们批量获取记录集合中的元素挨在一起(应该在同一个Region下),可以在遍历结果时获得很好的性能。
- scan可以通过setFilter方法添加过滤器,这也是分页、多条件查询的基础(但BloomFilter不适用于Scan)。
- ResultScanner使用完后必须关闭
- 频繁访问的行可
setCacheBlocks开启块缓存
12.1.2 get
传入rowkey得到最新version数据或指定maxversion得到指定版本数据。除了查单一RowKey,也可以在构造 Get 对象的时候传入一个 rowkey 列表,这样一次 RPC 请求可以返回多条数据。
- 注意点
1.Bloom Filter(以下简称BF)
- 有助于减小读取时间。
- HBase中实现了一个轻量级的内存BF结构,可以使得Get操作时从磁盘只读取可能包含目标Row的StoreFile。
- BF本身存储在每个HFile的元数据中,永远不需要更新。当因为Region部署到RegionServer而打开HFile时,BF将加载到内存中。
- 默认开启行级BF,可根据数据特征修改如 行+列级
- 衡量BF开启后影响是否为证明,可以看RS的
blockCacheHitRatio(BlockCache命中率)指标是否增大,增大代表正面影响。
- 需要在删除时重建,因此不适合具有大量删除的场景。
- BF分为行模式和行-列模式,在大量列级PUT时就用行列模式,其他时候用行模式即可。
12.1.3 put
放入一行数据.
注意点:
- 该过程会先把put放入本地put缓存writeBuffer,达到阈值后再提交到服务器。
- 批量导入
批量导入是最有效率的HBase数据导入方式。
- 海量数据写入前预拆分Region,避免后序自动Split过程阻塞数据导入
- 当对安全性要求没那么高时可以使用WAL异步刷新写入方式。甚至在某些场景下可以禁用WAL
12.1.4 delete
删除指定数据
12.1.5 append
在指定RowKey数据后追加数据
12.1.6 increment
可参考HBase Increment(计数器)简介及性能测试
在RegionServer端原子性的对某个Value数值加或减,而不是加锁的Read-Modify-Write。可作为计数器使用。
12.2 HBase Shell
进入到HBase RS机器的$HBASE_HOME/bin目录后,使用hbase shell命令启动 shell客户端即可。
12.3 二级索引
12.3.1 基本思路
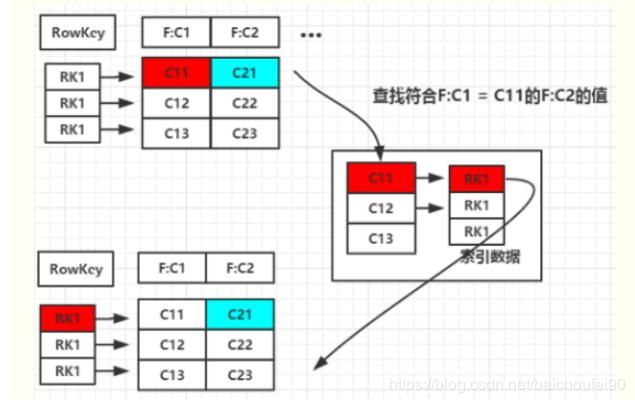
如上图,单独建立一个HBase表,存F:C1列到RowKey的索引。
那么,当要查找满足F:C1=C11的F:C2列数据,就可以去索引表找到F:C1=C11对应的RowKey,再回原表查找该行的F:C2数据。
12.3.2 协处理器的实现方案
用RegionObserver的prePut在每次写入主表数据时,写一条到索引表,即可建立二级索引。
12.4 Schema设计
更多例子可以看http://hbase.apache.org/book.html#schema.casestudies
12.4.1 列族
- 列族数量越少越好
HBase程序目前不能很好的支持超过2-3个列族。而且当前版本HBase的flush和合并操作都是以Region为最小单位,也就是说列族之间会互相影响(比如大负载列族需要flush时,小负载列族必须进行不必要的flush操作导致IO)。
- 列族多的坏处
当一个表存在多个列族,且基数差距很大时,如A_CF100万行,B_CF10亿行。此时因为HBase按Region水平拆分,会导致A因列族B的数据量庞大而随之被拆分到很多的region,导致访问A列族就需要大量scan操作,效率变低。
- 总的来说最好是设计一个列族就够了,因为一般查询请求也只访问某个列族。
- 列族名不宜过长
列族名尽量简短甚至不需自描述,因为每个KeyValue都会包含列族名,总空间会因为列族名更长而更大,是全局影响。
- BlockSize
每个列族可配BlockSize(默认64KB)。当cell较大时需加大此配置。且该值和StoreFile的索引文件大小成反比。
- 内存列族
可在内存中定义列族,数据还是会被持久化到磁盘,但这类列族在BlockCache中拥有最高优先级。
12.4.2 Region
- 一个Region的大小一般不超过50GB。
- 一个有1或2个列族的表最佳Region总数为50-100个
12.4.3 RowKey设计
- 避免设计连续RowKey导致数据热点,导致过载而请求响应过慢或无法响应,甚至影响热点Region所在RS的其他Region。如果Rowkey是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个Regionserver实现负载均衡的几率。常用措施如下:
-
Salting-加盐
按期望放置的RS数量设计若干随机前缀,在每个RowKey前随机添加,以将新数据均匀分散到集群中,负载均衡。
foo0001
foo0002
foo0003
foo0004
a-foo0003
b-foo0001
c-foo0003
c-foo0004
d-foo0002
优缺点:Salting可增加写的吞吐量,但会降低读效率,因为有随机前缀,Scan和Get操作都受影响。
-
Hash算法
用固定的hash算法,对每个key求前缀,然后取hash后的部分字符串和原来的rowkey进行拼接。查询时,也用这个算法先把原始RowKey进行转换后再输入到HBase进行查询。

优缺点:可以一定程度上打散整个数据集,但是不利于scan操作,由于不同数据的hash值有可能相同,所以在实际应用中,一般会使用md5计算,然后截取前几位的字符串.
examples: substring(MD5(设备ID),0,x) + 设备的ID,其中(x一般会取5到6位.)
-
逆置Key
将固定长度或范围的前N个字符逆序。打乱了RowKey,但会牺牲排序性。

-
业务必须用时间序列或连续递增数字时,可以在开头加如type这类的前缀使得分布均匀。
- 定位cell时,需要表名、RowKey、列族、列名和时间戳。而且StoreFile(HFile)有索引,cell过大会导致索引过大(使用时会放入内存)。所以需要设计schema时:
- 列族名尽量简短,甚至只用一个字符;
- 列名尽量简短:
- RowKey保证唯一性,长度可读、简短,尽量使用数字。
- 版本号采用倒序的时间戳,这样可以快速返回最新版本数据
- 同一行不同列族可以拥有同样的RowKey
- RowKey具有不可变性
- RowKey长度
Rowkey是一个二进制码流,Rowkey的长度被很多开发者建议说设计在10~100个字节,不过建议是越短越好,不要超过16个字节,原因如下:
- 数据的持久化文件HFile中是按照KeyValue存储的,如果Rowkey过长如100个字节,1000万列数据光Rowkey就要占用100*1000万=10亿个字节,近1G数据,这会极大影响HFile的存储效率;
- MemStore将缓存部分数据到内存,如果Rowkey字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。因此Rowkey的字节长度越短越好。
- 操作系统大多64位,内存8字节对齐,控制在16个字节即8字节整数倍利用可利用OS最佳特性。
12.4.4 Versions
指定一个RowKey数据的最大保存的版本个数,默认为3。越少越好,减小开销。
如果版本过多可能导致compact时OOM。
如果非要使用很多版本,那最好考虑使用不同的行进行数据分离。
12.4.5 压缩
详见http://hbase.apache.org/book.html#compression
注意,压缩技术虽然能减小在数据存到磁盘的大小,但在内存中或网络传输时会膨胀。也就是说,不要妄图通过压缩来掩盖过大的RowKey/列族名/列名的负面影响。
12.4.6 Cell
一个cell不应超过10MB,否则就应该把数据存入HDFS,而只在HBase存指针指向该数据。
12.5 join
- HBase本身不支持join。
- 可以自己写程序比如MR实现。
- Phoenix里面有join函数,但是性能很差,稍不注意会把集群打挂。最好不要用hbase系来做join,这种还是用hive来搞比较好。
13 HBase对比其他技术
13.1 对比HDFS/MR
13.2 对比Cassandra
13.3 对比Kudu
- Kudu很多地方的设计借鉴了HBase思想
- Kudu限制较多
- Kudu顺序写较HBase速度更快,但慢于HDFS;Kudu随机读较HBase慢,但比HDFS快得多。总的来说Kudu是一个折中设计。
- Kudu是真正的列存储,而HBase是列族存储。指定查询某几列时,一般来说Kudu会更快
14 调优
14.1 参考
-
Apache HBase Performance Tuning
-
Scan用法大观园
-
写性能优化策略
-
读性能优化策略
-
聊聊HBase核心配置参数
-
HBase隔离方案实战
-
有赞技术-HBase 读流程解析与优化的最佳实践
-
优化hbase的查询优化-大幅提升读写速率
14.2 操作系统
可参考:
- 用好你的操作系统
调优点:
- 内存
尽量搞大些,HBase很耗内存,比如MemStore/BlockCache等。比如每个RegionServer 拥有TB级磁盘,32GB内存,其中20GB分配给Region,MemStore128MB,其他采用默认配置。
- 使用64位OS和JVM
- 关闭SWAP
vm.swappiness = 0
14.3 GC
可参考:
-
HBase最佳实践-CMS GC调优
调优点:
-
普通内存时用-XX:+UseConcMarkSweepGC,即老年代CMS并发搜集,年轻带使用ParNew并行搜集;
-
大内存时启用G1 GC,针对大内存(>=32GB)优化。
-
Concurrent Mode Failure
调低-XX:CMSInitiatingOccupancyFraction(比如60-70%),否则可能导致老年代占满并发搜集失败触发STW的FullGC。但不能过低,否则会导致过多的GC次数和CPU使用。
-
老年代内存碎片
默认开启了MSLAB来解决此问题。还可以在hbase-env.sh中设置-XX:PretenureSizeThreshold小于hbase.hregion.memstore.mslab.chunksize以使得MSLAB直接在老年代分配内存,这样可以省去在年轻带Survivor区复制成本已经发生MinorGC时复制到老年代成本。
相关配置如下:
- hbase.hregion.memstore.mslab.enabled
默认值true。开启MSLAB来阻止堆内存碎片,减少GC STW频率。
- hbase.hregion.memstore.mslab.chunksize
默认值2097152(2MB)。MSLAB的chunk最大值,单位字节。
- hbase.hregion.memstore.mslab.max.allocation
默认值262144(256KB)。MSLAB中的一次内存搜集最大值,如果超过就直接从JVM 堆中搜集。
- hbase.hregion.memstore.chunkpool.maxsize
默认值为0.0,HBase2.0后为1.0。在整个MemStore 可以占用的堆内存中,chunkPool可占用的最大比例,范围为0.0~1.0。
14.4 HBase参数
可参考Recommended Configurations
14.4.1 hedged对冲读
14.4.2 Region Compact
- 在某些场景中,put会被阻塞在MemStore上,因为太多的小StoreFile文件被反复合并。
- 可在某些重要场景的关闭hbase表的major compact,在非高峰期的时候再手动调用major compact,可以减少split的同时显著提供集群的性能和吞吐量。
14.4.3 MemStoreFlush
Memstore配置适合与否对性能影响很大,频繁的flush会带来额外负载影响读写性能。
可参考Configuring HBase Memstore: What You Should Know
还需要看这里
14.4.4 综合
- hbase.regionserver.handler.count
RS上的RPC 监听器个数,可调为CPU两倍,读很多场景设为CPU数就行了
- hfile.block.cache.size
- Prefetch Option for Blockcache
- hbase.hstore.blockingStoreFiles
blockingStoreFiles
- hbase.hregion.memstore.block.multiplier
- hbase.regionserver.checksum.verify
如果此参数设置为false,则hbase将不验证任何校验和,而是依赖于在HDFS客户端中进行的校验和验证。
- hbase.ipc.server.num.callqueue
14.5 Zookeeper
14.6 Schema设计
