baiyan
全部视频:【每日学习记录】使用录像设备记录每天的学习
字典是啥
dict,即字典,也被称为哈希表hashtable。在redis的五大数据结构中,有如下两种情形会使用dict结构:
- hash:数据量小的时候使用ziplist,量大时使用dict
- zset:数据量小的时候使用ziplist,数据量大的时候使用skiplist + dict
结合以上两种情况,我们可以看出,dict也是一种较为复杂的数据结构,通常用在数据量大的情形中。通常情况下,一个dict长这样:
在这个哈希表中,每个存储单元被称为一个桶(bucket)。我们向这个dict(hashtable)中插入一个"name" => "baiyan"的key-value对,假设对这个key “name”做哈希运算结果为3,那么我们寻找这个hashtable中下标为3的位置并将其插入进去,得到如图所示的情形。我们可以看到,dict最大的优势就在于其查找的时间复杂度为O(1),是任何其它数据结构所不能比拟的。我们在查找的时候,首先对key ”name“进行哈希运算,得到结果3,我们直接去dict索引为3的位置进行查找,即可得到value ”baiyan“,时间复杂度为O(1),是相当快的。
redis中的字典
基本结构
在redis中,在普通字典的基础上,为了方便进行扩容与缩容,增加了一些描述字段。还是以上面的例子为基础,在redis中存储结构如下图所示: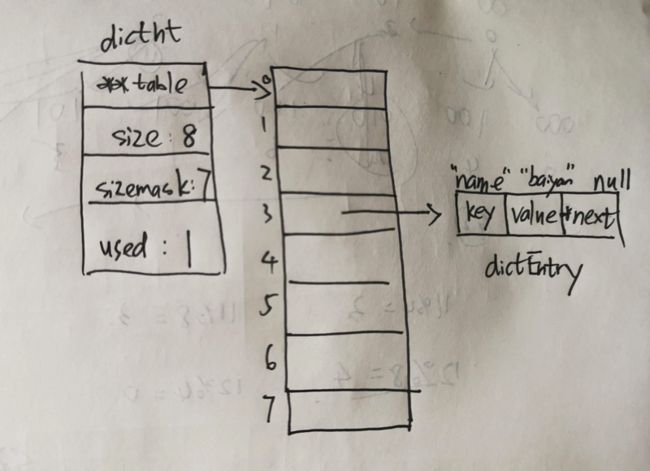
dictht的结构如下:
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;在dictht中,真正存储数据的地方是**table这个dictEntry类型二级指针。我们可以把它拆分来看,首先第一个指针可以代表一个一维数组,即哈希表。而后面的指针代表,在每个一维数组(哈希表)的存储单元中,存储的都是一个dictEntry类型的指针,这个指针就指向我们存储key-value对的dictEntry类型结构的所在位置,如上图所示。
存储最终key-value对的dictEntry的结构如下:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;一个存储key-value对的entry,最主要还是这里的key和value字段。由于存储在dict中的key和value可以是字符串、也可以是整数等等,所以在这里均用一个void * 指针来表示。我们注意到最后有一个也是同类型dictEntry的next指针,它就是用来解决我们经常说的哈希冲突问题。
哈希冲突
当我们对不同的key进行哈希运算之后结果相同时,就碰到了哈希冲突的问题。常用的两种哈希冲突的解决方案有两种:开放定址法与链地址法。redis使用的是后者。通过这个next指针,我们就可以将哈希值相同的元素都串联起来,解决哈希冲突的问题。注意在redis的源码实现中,在往dict插入元素的时使用的是链表的头插法,即将新元素插到链表的头部,这样就不用每次遍历到链表的末尾进行插入,降低了插入的时间复杂度。
链地址法所带来的问题
假设我们一直往dict中插入元素,那么这个哈希表的所有bucket都会被占满,而且在链地址法解决哈希冲突的过程中,每个bucket后面的链表会非常长。这样一来,这个链表的时间复杂度就会逐渐退化成O(n)。对于整体的dict而言,其查询效率就会大大降低。为了解决数据量过大导致dict性能下降的问题,我们需要对其进行扩容,来满足后续插入元素的存储需要。
分而治之的rehash
- 在通常情况下,我们会对哈希表做一个2倍的扩容,即由2->4,4->8等等。假设我们的一个dict中已经存储了好多数据,我们还需要向这个dict中插入一大堆数据。在后续插入大量数据的过程中,由于我们需要解决dict性能下降的问题,我们需要对其进行扩容。由于扩容的时候,需要对所有key-value对重新进行哈希运算,并重新分配到相应的bucket位置上,我们称这个过程为为rehash。
- 在rehash过程中,需要做大量的哈希运算操作,其开销是相当大、而且花费的时间是相当长的。由于redis是单进程、单线程的架构,在执行rehash的过程中,由于其开销大、时间长,会导致redis进程阻塞,进而无法为线上提供数据存储服务,对外部会返回redis服务不可用。为了解决一次性rehash所导致的redis进程阻塞的问题,利用分而治之的编程思想,将一次rehash操作分散到多个步骤当中去减小rehash给redis进程带来的资源占用。举一个例子,可能会在后续的get、set操作中,进行一次rehash操作。为了实现这种操作,redis其实设计了两个哈希表,一个就是我们之前讲过的对外部提供存取服务的哈希表,而另一个就专门用来做rehash操作。这种分而治之的思想,将一次大数据量的rehash操作分散到多次完成,叫做渐进式rehash:

- 目前是刚刚要进行rehash的状态。我们可以看到,在之前画的图的基础上,我们加入了一个新的结构dict,其中的ht[2]字段就负责指向两个哈希表。下面一个哈希表的大小为之前的大小8*2=16,没有任何元素。关于dict的结构如下:
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehash进程标识。如果值为-1则不在rehash,否则在进行rehash */
unsigned long iterators; /* number of iterators currently running */
} dict;- 注意其中的rehashidx字段,它代表我们进行rehash的进程。注意我们每次进行get或set等命令的时候,rehash就会进行一次,即把一个在原来哈希表ht[0]上的元素挪到新哈希表ht[1]中,注意一次只移动一个元素,移动完成之后,rehashidx就会+1,直到原来哈希表上所有的元素都挪到新哈希表上为止。rehash完成之后,新哈希表ht[1]就会被置为ht[0],为线上提供服务。而原来的哈希表ht[0]就会被销毁。rehash的源码如下:
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* 将老的哈希表ht[0]中的元素移动到新哈希表ht[1]中 */
while(de) {
uint64_t h;
nextde = de->next;
/* 计算新哈希表ht[1]的索引下标*/
h = dictHashKey(d, de->key) & d->ht[1].sizemask; //哈希算法
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* 检查是否rehash完成,若完成则置rehashidx为-1 */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}rehash过程中可能带来的问题
rehash对查找的影响
如果在rehash的过程中(例如容量由4扩容到8),如果需要查找一个元素。首先我们会计算哈希值(假设为3)去找老的哈希表ht[0],如果我们发现位置3上已经没有了元素,说明这个元素已经被rehash过了,到新的哈希表上对应的位置3或7上寻找即可。
rehash对遍历的影响
问题
试想这么一种情况:在rehash之前,我们使用SCAN命令对dict进行第一次遍历;而rehash结束之后我们进行第二次SCAN遍历,会发生什么情况?
在讨论这个问题之前,我们先熟悉一下SCAN命令。我们知道在我们执行keys这种返回所有key值的命令,由于所有key加在一块是相当多的,如果一次性全部把它遍历完成,能够让单进程的redis阻塞相当长的时间,在这段时间里都无法对外提供服务。为了解决这个问题,SCAN命令横空出世。它并不是一次性将所有的key都返回,而是每次返回一部分key并记录一下当前遍历的进度,这里用一个游标去记录。下次再次运行SCAN命令的时候,redis会从游标的位置开始继续往下遍历。SCAN命令实际上也是一种分而治之的思想,这样一次遍历一小部分,直到遍历完成。SCAN命令官方解释如下:
SCAN 命令是一个基于游标的 迭代器: SCAN 命令每次被调用之后, 都会向用户返回一个新的游标,用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。
SCAN命令的使用方法如下:
redis 127.0.0.1:6379> scan 0
1) "17"
2) 1) "key:12"
2) "key:8"
3) "key:4"
4) "key:14"
5) "key:16"
6) "key:17"
7) "key:15"
8) "key:10"
9) "key:3"
10) "key:7"
11) "key:1"
redis 127.0.0.1:6379> scan 17
1) "0"
2) 1) "key:5"
2) "key:18"
3) "key:0"
4) "key:2"
5) "key:19"
6) "key:13"
7) "key:6"
8) "key:9"
9) "key:11"
- 在上面这个例子中,第一次迭代使用0作为游标,表示开始一次新的迭代。第二次迭代使用的是第一次迭代时返回的游标,也即是命令回复第一个元素的值17 。
- 从上面的示例可以看到, SCAN 命令的回复是一个包含两个元素的数组,第一个数组元素是用于进行下一次迭代的新游标,而第二个数组元素则是一个数组,这个数组中包含了所有被迭代的元素。
- 在第二次调用 SCAN 命令时,命令返回了游标0,这表示迭代已经结束,整个数据集(collection)已经被完整遍历过了。
- 以0作为游标开始一次新的迭代,一直调用 SCAN 命令,直到命令返回游标0,我们称这个过程为一次完整遍历。
回到正题,我们来解决之前的问题。 我们简化一下dict的结构,只留下两个基本的哈希表结构,我们现在有4个元素:12、13、14、15,假设哈希算法为取余。
- 假设现在我们在没有rehash之前,对其使用SCAN命令,基于我们之前讲过的知识点,由于SCAN是基于游标的增量遍历,我们假设这个SCAN命令只遍历到游标为1的位置就停止了:
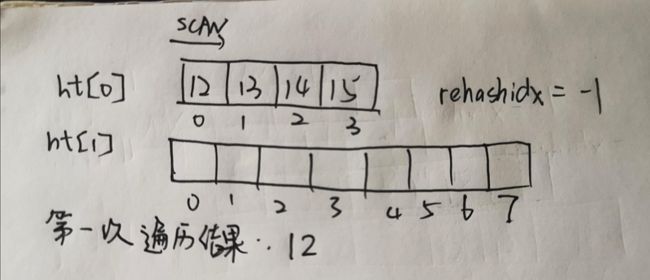
- 我们得到第一次遍历的结果为:12
- 开始进行rehash。
- rehash结束,我们再次使用SCAN命令对其进行遍历。由于上次返回的游标为1,我们从1的位置继续遍历,只不过这次要在新的哈希表中进行遍历了:
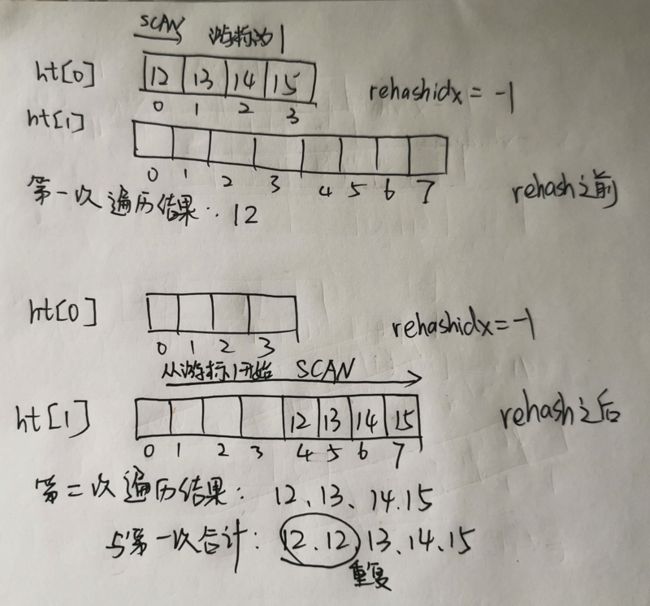
- 第二次SCAN命令遍历的结果为:12、13、14、15
那么我们将两次SCAN的结果合起来,为12、12、13、14、15。我们发现,元素12被多遍历了一次,与我们的预期不符。所以我们得出结论:在rehash过程中执行SCAN命令会导致遍历结果出现冗余。
解决方案
为了解决扩容和缩容进行rehash的过程中重复遍历的问题,redis对哈希表的下标做出了如下变化(v就是哈希表的下标):
v = rev(v);
v++;
v = rev(v);首先将游标倒置,加一后,再倒置,也就是我们所说的“高位++”的操作。这里的这几步操作是来通过前一个下标,计算出哈希表下一个bucket的下标。举一个例子:最开始00这个bucket不用动,之前经过正常的低位++之后,00的后面应该为01。然而现在是高位++,原来01的位置的下标就会变成10.......以此类推。最终,哈希表的下标就会由原来顺序的00、01、10、11变成了00、10、01、11,如图所示: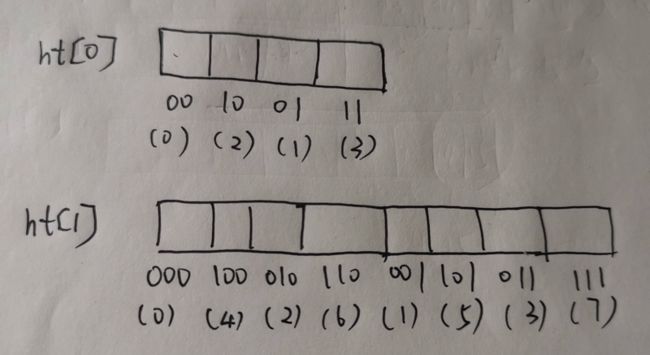
这样就能够保证我们多次执行SCAN命令就不会重复遍历了吗?接下来就是见证奇迹的时刻:
- 首先还是没进行rehash之前,对其进行SCAN。同样的,我们假设这个SCAN命令只遍历到游标为1的位置就停止了:
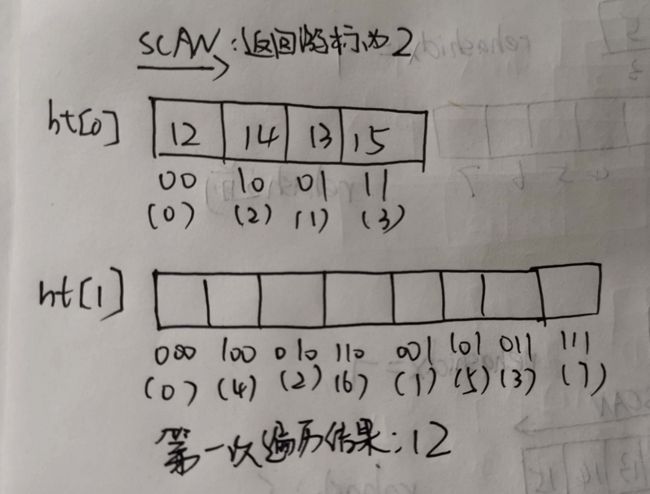
- 我们得到第一次遍历的结果:12
-
开始进行rehash
- rehash结束,我们再次使用SCAN命令对其进行遍历。注意这里,上次返回的游标为2,我们从2的位置继续遍历,也是要在新的哈希表中进行遍历了:

- 我们可以看到,经过一个小的下标的修改,就能够解决rehash所带来的SCAN重复遍历的问题。对dict进行遍历的源码如下:
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
dictScanBucketFunction* bucketfn,
void *privdata)
{
dictht *t0, *t1;
const dictEntry *de, *next;
unsigned long m0, m1;
if (dictSize(d) == 0) return 0;
// 如果SCAN的时候没有进行rehash
if (!dictIsRehashing(d)) {
t0 = &(d->ht[0]);
m0 = t0->sizemask;
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t0->table[v & m0]);
de = t0->table[v & m0];
while (de) { //遍历同一个bucket上后面挂接的链表
next = de->next;
fn(privdata, de);
de = next;
}
/* Set unmasked bits so incrementing the reversed cursor
* operates on the masked bits */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v); //反转v
v++; //反转之后即为高位++
v = rev(v); //再反转回来,得到下一个游标值
// 如果SCAN的时候正在进行rehash
} else {
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the bigger table */
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t0->table[v & m0]);
de = t0->table[v & m0];
while (de) { //遍历同一个bucket上后面挂接的链表
next = de->next;
fn(privdata, de);
de = next;
}
/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
do {
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t1->table[v & m1]);
de = t1->table[v & m1];
while (de) { //遍历同一个bucket上后面挂接的链表
next = de->next;
fn(privdata, de);
de = next;
}
/* Increment the reverse cursor not covered by the smaller mask.*/
v |= ~m1;
v = rev(v); //反转v
v++; //反转之后即为高位++
v = rev(v); //再反转回来,得到下一个游标值
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));
}
return v;
}有关rehash过程对SCAN的影响,限于篇幅仅仅展示这种情况。更多的情形请参考:Redis scan命令原理