baiyan
全部视频:https://segmentfault.com/a/11...
- 今天我们正式进入redis5源码的学习。redis是一个由C语言编写、基于内存、单进程、可持久化的Key-Value型数据库,解决了磁盘存取速度慢的问题,大幅提升了数据访问速度,所以它常常被用作缓存。
- 那么为什么redis会如此之快呢?让我们首先从内部存储的数据结构的角度,一步一步揭开它神秘的面纱。
- 在redis的set、get等常用命令中,最尝试用的就是字符串类型。在redis中,存储字符串的数据类型,叫做简单动态字符串(Simple Dynamic String),即SDS,它在redis中是如何实现的呢?
引入
- 回顾我们之前在PHP7源码分析中讲到的zend_string结构:
struct _zend_string {
zend_refcounted_h gc; /*引用计数,与垃圾回收相关,暂不展开*/
zend_ulong h; /* 冗余的hash值,计算数组key的哈希值时避免重复计算*/
size_t len; /* 存长度 */
char val[1]; /* 柔性数组,真正存放字符串值 */
};- 之前在【PHP7源码学习】2019-03-13 PHP字符串笔记文中提到,设计一个存储字符串的结构,最重要的就是存储其长度和字符串本身的内容。至于为什么存储长度,是为了解决二进制安全的问题,且能够以常量复杂度访问到字符串的长度,详情可以到上述文章中查看。
SDS新老结构的对比
- 在redis3.2.x之前,SDS的存储结构如下:
struct sdshdr {
int len; //存长度
int free; //存字符串内容的柔性数组的剩余空间
char buf[]; //柔性数组,真正存放字符串值
}; - 以“Redis”字符串为例,我们看一下它在旧版SDS结构中是如何存储的:

- free字段为0,代表buf字段没有剩余存储空间
- len字段为5,代表字符串长度为5
- buf字段存储真正的字符串内容“Redis”
- 存储字符串内容的柔性数组占用内存大小为6字节,其余字段所占用8个字节(4+4+6 = 14字节)
- 在新版本redis5中,为了进一步减少字符串存储过程中的内存占用,划分了5种适应不同字符串长度专用的存储结构:
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; //低三位存储类型,高5位存储字符串长度,这种字符串存储类型很少使用
char buf[]; //存储字符串内容的柔性数组
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; //字符串长度
uint8_t alloc; //已分配的总空间
unsigned char flags; //标识是哪种存储类型
char buf[]; //存储字符串内容的柔性数组
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; //字符串长度
uint16_t alloc; //已分配的总空间
unsigned char flags; //标识是哪种存储类型
char buf[]; //存储字符串内容的柔性数组
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; //字符串长度
uint32_t alloc; //已分配的总空间
unsigned char flags; //标识是哪种存储类型
char buf[]; //存储字符串内容的柔性数组
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; //字符串长度
uint64_t alloc; //已分配的总空间
unsigned char flags; //标识是哪种存储类型
char buf[]; //存储字符串内容的柔性数组
};- 我们可以看到,SDS的存储结构由一种变成了五种,他们之间的不同就在于存储字符串长度的len字段和存储已分配字节数的alloc字段的类型,分别占用了1、2、4、8字节(不考虑sdshdr5类型),这决定了这种结构能够最大存储多长的字符串(2^8/2^16/2^32/2^64)。
- 我们注意,这些结构体中都带有__attribute__ ((__packed__))关键字,它告诉编译器不进行结构体的内存对齐。这个关键字我们下文会详细讲解。关于结构体内存对齐是什么,请参考【PHP7源码学习】2019-03-08 PHP内存管理2笔记。
利用gdb查看SDS的存储结构
- 接着说我们之前存储“Redis”的例子,我们需要先对其进行gdb,观察"Redis”字符串使用了哪种结构,gdb的步骤如下:
- 首先到官网下载源码包,编译
- 启动一个终端,进入redis源码的src目录下,后台启动一个redis-server:
./redis-server &- 然后查看当前redis的后台进程的pid:
ps -aux |grep redis- 记录下这个pid,然后利用gdb -p命令调试该端口(如端口号是11430):
gdb -p 11430- 接着在setCommand函数处打一个断点,这个函数用来执行set命令,然后使用c命令执行到断点处:
(gdb) b setCommand
(gdb) c- 有了redis服务端,我们还要启动一个redis客户端,接下来启动另一个终端(同样在src目录下),启动客户端:
./redis-cli- 接着我们在redis客户端中执行set命令,我们设置了一个key为Redis,值为1的key-value对:
127.0.0.1:6379> set Redis 1- 返回我们之前终端中的服务端,我们发现它停在了setCommand处:
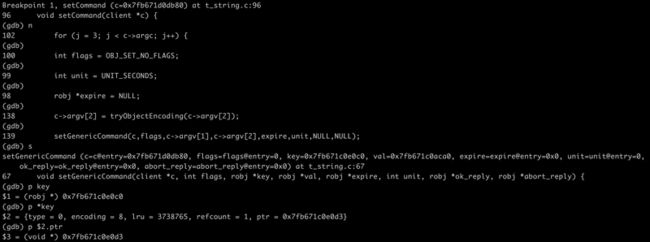
- 接着一直n下去,直到setGenericCommand函数,s进去,就可以看到我们的key “Redis”了,它是一个rObj结构(我们暂时不看),里面的ptr就指向字符串结构的buf字段,我们强转一下,能够看到字符串内容“Redis”。
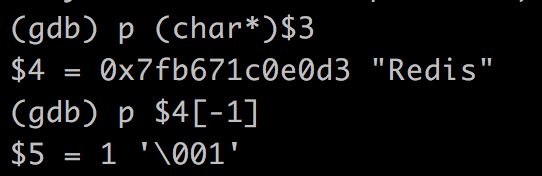
- 我们知道,无论是这五种结构中的哪一种,其前一位一定是flag字段,我们打印它的值,它的值为1。那么1是什么含义呢,它被用来标识是这五种字符串结构中的哪一种:
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4- 它的值为1,代表是sdshdr8类型,我们可以画出当前字符串的存储结构图:
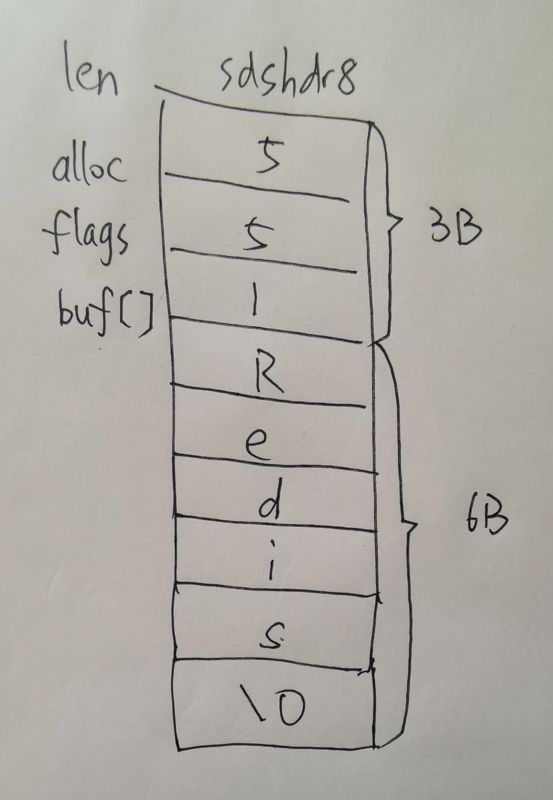
- 我们可以看到,它总共占用3+6 = 9字节,比之前的14字节节省了5字节。通过对之前长度和alloc字段的细化(由之前的int转为int8、int16、int32、int64),这样一来,就会大大节省redis存储字符串所占用的内存空间。内存空间是非常宝贵的,而且redis中最常用的数据类型就是字符串类型。虽然看起来节省的空间很少,但由于它非常常用,所以这样做的好处是无穷大的。
关键字__attribute__ ((packed))的作用
- 该关键字用来告知编译器不需要进行结构体的内存对齐。
- 为了测试__attribute__ ((packed))关键字在redis字符串结构中的作用,我们写如下一段测试代码:
#include "stdio.h"
int main(){
struct __attribute__ ((__packed__)) sdshdr64{
long long len;
long long alloc;
unsigned char flags;
char buf[];
};
struct sdshdr64 s;
s.len = 1;
s.alloc = 2;
printf("sizeof sds64 is %d", sizeof(s));
return 1;
}- 我们定义一个结构体,其字段和redis中的字符串结构基本一致。如果加上__attribute__ ((__packed__)) ,应该不是内存对齐的。如果去掉它,就应该是内存对齐的,会比前一种情况更加浪费内存,所以会对齐会节省内存。我们现在猜想的内存结构图应该如下所示:
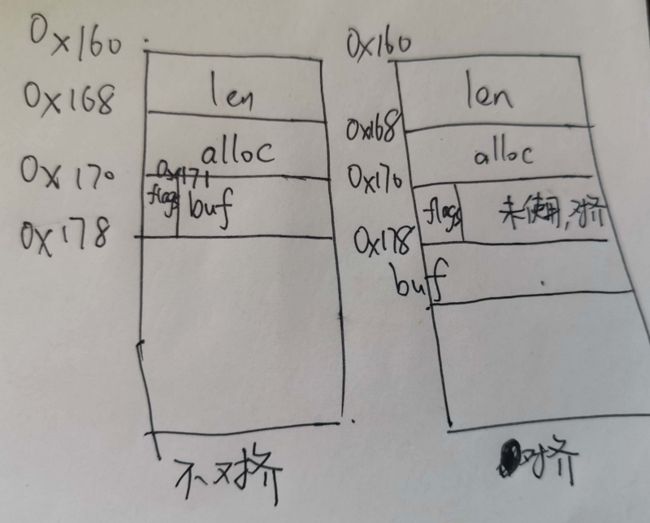
- 我们首先验证加上__attribute__ ((__packed__)) 的情况,我们预期应该是不对齐的,在gdb中内存地址如下:

- 我们看到,buf确实是从0x171地址处开始的,并没有对齐。那么我们看另一种情况,去掉__attribute__ ((__packed__)),再进行gdb调试:

- 大家看这张图,是不是和上一张图一摸一样(我真的去掉了并且重新编译了!!!)。这说明在当前情况下,redis字符串结构中的柔性数组的起始位置并不受是否加__attribute__ ((__packed__))关键字而影响,是紧跟在结构体后面的,所以节省内存这个说法并不成立。(不一定是所有情况下柔性数组都紧跟在结构体后面,如果把buf的类型改为int就不是紧跟在后面,大家感兴趣可以自己调试一下)。
- 那么,为什么这里要加上__attribute__ ((__packed__)呢?我们换个思路,既然不能节省空间,那么能不能节省时间呢?会不会操作非对齐的结构体性能更好、效率更高,或者是写代码更方便、可阅读性强呢?
- 笔者在这里的猜想是比较方便工程中的代码编写,可阅读性更强,我的参考如下:
- 在sizeof运算符中,它返回的是结构体占用空间的大小,和是否对齐有很大关系。比如上例中的结构体,如果不加上__attribute__ ((__packed__)),说明需要内存对齐,sizeof(struct s)的返回结果应该为24(8+8+8);如果加上__attribute__ ((__packed__)),说明不需要对齐,返回的结果应该为17(8+8+1),我们打印一下:
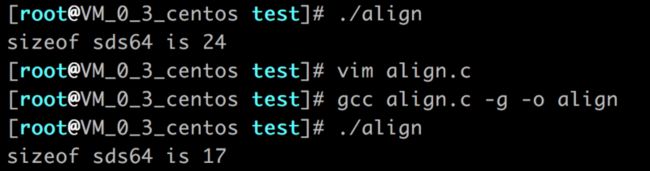
- 结果和我们预期的一致。我们知道,在之前我们gdb的时候,rObj的指针直接指向柔性数组buf的地址,即字符串内容的起始地址。那么如何知道它的len和alloc的值呢?只需要用buf的地址ptr - sizeof(struct s)即可。在这里,如果加上__attribute__ ((__packed__)),它返回的结果是17,那么直接做减法,就可以到结构体开头的位置,即可直接读取len的值。如果不加__attribute__ ((__packed__)),它返回的结果是24,做减法就会的到错误的位置,这就是原因所在,在源码中我们也可以看到,它确实是这么找到当前字符串结构体的头部的:
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))- 那么我们可能会问了,你刚才不是还用buf[-1]也能访问到吗?或者buf[-17],应该也能访问到len吧。这里笔者简单猜想可能是上一种写法,在工程的代码实现中,更加易读也更加方便。更加深层的原因仍待讨论。
为什么需要alloc字段
- 在之前的讲解中,我们一直没有提到alloc字段的作用。我们知道,它是目前给存储字符串的柔性数组总共分配了多少字节的空间。那么记录这个字段的作用何在呢?那就是空间预分配和惰性空间释放的设计思想了。
- 空间预分配:在需要对 SDS 进行空间扩展的时候, 程序不仅会为 SDS 分配修改所必须要的空间, 还会为 SDS 分配额外的未使用空间。举一个例子,我们将字符串“Redis”扩展到“Redis111”,应用程序并不仅仅分配3个字节,仅仅让它恰好满足分配的长度,而是会额外分配一些空间。具体如何分配,见下述代码注释。我们讲其中一种分配方式,假设它会分配8字节的内存空间。现在总共的内存空间为5+8 = 13,而我们只用了前8个内存空间,还剩下5个内存空间未使用。那么我们为什么要这样做呢?这是因为如果我们再继续对它进行扩展,如改成“Redis11111”,在扩展 SDS 空间之前,SDS API 会先检查未使用空间是否足够,如果足够的话,API 就会直接使用未使用空间那么我们就不用再进行系统调用申请一次空间了,直接把追加的“11”放到之前分配过的空间处即可。这样一来,会大大减少使用内存分配系统调用的次数,提高了性能与效率。空间预分配的代码如下:
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s); // 获取当前字符串可用剩余空间
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* 如果可用空间大于追加部分的长度,说明当前字符串还有额外的空间,足够容纳扩容后的字符串,不用分配额外空间,直接返回 */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC) //SDS_MAX_PREALLOC = 1MB,如果扩容后的长度小于1MB,直接额外分配扩容后字符串长度*2的空间
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC; //扩容后长度大于等于1MB,额外分配扩容后字符串+1MB的空间
...
真正的去分配空间
...
sdssetalloc(s, newlen);
return s;
}- 上述sdsavail函数在获取字符串剩余可用空间的时候,就会使用到alloc字段。它记录了分配的总空间大小,方便我们在进行字符串追加操作的时候,判断是否需要额外分配空间。当前剩余的可用空间大小为alloc - len,即已分配总空间大小alloc - 当前使用的空间大小len
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
return 0;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
return sh->alloc - sh->len;
}
}
return 0;
}- 惰性空间释放:惰性空间释放用于优化 SDS 的字符串截取或缩短操作。当 SDS 的 API 需要缩短 SDS 保存的字符串时,程序并不立即回收缩短后多出来的字节。这样一来,如果将来要对 SDS 进行增长操作的话,这些未使用空间就可能会派上用场。比如我们将“Redis111”缩短为“Redis”,然后又改成“Redis111”,这样,如果我们立刻回收缩短后多出来的字节,然后再重新分配内存空间,是非常浪费时间的。如果等待一段时间之后再回收,可以很好地避免了缩短字符串时所需的内存重分配操作, 并为将来可能有的增长操作提供了扩展空间。源码中一个清空字符串的SDS API如下:
/* Modify an sds string in-place to make it empty (zero length).
* However all the existing buffer is not discarded but set as free space
* so that next append operations will not require allocations up to the
* number of bytes previously available. */
void sdsclear(sds s) {
sdssetlen(s, 0);
s[0] = '\0';
}- 我们重点看上面的注释:但是所有额外分配的空间并不会随着清空字符串而释放,所以下一个对字符串的追加操作并不会再次进行内存分配的系统调用。而源码中也并没有直接调用任何函数,对清空操作之后的剩余空间立刻进行释放,也验证了我们之前的猜想。