14.7 代码优化
14.7.1 Bytes.toBytes
尽量少用Bytes.toBytes,因为在循环或MR任务中,这种重复的转换代价昂贵,应该如下定义:
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Get get = new Get(rowkey);
Result r = table.get(get);
byte[] b = r.getValue(CF, ATTR); // returns current version of value
14.8 写优化
14.8.1 批量数据加载
使用基于MR的BulkLoad相较于HBaseAPI,使用更少的CPU和网络资源。
14.8.2 预分区
14.8.3 WAL优化
在允许的场景,可将WALflush设为异步甚至禁用,坏处是丢数据风险。
可在批量加载数据时禁用WALflush。
14.8.4 防止Region写入热点
14.9 读优化
14.9.1 GC
- HBase最佳实践-CMS GC调优
14.9.2 磁盘
对实时性要求高的使用SSD
14.9.3 HFile Compact
- 关闭自动Marjor Compact,转为业务低峰期手动
- 根据具体场景调整Compact触发阈值/每次Compact文件数量等,减少每次scan时的HFile数,但必须综合考虑
14.9.4 BlockCache缓存
- CombinedBlockCache
即启用BucketCache,所有DataBlock保存在BucketCache,而MetaBlock即Index和BloomFilter块保存在Heap中的 LruBlockCache。
- hfile.block.cache.size
即缓存StoreFile所使用的BlockCache所占Heap的百分比,默认是0.4即40%。但同时要注意BlockCache和MemStore大小的总和所占堆内存比例不能超过80%,因为至少要留20%的内存空间给HBase进行必要的操作。
14.9.5 本地性
RS与DN混合部署,提升数据读写本地性。
14.9.6 对冲读
Hedged Reads(对冲读),是Hadoop 2.4.0 引入的一项HDFS特性。
- 普通的每个HDFS读请求都对应一个线程
- 对冲读开启后,如果读取未返回,则客户端会针对相同数据的不同HDFS Block副本生成第二个读请求。
- 使用先返回的任何一个读请求,并丢弃另一个。
- 可通过
hedgedReadOps(已触发对冲读取线程的次数。 这可能表明读取请求通常很慢,或者对冲读取的触发过快) 和 hedgeReadOpsWin(对冲读取线程比原始线程快的次数。 这可能表示给定的RegionServer在处理请求时遇到问题) 指标评估开启对冲读的效果
- 在追求最大化吞吐量时,开启对冲读可能导致性能下降
- 需要在
hbase-site.xml配置如下内容:
dfs.client.hedged.read.threadpool.size
50
dfs.client.hedged.read.threshold.millis
100
14.9.7 短路读
- 如果不开启,则读取本地DN上的数据时也需要RPC请求使用Socket,层层处理后返回
- 开启短路读后,可以直接由DN打开目标文件和对应校验文件并把文件描述符直接返回,Client收到后可直接打开、读取数据即可
- 配置方式如下:
修改hbase-site.xml文件:
dfs.client.read.shortcircuit
true
This configuration parameter turns on short-circuit local reads.
dfs.domain.socket.path
/home/stack/sockets/short_circuit_read_socket_PORT
Optional. This is a path to a UNIX domain socket that will be used for
communication between the DataNode and local HDFS clients.
If the string "_PORT" is present in this path, it will be replaced by the
TCP port of the DataNode.
