Base64与Java -- Base64简介与原理
Base64与Java – Base64简介与原理
文章目录
- Base64与Java -- Base64简介与原理
- 简介与用途
- 为什么叫Base64?
- 编码流程
- 常规处理
- 特殊处理
- 剩余1个字节
- 剩余2个字节
- 注意
- 普通、url和MIME
- 选择
简介与用途
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。可查看RFC2045~RFC2049,上面有MIME的详细规范。
根据HTML 4.01规范中规定,URI中不应包含非ASCII字符,所以对于中文或者其他非ASCII字符都可以用Base64来进行编码传输,到达目的端后进行解码即可。(对于传输非ASCII字符,规范中也给出了建议,详情参照6.4 URI和附录B.2.1)
另外,对于传输数据时,可以使用Base64对明文数据进行编码,来起到一定程度的保护作用;同时也可能借助Base64对加密的报文信息进行协助编码或加密。
最后,对于较小的二进制文件或者图片不可在URI中直接传输,可以使用Base64进行编码后再进行传输,但需要注意的是,对于GET请求不同的浏览器服务器是有长度限制的,如果不是特殊需求,还是应考虑使用其他请求方式或解决方法。
为什么叫Base64?
2 6 2^{6} 26 = 64,所以Base64就是使用6bit表示的64个字符来编码任意字节流的编码方法,Base32就是使用32个字符来表示任意字节流的编码方法。
编码流程
首先我们来看一下Base64编码表
| ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
|---|---|---|---|---|---|---|---|
| 0 A | 1 B | 2 C | 3 D | 4 E | 5 F | 6 G | 7 H |
| 8 I | 9 J | 10 K | 11 L | 12 M | 13 N | 14 O | 15 P |
| 16 Q | 17 R | 18 S | 19 T | 20 U | 21 V | 22 W | 23 X |
| 24 Y | 25 Z | 26 a | 27 b | 28 c | 29 d | 30 e | 31 f |
| 32 g | 33 h | 34 i | 35 j | 36 k | 37 l | 38 m | 39 n |
| 40 o | 41 p | 42 q | 43 r | 44 s | 45 t | 46 u | 47 v |
| 48 w | 49 x | 50 y | 51 z | 52 0 | 53 1 | 54 2 | 55 3 |
| 56 4 | 57 5 | 58 6 | 59 7 | 60 8 | 61 9 | 62 + | 63 / |
表中每个单元前边的数字为字节表示的值,后边字符为值所对应的编码
下面我们开始介绍Base64编码算法,为直观展示编码的算法流程,Base64编码算法流程图如下(同时为了简单易懂,流程图的步骤采用了最直接的方式,即图中有许多重复步骤,可通过一定的算法进行流程优化,使代码更整洁):
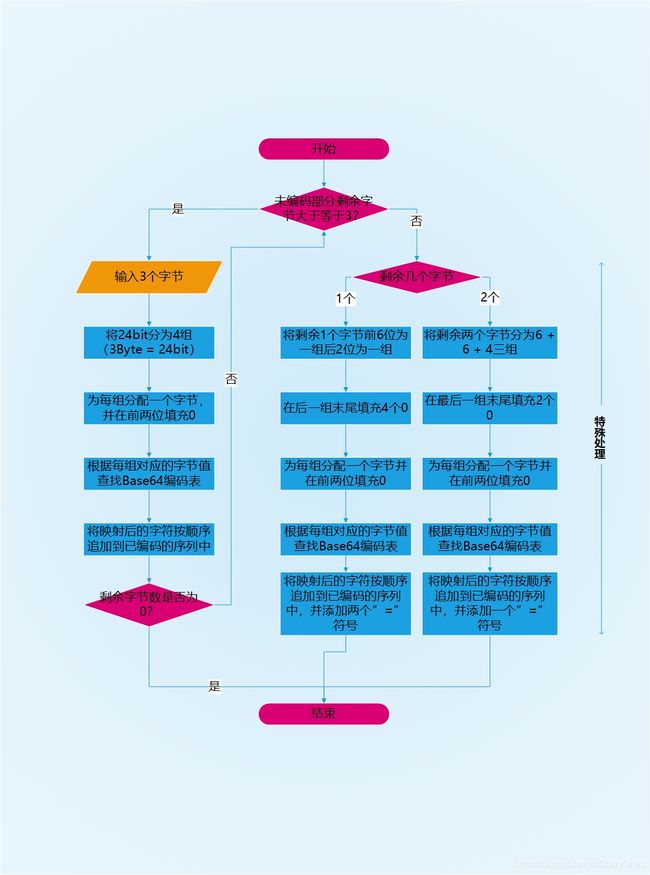
上图中,我们将算法划分为两个部分:常规处理和特殊处理。进入两个处理流程的划分标准是,剩余未编码字节数是否大于等于三,如果是则进行常规处理,如果不是则进入特殊处理。
从处理步骤来看,特殊处理只不过是在常规处理的基础上,进行了一定的增加和修改,所以我们对常规处理进行介绍
常规处理
我们使用"Kd9"作为例子:

1. 得到字符对应的二进制码值,且每6bit一组,3 * 8 = 6 * 4,所以我们将得到4组二进制码。
2. 为每一组分配1个字节,并且在最高的2位置零,获取每个字节对应的十进制值分别是18、54、16、57
3. 根据每个字节的十进制值查Base64编码表对应的字符,对应的字符串为:“S2Q5”
根据此规则每三个字节为一组(注意对于占2个字节的字符,那么每次会取1.5个字符,举例中使用ASCII字符,所以才会三个字符为一组),按顺序处理,直到剩余不足三个字节。剩余不足三个字节时将出现三种情况:
- 没有剩余字节
- 剩余1个字节
- 剩余2个字节
第一种情况是我们最希望看到的,因为就不需要特殊处理了,但是巧合不会一再的发生,还是要为后两种情况设计对策,这就是特殊处理。
特殊处理
剩余1个字节
我们使用"7"作为例子:

1. 得到二进制码,按照前6bit一组,后2bit一组。
2. 为后一组后面填充4个0,组成6bit。
3. 为每一组分配1个字节,并且在最高的2位置零,获取2个字节的对应十进制分别是:13、48。
4. 根据每个字节的十进制值查Base64编码表对应的字符,对应的字符串为:"Nw"。
5. 此时只有2个字符,其后添加2个"="字符。
6. 添加至转码字符串末尾。
可以看到,不同之处在两个地方,步骤2,为后一组的后面填充了4个0,从而组成了2个6bit组,这一步的目的是容易理解的,但是为什么在步骤5时要在后面追加2个"="字符呢?请大胆猜测,后文会进行解释。
剩余2个字节
我们使用"Ab"作为例子:

1. 依旧是先得到二进制码,此时共有 2 * 8 = 16bit,我们在末尾增加2个0,得到18bit。
2. 每6bit为一组,为每一组分配1个字节,并且在最高的2位置零,获取3个字节对应的十进制是:16、22、8。
3. 根据每个字节的十进制值查Base64编码表对应的字符,对应的字符串为:"QWI"。
4. 此时只有3个字符,其后添加1个"="字符。
为什么要追加"="字符呢,我们可以思考一下,当进行解码的时候该怎么做呢:只需要再把4个字节去掉每个字节前边的2个0,组成3个字节,再还原即可。那么会不会存在编码字符串的字节数不能被4整除呢?答案是存在的,并且只存在两种情况(至于为什么会出现两种情况,可以自行思考一下):
- 剩余2个字节
- 剩余3个字节
所以为了能够方便处理,会在末尾添加"="字符来保证总字节数为4的倍数,这样方便处理且可以及时发现错误。
注意
需要注意的是,Java中Base64Encoder的输入大多为字节数组(byte[])类型,所以对于中文或其他特殊字符等字符串获取字节数组时一定要指定编码,如:
string.getBytes("UTF-8");
/* 或者是 */
string.getBytes(StandardCharsets.UTF_8);
同时解码后一般也为字节数组类型,转换为字符串的过程中应该也指定相同的编码方式:
new String(byteArray, "UTF-8");
/* 或者是 */
new String(byteArray, StandardCharsets.UTF_8);
普通、url和MIME
选择
如有错误,欢迎指摘。欢迎通过各种渠道与我讨论,也欢迎通过左上角的“向TA提问”按钮问我问题,我将竭力解答你的疑惑。