YDB功能解析之多值列
如果我们想要在一个列中存放多个值,使用多值列是一个不错的方式,通过多值列,我们可以将各种多个数据按照各种分隔方式存储到YDB中进行检索
YDB多值列的特性:
1.无序性 :YDB返回的多值列中的数据是无序的
2.排重性:YDB返回的数据会经过排重
3.可分组统计:YDB支持使用分词列做分组统计
4.可规避空值:如果传递的数据为空值,则会当做null处理
- 生成测试数据
hadoop fs -rm -r /data/example/quickstart/
hadoop fs -mkdir -p /data/example/quickstart/
hadoop jar ./lib/ydb-1.2.1-pg.jar cn.net.ycloud.ydb.server.reader.kafka.MrMakeShuData 30000000 /data/example/quickstart/1.txt- 创建数据表
由于原始数据中多值列数据只有一列,所以我们这里创建一个HIVE 表关联源数据,并通过hive表与YDB表的对应关系导入多列多值列数据
CREATE external table ydb_import_txt_multyvalue(
phonenum string, usernick string, ydb_sex string, ydb_province string, ydb_grade string, ydb_age string, ydb_blood string, ydb_zhiye string, ydb_earn string, ydb_prefer string, ydb_consume string, ydb_day string, amtdouble double,amtlong bigint,content string,multyvalue string
)
row format delimited fields terminated by ','
location '/data/example/quickstart/';- 创建YDB表(多值列测试表)
create ydbtable ydb_example_shu_multyvalue(
phonenum haoma,
usernick string,
ydb_sex string,
ydb_province string,
ydb_grade string,
ydb_age string,
ydb_blood string,
ydb_zhiye string,
ydb_earn string,
ydb_prefer string,
ydb_consume string,
ydb_day string,
amtdouble tdouble,
amtlong tlong,
content simpletext,
multyvalue_string y_string_idm,
multyvalue_tlong y_tlong_idm,
multyvalue_long y_long_idm,
multyvalue_tdouble y_tdouble_idm,
multyvalue_double y_double_idm
)- 导入测试数据
insert overwrite table ydbpartion
select 'ydb_example_shu_multyvalue', '3000w', '',
YROW(
'phonenum',phonenum,
'usernick',usernick,
'ydb_sex',ydb_sex,
'ydb_province',ydb_province,
'ydb_grade',ydb_grade,
'ydb_age',ydb_age,
'ydb_blood',ydb_blood,
'ydb_zhiye',ydb_zhiye,
'ydb_earn',ydb_earn,
'ydb_prefer',ydb_prefer,
'ydb_consume',ydb_consume,
'ydb_day',ydb_day,
'amtdouble',amtdouble,
'amtlong',amtlong,
'content',content,
'multyvalue_string',multyvalue,
'multyvalue_tlong',multyvalue,
'multyvalue_long',multyvalue,
'multyvalue_tdouble',multyvalue,
'multyvalue_double',multyvalue
)
from ydb_import_txt_multyvalue;在上面的sql中我们指定了YDB表字段和HIVE表字段的对应关系,我们可以看到HIVE的 multyvalue 列指定了五个YDB字段的对应关系。
- 多值列数据预览

我们可以看到在上图中查询了五种数据类型的多值列,其中string类型的多值列返回的是经过排重的数据
- 多值列group by
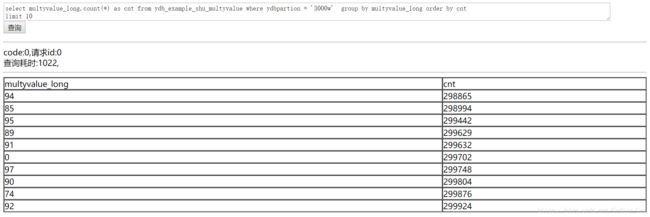
在上面的sql中我们指定了multyvalue_long字段进行分组,ydb将每行中的值按照空格分隔,并将数据进行分组统计
- 多值列与普通列group by

在上图中我们使用了long类型多值列与string类型普通列来进行分组统计
- 多值列与多值列 group by

以上是使用两组多值列进行分组统计,由于结果中含有笛卡尔积的关系会使用大量内存且会影响到查询性能,建议慎重使用
- 查询空及非空值
导入一些含有空值的数据
insert into table ydbpartion
select 'ydb_example_shu_multyvalue', 'nulltest', '',
YROW(
'phonenum',phonenum,
'usernick',usernick,
'ydb_sex',ydb_sex,
'ydb_province',ydb_province,
'ydb_grade',ydb_grade,
'ydb_age',ydb_age,
'ydb_blood',ydb_blood,
'ydb_zhiye',ydb_zhiye,
'ydb_earn',ydb_earn,
'ydb_prefer',ydb_prefer,
'ydb_consume',ydb_consume,
'ydb_day',ydb_day,
'amtdouble',amtdouble,
'amtlong',amtlong,
'content',content,
'multyvalue_string','',
'multyvalue_tlong','',
'multyvalue_long','',
'multyvalue_tdouble','',
'multyvalue_double',''
)
from ydb_import_txt_multyvalue limit 10000;查看 is null 的数据

查看非空的数据

- 数据检索
数据检索
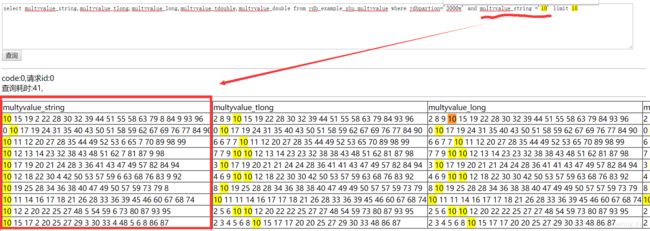
不等于查询
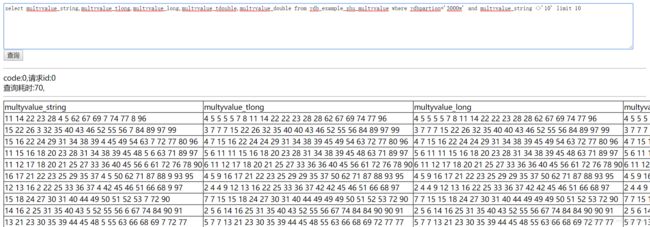
- 分词类型的多值列
创建一个新表覆盖之前的测试表
create ydbtable ydb_example_shu_multyvalue(
phonenum haoma,
usernick string,
ydb_sex string,
ydb_province string,
ydb_grade string,
ydb_age string,
ydb_blood string,
ydb_zhiye string,
ydb_earn string,