14.9.8 高可用读
为了防止RS挂掉时带来的其上Region不可用及恢复的时间空档,可使用HBase Replication:
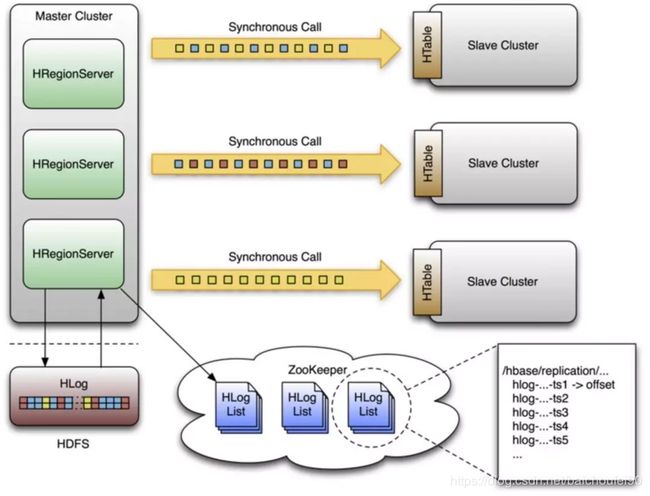
注意,该方式因为需要数据同步所以备集群肯定会有一定延迟。
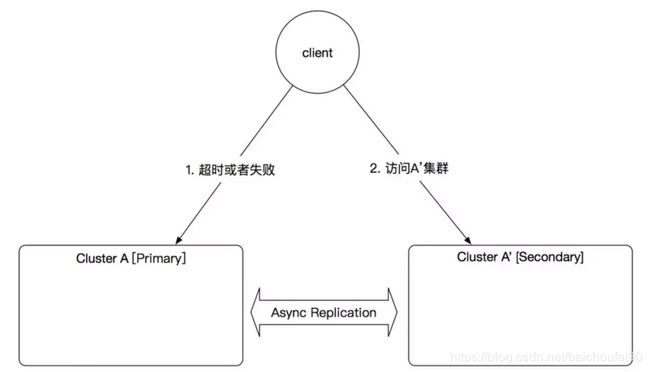
14.9.9 scan只选择要读的列
Scan时建议指定需要的Column Family,减少通信量,否则scan操作默认会返回整个row的所有CF/Column的数据.
Scan s = new Scan();
// 选择列族进行Scan
s.addFamily(Bytes.toBytes("cf1"));
// 选择列族/列进行scan
s.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("c1"));
// 仅检索列族cf下的c1列和c2列
Map> familyMap = new HashMap<>();
NavigableSet cs = new TreeSet();
cs.add("c1");
cs.add("c2");
familyMap.put(Bytes.toBytes("cf1"), cs);
s.setFamilyMap(familyMap);
14.9.10 记得关闭资源
使用完后,关闭Connection/Table/ResultScanner,特别是不关闭ResultScanner可能导致RegionServer出现性能问题,所以最好是把他放在try中:
Scan scan = new Scan();
// set attrs...
ResultScanner rs = table.getScanner(scan);
try {
for (Result r = rs.next(); r != null; r = rs.next()) {
// process result...
} finally {
rs.close(); // always close the ResultScanner!
}
table.close();
14.9.11 合理使用Filter
14.9.12 合理使用BloomFilter
按需调整BloomFilter,默认是Row模式
14.10 HBase删除优化
- 切记删除的原理是写入一个墓碑,会有写入开销和读数据时开销
- 批量删除
每个Table.delete(Delete)就会有一个RPC请求发送到RS,而不能利用writerBuffer,所以大量删除时请使用Table.delete(List)
14.11 HDFS
- 数据本地性
- 短路读
15 Phoenix on HBase
关于Phoenix on HBase,即Sql化的HBase服务,可以参考Phoenix学习
常见问题
1 为什么HBase查询速度快
- 首先是可以从
hbase:meta快速的定位到Region,而且优先MemStore(SkipList跳表)查询,因为HBase的写入特性所以MemStore如果找到符合要求的肯定就是最新的直接返回即可。
如果找不到还能通过BloomFilter/DataBlock索引等高效的从BlockCache查找,
还是没有的话就相对快速的从已按RowKey升序排序的HFile中查找。
2. 列式存储,如果查找的列在某个列族,只需查找定位Region的某一个Store即可
3. 可使用丰富的过滤器来加快Scan速度。
4. 后台会定期拆分Region,将大的Region分布到多个RS;定期合并,将大量小StoreFile合并为一个,同时删除无效信息,减少扫描读取数据量。
2 为什么HBase写入速度快
虽然HBase很多时候是随机写入,但因为引入了内存中的MemStore(由SkipList实现,是多层有序数据结构),批量顺序输入HDFS,所以可先写入将随机写转为了顺序写
3 频繁出现数据无法写入
-
检查RSMemStore内存设置
-
检查hbase.hstore.blockingStoreFiles参数
Flush后如果该Store的StoreFile数量如果超过了hbase.hstore.blockingStoreFiles,则会阻塞该Region的更新写入操作,直到有Compact发生减少了StoreFile数量或等待until hbase.hstore.blockingWaitTime超时,然后继续正常Flush。
-
检查hbase.hregion.memstore.flush.size hbase.hregion.memstore.block.multiplier
当MemStore的数据达到hbase.hregion.memstore.block.multiplier 乘以 hbase.hregion.memstore.flush.size字节时,会阻塞写入,主要是为了防止在update高峰期间MemStore大小失控,造成其flush的文件需要很长时间来compact或split,甚至造成OOM服务直接down掉。内存足够大时,可调大该值。
-
检查hbase.regionserver.global.memstore.size
hbase.regionserver.global.memstore.size设定了一个RS内全部Memstore的总大小阈值,默认大小为Heap的40%,达到阈值以后就会阻塞更新请求,并开始RS级别的MemStore flush。
4 RegionServer挂掉或失联
4.1 问题描述
RS因为长时间FullGC 导致STW,无法及时发送心跳到ZK,所以被ZK标为宕机。此时会Master会注意到该RS节点挂掉,将其上的Region迁移到其他RS节点。待故障RS恢复后,发现自己被标为宕机,所以只能自杀,否则会出现错乱。
4.2 解决方案
- 加大RS节点内存
- 参考gc优化
-
5 部分转自网易范欣欣-HBase原理-数据读取流程解析
5.1 HBase作为列式存储,为什么它的scan性能这么低呢,列式存储不是更有利于scan操作么?Parquet格式也是列式,但它的scan这么优秀,他们的性能差异并不是因为数据组织方式造成的么?谢谢啦
- HBase不完全是列式存储,确切的说是列族式存储,HBase中可以定义一个列族,列族下可以有都个列,这些列的数据是存在一起的。而且通常情况下我们建议列族个数不大于2个,这样的话每个列族下面必然会有很多列。因此HBase并不是列式存储,更有点像行式存储。
- HBase扫描本质上是一个一个的随机读,不能做到像HDFS(Parquet)这样的顺序扫描。试想,1000w数据一条一条get出来,性能必然不会很好。问题就来了,HBase为什么不支持顺序扫描?
因为HBase支持更新操作以及多版本的概念,这个很重要。可以说如果支持更新操作以及多版本的话,扫描性能就不会太好。原理是HBase是一个类LSM数据结构,数据写入之后先写入内存,内存达到一定程度就会形成一个文件,因此HBase的一个列族会有很多文件存在。因为更新以及多版本的原因,一个数据就可能存在于多个文件,所以需要一个文件一个文件查找才能定位出具体数据。
所以HBase架构本身个人认为并不适合做大规模scan,很大规模的scan建议还是用Parquet,可以把HBase定期导出到Parquet来scan
5.2 Kudu也是采用的类LSM数据结构,但是却能达到parquet的扫描速度(kudu是纯列式的),kudu的一个列也会形成很多文件,但是好像并没影响它的性能?
-
kudu性能并没有达到parquet的扫描速度,可以说介于HBase和HDFS(Parquet)之间
-
kudu比HBase扫描性能好,是因为kudu是纯列存,扫描不会出现跳跃读的情况,而HBase可能会跳跃seek,这是本质的区别。
-
但kudu扫描性能又没有Parquet好,就是因为kudu是LSM结构,它扫描的时候还是会同时顺序扫描多个文件,并比较key值大小。
而Parquet只需要顺序对一个Block块中的数据进行扫描即可,这个是两者的重要区别。
所以说hbase相比parquet,这两个方面都是scan的劣势。
好文推荐
综合
- Apache HBase 全攻略
- Hadoop之HBase综述
- HBase中文文档
原理
-
HBase原理-数据读取流程解析
-
总结HBase各种级别的锁以及对读写的阻塞
-
网易范欣欣-HBase – Memstore Flush
-
网易范欣欣-HBase - Compaction的前生今世-身世之旅
-
网易范欣欣-HBase - Compaction的前生今世-改造之路
-
网易范欣欣-HBase - 数据写入流程解析
-
网易范欣欣-HBase原理-数据读取流程解析
-
网易范欣欣-HBase-数据读取流程部分细节
-
网易范欣欣-HBase – Region切分
-
网易范欣欣-HBase BlockCache系列 – 走进BlockCache
-
网易范欣欣-HBase BlockCache系列 - 探求BlockCache实现机制
-
网易范欣欣-HBase – 存储文件HFile结构解析
-
网易范欣欣-HBase – 探索HFile索引机制
-
网易范欣欣-HBase – 分布式系统中snapshot
-
网易范欣欣-数据库事务系列-HBase行级事务模型
-
网易范欣欣-HBase最佳实践-多租户机制简析
-
HBase-拆分&合并
-
HBase原理机制:Region的拆分与合并
索引
- HBase二级索引方案
主要是基于协处理器(Phoenix, 华为-HBase二级索引方案)和非协处理器方案(基于Solr, Elasticsearch)。
调优
- 有赞技术-HBase 读流程解析与优化的最佳实践
- hbase优化之旅(一)探索regionserver参数优化
- hbase优化之旅(二)regionserver的G1 GC优化探索
- (1.3版)hbase优化之旅(三)-regionserver g1 执行细节和参数调优方法论详解
- hbase优化之旅(四)-regionserver从17优化到10台的小结
- 网易范欣欣-HBase最佳实践-CMS GC调优
- 网易范欣欣-HBase最佳实践-内存规划
- 网易范欣欣-HBase最佳实践 – 客户端重试机制
- 网易范欣欣-HBase最佳实践-客户端超时机制
- 网易范欣欣-HBase最佳实践-集群规划
- 网易范欣欣-HBase最佳实践-用好你的操作系统
- 网易范欣欣-HBase最佳实践-列族设计优化
- 网易范欣欣-HBase最佳实践-写性能优化策略
- 网易范欣欣-HBase最佳实践-读性能优化策略
- 网易范欣欣-HBase最佳实践 – Scan用法大观园
0xFF 参考文档
-
Apache HBase
-
HBase 官方文档中文版
-
数据结构-常用树总结
-
HBase写请求分析
-
HBase Scan 中 setCaching setMaxResultSize setBatch 解惑
-
HBase二级索引实现方案
-
传统的行存储和(HBase)列存储的区别
-
大数据存取的选择:行存储还是列存储?
-
处理海量数据:列式存储综述(存储篇)
-
Hbase行级事务模型
-
HBase使用总结
-
Hbase split的三种方式和split的过程
-
Hbase 技术细节笔记(上)
-
Hbase 技术细节笔记(下)
-
HBase原理-数据读取流程解析
-
Apache HBase 全攻略
-
Hbase的Rowkey设计以及如何进行预分区
-
HBase之七:事务和并发控制机制原理
-
[翻译]HBase 中的 ACID
-
Hbase split的三种方式和split的过程
-
HBase数据存储格式
-
Hbase最佳实战:Region数量与大小的重要影响
-
网易范欣欣-HBase – Memstore Flush深度解析
-
网易范欣欣-HBase Compaction的前生今世-身世之旅
-
网易范欣欣-HBase - 数据写入流程解析
-
HBase篇(4)-你不知道的HFile
-
网易范欣欣-HBase-数据读取流程解析
-
网易范欣欣-HBase-迟到的‘数据读取流程’部分细节
-
Hbase 布隆过滤器BloomFilter介绍
-
HBase高性能随机查询之道 – HFile原理解析
-
HBase 读流程解析与优化的最佳实践
-
HBase-拆分合并和调优参考
-
hbase-hug-presentation
-
HBASE(Memstore的专属JVM策略MSLAB)
-
HBase MSLAB和MemStoreChunkPool源码
你可能感兴趣的:(HBase应该知道的)