Spark运行机制之DAG原理
学习过程中,看过很多讲作业提交和任务调度的原理,包括中英文版本,知道个大概,但有些细的东西总感觉不清晰,
比如drvier程序具体是什么?
一个application有多个job,每个action动作会触发一个job,为什么?
一个job内有多个stage,如何划分?stage有不同类型么?
一个stage内的task数量如何确定?
task具体是什么?
什么是shuffle map任务?shuffle操作具体怎么实现的?
什么是result map任务?
数据集存储中内存中,具体哪些数据在内存中,哪些不在内存中?
带着如上诸多疑问,尝试着去阅读spark的源码。接触scala不久,其语法感觉还是有点不好理解,很多语法细节不明了,忽略之,直接看核心逻辑。1天下来,虽然只看了一小部分,但明显的有豁然开朗的感觉,一下子明白了很多原理,明白了很多原来如此。现将了解到了记录下来,加深记忆,同时便于以后复习,或者纠正。
提交
spark-submit命令其实是一个shell脚本,它的作用主要包括加载和设置环境变量,启动main主类,即启动org.apache.spark.deploy.SparkSubmit中的main函数。
main内部主要做一些初始化操作,参数检测,最重要的根据输入参数确定一下步需要执行的main函数,代码叫childMainClass。
在client模式下,childMainClass即spark-submit参数中,我们自己编写包括main函数的object类。childMainClass的main函数会在本地开始执行。这就解释了client模式上,为什么关闭客户端程序会导致整个application的结束。
在非client模式下,代码还未看,推测在不同的master下,如yarn或spark,childMainClass会是不同的启动封装类,但类内部仍然会调用我们自己的object类。待验证。
driver
我的理解,driver程序即我们自己编写的object类。
driver的逻辑如下:
首先必须创建SparkContext对象sc,通过sc就可以创建RDD了。
DagScheduler
核心的调度类,所有的任务划分都是在它里边控制的。
application
job划分原则
每个action函数内会调用runJob,进而调用submitJob,所以每个action会触发一个job。
job间按顺序执行,待前一个job完全成功,才能执行下一个job,所有job执行成功后,本application执行完成。
job
stage划分原则
1. shuffle操作
2. action操作
action操作触发 submitJob调用,submitJob内部会根据根据action创建ResultStage ,并找到其依赖的所有ShuffleMapStage。
stage间按顺序执行,待前一个stage完全成功,才能执行下一个stage,所有stage执行成功后,本job执行完成。
stage
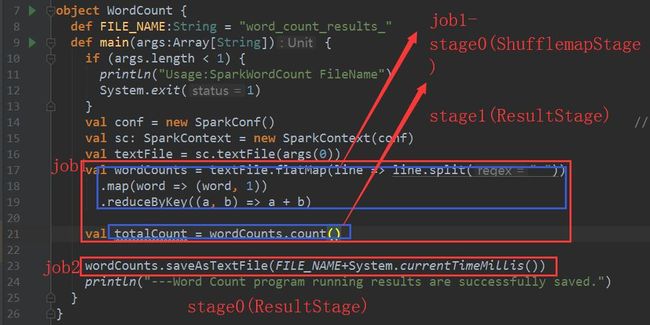
分ShuffleMapStage和ResultStage两种。
每个job中的最后一个stage为ResultStage,之前的均为ShuffleMapStage。
如果job1和job2中的ResultStage有相同的RDD依赖,则job1中计算了RDD后, job2中应该不用重新计算RDD,直接拿来用。
Stage内部逻辑
同一stage内,会将一些公用数据,如task的序列化二进制值、配置信息等,作为广播变量,广播到所有executor。同一个stage内可能有多次transformation,所有的中间数据应该都是存储在内存中的,但跨stage的数据在内存中还是文件中呢?待验证
同时启动n个task,依据local原则,每个task到相应的exector上执行。每个task执行的内容完全相同,只是操作的数据不同。
task数量等于partion或filesplit的数量。
在exector中的每个task执行完成后,将结果返回给driver。
如果后续还有stage,则继续执行后续stage。
附一张DAG规划图: