未完成·python爬虫第8关nlpir人工智能
练习介绍
【程序功能】
我们将完成一个和语义识别相关的爬虫程序,输入任意词汇、句子、文章或段落,会返回联想的词汇。
【背景信息】
有一个非常牛的处理语言的网站nlpir,上面有非常多的处理语言的功能(如分词标注、情感分析、相关词汇)。
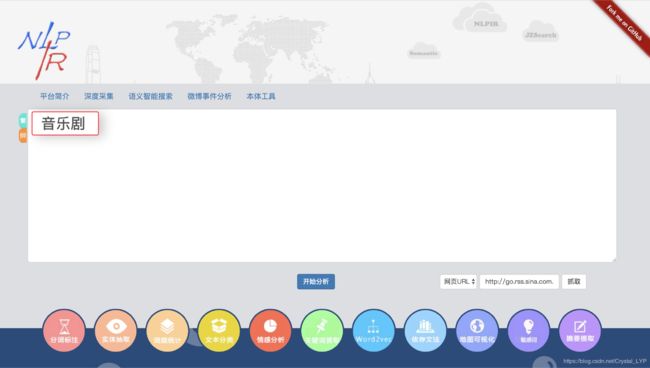
举个例子,我输入“音乐剧”:
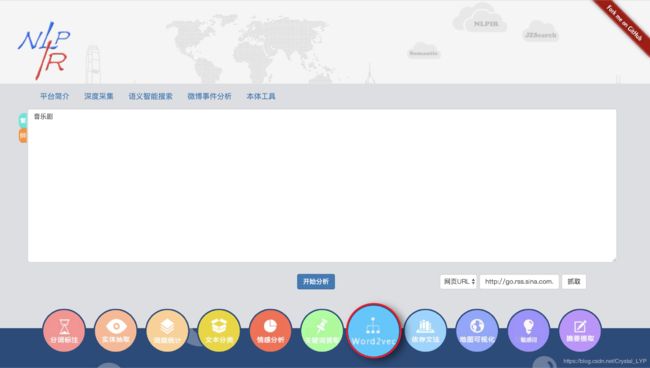
然后点击“Word2vec”(返回联想词汇的功能):
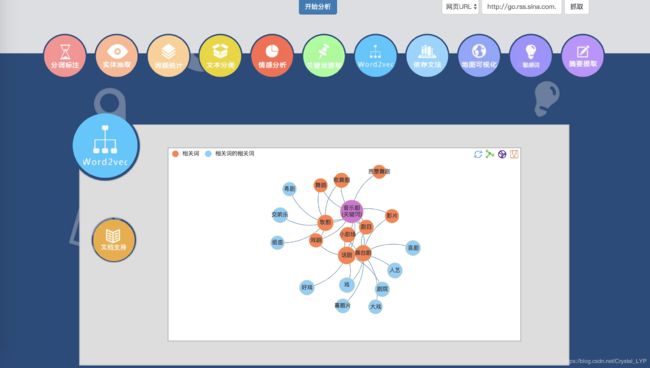
下面就会返回“音乐剧”的联想词汇:
当然这个网站还有其他的功能,像“分词标注”,就是把你输入的文本切成一个个的词,并且把这些词的词性都标出来;
还有“情感分析”的功能,就是分析你输入的文本里面“乐”、“恶”、“怒”、“哀”等情绪的占比是多少…
可是,这些功能的意义在哪呢?
在人工智能领域里,有一个很重要的领域,叫自然语言处理(NLP)。NLP致力于让计算机听懂人的话,理解人的话,在此基础上,人与计算机才有对话的可能。
而这个处理语言的网站的主要功能(如分词标注、情感分析、关键词提取、相关词汇等),就是NLP中的核心的底层技术。
我们所理解的siri、小爱同学、微软小冰,这些可以和人交流的对话系统,也是建构在NLP之上的。
无论最后建成的大楼有多么宏伟,都不可缺少坚实的地基。而对词语的基本处理,就是人工智能的一种“地基”,所以大家不要小觑这个网站中对语言处理的基本功能。
【实现路径】
刚刚提到,我们的程序有这样的功能:输入任意词汇、句子、文章或段落,会返回该联想词汇。
我们会用post发送请求,然后得到返回的结果。
会用到的知识点:
json和列表/字典的相互转换
import json
# 引入json模块
a = [1,2,3,4]
# 创建一个列表a。
b = json.dumps(a)
# 使用dumps()函数,将列表a转换为json格式的字符串,赋值给b。
print(b)
# 打印b。
print(type(b))
# 打印b的数据类型,为字符串。
c = json.loads(b)
# 使用loads()函数,将json格式的字符串b转为列表,赋值给c。
print(c)
# 打印c。
print(type(c))
# 打印c的数据类型,为列表。
字符串的方法
字符串类的对象,都有一个方法str.split(),可以通过指定分隔符对字符串进行切片。
str.split()需要输入参数,参数的内容是用于切分字符串的符号。来看示例。
a='郑云龙,阿云嘎,马佳,蔡程昱,高天鹤,余笛'
# a是一个大字符串,可以把这个字符串切开。
b=a.split(',')
# 指定分隔符是逗号,每碰到一个逗号,就切一下。
print(b)
# 打印b,结果会是一个由6个字符串组成的列表。
print(type(b))
# b是一个列表。
打印出来会是一个包含6个字符串的列表,列表的内容是[‘郑云龙’,‘阿云嘎’,‘马佳’,‘蔡程昱’,‘高天鹤’,‘余笛’]
分析过程
首先打开网站:
http://ictclas.nlpir.org/nlpir/
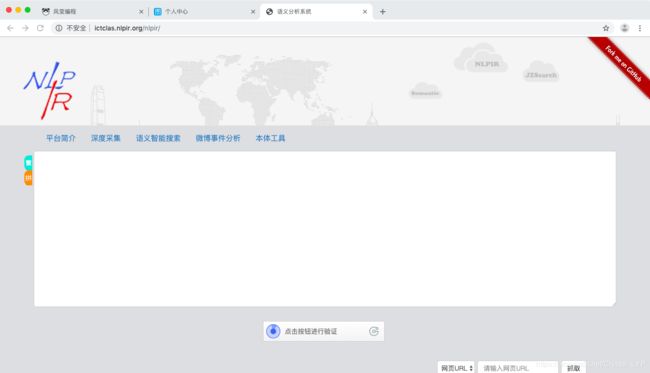
然后我们输入“音乐剧”,点击实体抽取,不知道为什么有些status_code显示500,不能访问,比如这里我点的第一个分词标注就显示红色,所以我们来看实体抽取。

headers里有请求网址的URL和请求方式是post,form data里是我们输入的内容content,
import requests,json
url = 'http://ictclas.nlpir.org/nlpir/index6/getWord2Vec.do'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
words = input('请输入你想查询的词汇:')
data = {'content':words}
res = requests.post(url,data=data,headers=headers)
data=res.text
# 以上,为上一步的代码
data1=json.loads(data)# 把json数据转换为字典print ('和“'+words+'”相关的词汇,至少还有:')# 打印文字
f=0# 设置变量ffor i in data1['w2vlist']: # 遍历列表
f=f+1
word = i.split(',') # 切割字符串
print ('('+str(f)+')'+word[0]+',其相关度为'+word[1]) # 打印数据
请输入你想查询的词汇:百度
和“百度”相关的词汇,至少还有:
(1)腾讯,其相关度为0.52671057
(2)词条,其相关度为0.47400305
(3)网易,其相关度为0.46367505
(4)搜索引擎,其相关度为0.4557111
(5)地图,其相关度为0.44420305
(6)阿里,其相关度为0.40419072
(7)关键字,其相关度为0.39202824
(8)网站,其相关度为0.3855128
(9)阿里巴巴,其相关度为0.37937027
(10)站长,其相关度为0.37208536