ydb_prefer string,
ydb_consume string,
ydb_day string,
amtdouble tdouble,
amtlong tlong,
content simpletext,
multyvalue_string y_string_idm,
multyvalue_tlong y_tlong_idm,
multyvalue_long y_long_idm,
multyvalue_tdouble y_tdouble_idm,
multyvalue_double y_double_idm,
multyvalue_dblike y_dblike_ism
)在上面的sql中,我们在最后一行添加了[multyvalue_dblike y_dblike_ism]字段,这是一个分词类型的多值列字段,截止至YDB 1.2.1版本,行存储多值列仅支持分词类型,且分词类型多值列不支持列存储。
接下来我们导入数据看一下
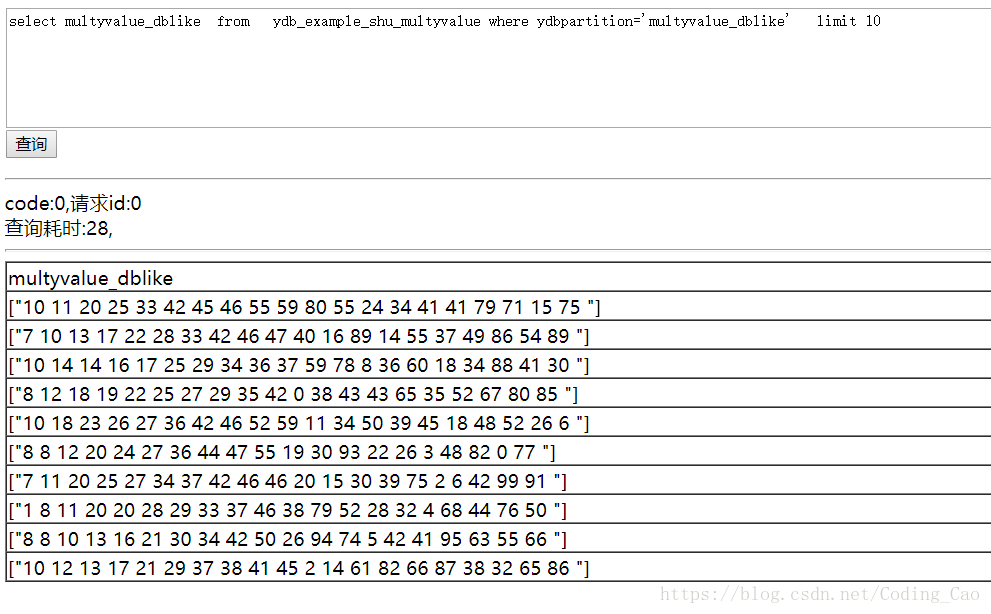
默认YDB分词类型多值列展示是使用[]括起来的,如果想要返回如
![]()
这样的数据的话需要在sql中添加 and ydbkv ='ydb.globel.env:fh' 参数
例如:
select multyvalue_dblike from ydb_example_shu_multyvalue where ydbpartition='multyvalue_dblike' and ydbkv ='ydb.globel.env:fh' limit 10
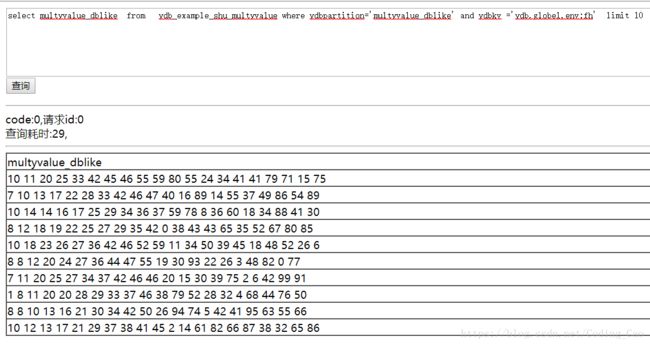
分词类型多值列模糊检索
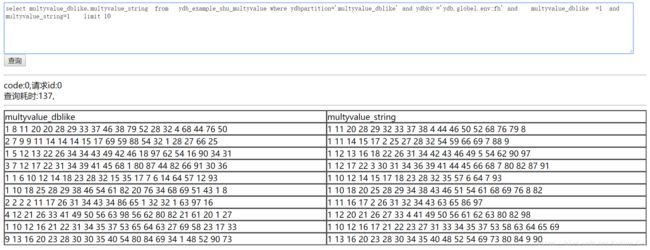
上图的sql中我们可以看到multyvalue_dblike查到的仅是含有1的数据,为了缩小命中范围我们将检索条件中添加正则进行过滤
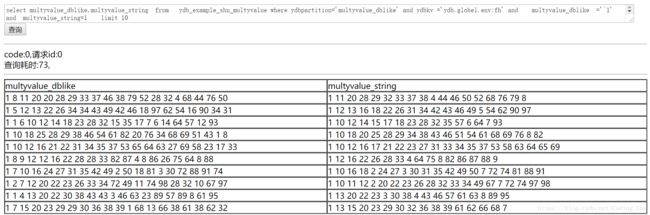
在上面的SQL中我们通过正则查询了开头是1的数据,使得命中效率要高于不加正则条件时的模糊检索。
结论:在分词类型的多值列中,使用正则可以更加有效的过滤掉不需要的数据。
对于YDB多值列以及YDB其他功能如果您有其他的疑问,见解和看法,欢迎您联系我们
QQ:1003906673
phone:17624021416
WeChat:

