推荐系统实践学习笔记(二):代码实现
写在前面:今天基于Movielens数据集把《推荐系统实践》上的部分算法实现了一下,顺便巩固python和pandas库的使用,发现书本上的代码有很多不靠谱之处(也许是我水平不够),所以基本都是自己写的,不当之处,还望指正。
读取Movielens数据集
Movielens数据集有几种不同规模的,我选择的是1M-DataSet,大约包含6000多个用户对4000多部电影的一百万条评分记录,下载地址:MovieLens|GroupLens
数据集中有三个.dat文件,分别是users、movies、ratings,用Sublime Text2打开文件并观察。
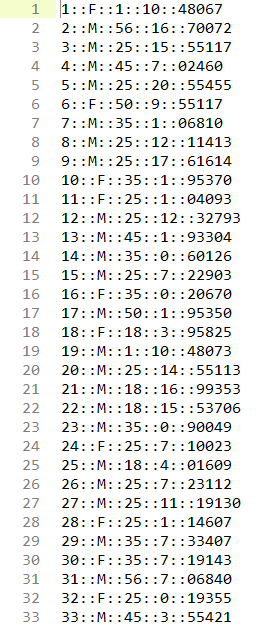
users.dat
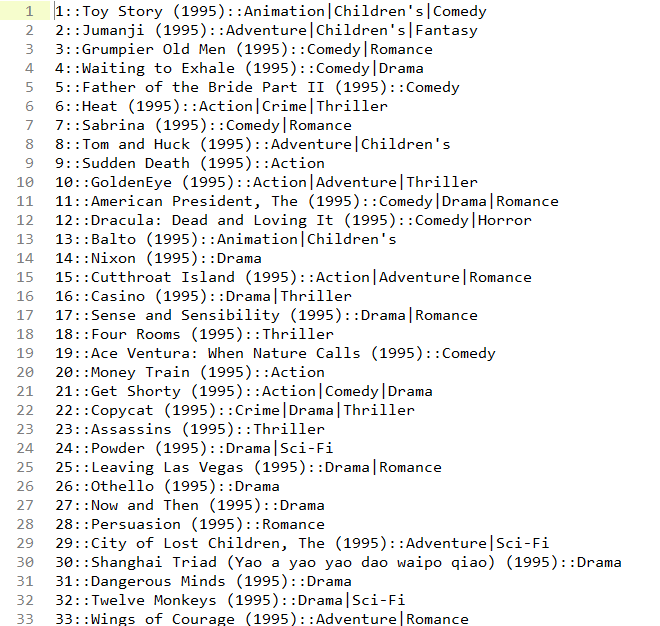
movies.dat

ratings.dat
三个文件都是用”::”分隔的表格形式文件,查看说明文档发现各列代表的信息分别如下:
users.dat:UserID::Gender::Age::Occupation::Zip-code
movies.dat:MovieID::Title::Genres
ratings.dat:UserID::MovieID::Rating::Timestamp
使用pandas库中的read_table函数读取文件,并用merge函数将三个表格合并,保存为.csv格式的文件。
unames=['user_id','gender','age','occupation','zip']
users=pd.read_table('ml-1m/users.dat',sep='::',header=None,names=unames)
mnames = ['movie_id', 'title', 'genres']
movies = pd.read_table('ml-1m/movies.dat', sep='::', header=None, names=mnames)
rnames = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_table('ml-1m/ratings.dat', sep='::', header=None, names=rnames)
all_data = pd.merge(pd.merge(ratings, users), movies)
data = DataFrame(data=all_data,columns=['user_id','movie_id'])
data.to_csv('data.csv')UserCF
由于在进行TopN推荐而非评分预测时,我们并不关心用户给电影究竟打了多少分,而是关心用户是否对物品产生了行为,所以这里仅仅需要用户ID及其对应评分的电影ID数据,读取之前存储的表格并提取我们需要的信息:
data=pd.read_csv('data.csv')
X=data['user_id']
Y=data['movie_id']书里给出的代码使用了dict存储用户id和电影id,如果不进行任何处理的话是不合理的,因为大多数用户都对不止一部电影进行了评分,一部电影也有多位不同用户进行过评分,‘user_id’和‘movie_id’都不能作为dict中的key,因此我在这里直接进行倒排矩阵的建立:
item_user=dict()
for i in range(X.count()):
user=X.iloc[i]
item=Y.iloc[i]
if item not in item_user:
item_user[item]=set()
item_user[item].add(user)
回顾一下UserCF的相似度计算公式:
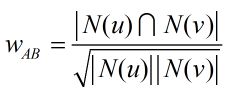
计算N(u)、矩阵C(u)(v):
C={}
N={}
for i,users in item_user.items():
for u in users:
N.setdefault(u,0)
N[u]+=1
C.setdefault(u,{})
for v in users:
if u==v:
continue
C[u].setdefault(v,0)
C[u][v]+=1建立相似度矩阵:
W=C.copy()
for u,related_users in C.items():
for v,cuv in related_users.items():
W[u][v]=cuv/math.sqrt(N[u]*N[v])接下来就可以利用公式向用户推荐和他兴趣最相似的K个用户喜欢的物品:
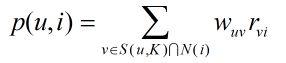
代码:
def recommend(user,user_item,W,K):
rank={}
interacted_items=user_item[user]
for v,wuv in sorted(W[user].items(),reverse=True)[0:K]:
for i in user_item[v]:
if i not in interacted_items:
rank.setdefault(i,0)
rank[i]+=wuv
return rank对热门物品进行了惩罚的改进的UserCF,只需要在计算C[u][v]时乘上1/math.log(1+len(users))即可。ItemCF只要在UserCF算法代码的基础上稍作修改,在这里就不赘述了。