Hadoop 真的要死了吗?

10 月 3 日,Hortonworks 宣布将与其主要竞争对手 Cloudera 合作创建一家年收入约为 7.3 亿美元、拥有 2,500 名客户、市场估值达 52 亿美元的公司,这令很多人感到意外。
Splice Machine 首席执行官 Monte Zweben 表示:“我认为对于我们来说,这是个好消息。我们已经看到了运营由这两家公司和其他公司部署的所有数据湖的巨大机会,而这样的机会在两年前可能连想都不敢想”。
Confluent 的首席执行官兼 Apache Kafka 联合创始人 Jay Kreps 告诉 ZDNet:“这是一个聪明的举动。过去,这两家公司在同一产品上展开竞争,但具有讽刺意味的是,这却让竞争变得更加激烈”。
Unravel Data 首席执行官 Kunal Agarwal 说:“我认为这是件好事。我认为这两家公司在将他们的技术整合在一起,而不是试图相互攻击。他们现在可以专注于提供合适的机器学习工具、物联网平台和 AI 工具”。有一起学大数据的可以加群大数据资料分享群834325294,这是大数据学习交流的地方,不管你是小白还是大牛,小编都欢迎,不定期分享干货,包括我整理的一份适合大数据零基础学习大数据进阶资料。
但并非所有的反应都是积极正向的。 自由科技记者 Virginia Backaitis 在他的一片文章中写道:“我比较担心新的 Cloudera(或者可能是单独的 Cloudera 和 Hortonworks)是否会像管理团队和投资人所期望的那样快速增长”。
Bloomberg Opinion 专栏作家 Shira Ovide 同样不看好,他将这两家公司的合并说成是“两家水下公司的航海联盟”。
Teradata 首席运营官 Oliver Ratzesberger 告诉 Datanami:“这是一种 Sears-K-Mart 式的合并,这是他们唯一能够生存下来的方式。Hadoop 本身就变得无关紧要了”。
Anaconda 产品和营销高级副总裁 Mathew Lodge 在 VentureBeat 上发布的一篇文章中指出,大数据的中心已经从 Hadoop 转移到了云端,在对象存储系统(如亚马逊 S3、微软 Azure Blob Storage 和 Google Cloud Storage)中存储数据比在 HDFS 中便宜了五倍。
“领先的云计算公司并没有在 Cloudera 和 Hortonworks 上运行大型的 Hadoop/Spark 集群,相反,他们在容器基础设施上运行分布式云规模数据库和应用程序。现在是时候让 Hadoop 和 Spark 与时俱进了”。
让 Hadoop 更像云
事实上,Apache Hadoop 社区一直都在积极应对来自公有云供应商的威胁,包括像 Databricks 和 Snowflake 这样的初创公司。它们通过采用对象存储和容器技术让云端的大数据分析变得更便宜和更容易,并在上周获得了来自风险资本的 4.5 亿投资,
在今年早些时候发布的 Hadoop 3 中,用户可以选择使用擦除编码(erasure coding),需要大数据资料的加qun; 83,43,25,294这是 S3 等对象存储系统使用的数据保护技术,可将存储效率提高 50%。Hadoop 3.1 将为 YARN 中的 Docker 带来更强劲的支持。在宣布合并之前,Cloudera 和 Hortonworks 都在努力让他们的 Hadoop 发行版支持 Kubernetes。
但是,对于 Hadoop 社区来说,他们还有很多工作要做。上个月,Cloudera 首席战略官 Mike Olson 告诉 Datanami,社区还需要 12 到 24 个月才能在开源的 Apache Hadoop 项目中提供 Kubernetes 支持。
Olson 说:“YARN 擅长长期运行的批次作业调度,但要作为通用的集群资源管理框架,它还需要精心的设计和改进。未来 Kubernetes 将会入驻,并接管其中的一大部分内容”。
于是问题来了:当 YARN 被 Kubernetes 取代,并且 HDFS 被替换为任何兼容 S3 的对象存储系统时,Hadoop 还会是原来的 Hadoop 吗? 如果你认为 Hadoop 只是 40 个开源项目的集合——HBase、Spark、Hive、Impala、Kafka、Flink、MapReduce、Presto、Drill、Pig、Kudu,等等——那么也许这个问题就问得没有什么实际意义……
从实际角度来看,客户不可能因为两个最大的 Hadoop 发行商的整合而突然关闭多年来部署的数百万个 Hadoop 节点。对于已经建立了 Hadoop 数据湖的数千家公司而言,它们的重点将保持不变:从数据中获取价值。
尽管 Hadoop 可能已经变成了一项传统技术,但社区仍然有动力去调整它,以便支持新兴的需求,就像 IBM 对其大型机平台所做的那样。问题是它是否能够以足够快的速度让已部署的基础设施不断增长。
简化 Hadoop

自从十多年前第一个 MapReduce 程序上线以来,开发人员一直对 Hadoop 的复杂性颇有微词。即使像 Facebook 这样大的公司在使用 Hadoop 时也感到不便,特别是当他们需要通过底层的 Java 编程技能从 Hadoop 中及时获取信息时。
从那时起的一个发展趋势,就是消除这种复杂性,但 Hadoop 社区没能及时取得进展,因此未能阻止云供应商通过推出更简单的产品抢走市场份额。
Splice Machine 的 Zweben 表示:“我认为这是 Hadoop 的一次转型。软件供应商会使用越来越多的引擎,但从长远来看,不会有普通的企业会用它们……对于全球 2000 大企业来说,在背负 Hadoop 的重压之下很难做到这点”。
Unravel Data 公司的 Agarawal 表示,现在 Cloudera 和 Hortonworks 的工程师将齐心协力,以更好地应对构建系统方面的挑战,这些系统可以以本地、云端和混合的方式运行。“这是一个巨大的项目,仍然需要大量的工程师投入时间,把它打造成 Kubernetes 之上的一个成功的平台。他们还有很多开发工作要做”。
如果说在隧道尽头有一盏灯,那它就是:如果新 Cloudera 可以将 Hadoop 重新打造成一个混合的容器化平台,位于 Kubernetes 之上,并且可以将数据存储在任何与 S3 兼容的对象存储中,那么它就有可能实现部分目标,并占领一部分市场。 IDC 认为这是一个价值 650 亿美元的机会。
Agarwal 说:“我认为Cloudera 手里握有一张云供应商所没有的王牌,那就是他们的混合策略。 根据我们与这些财富 1000 强公司合作的经验来看,他们不会直接进入云端。他们想要的是这种混合策略。因此,我认为这将成为为这些客户创造价值的一条可行之路”。
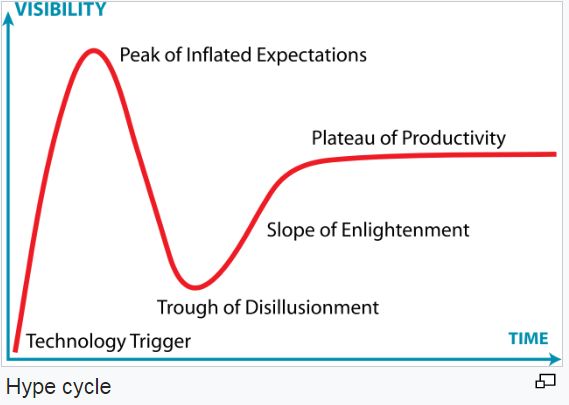
从幻灭到生产力
从一开始,Hadoop 基本上就是大数据的代名词。如果你遇到需要用大数据来解决的问题,那么答案肯定就是 Hadoop。
这当然是不对的,很多人都这么说——但这却是 Hadoop 多年来的一个营销口号。
Teradata 首席技术官史 Steven Brobst 说,为解决复杂问题而寻找银弹是人类的天性。“人们倾向于相信新技术将解决他们所有的问题,它会为你做所有的事情,甚至包括在早上给你端来一杯咖啡”。
Hadoop 曾经是被过度热炒的一项技术,而到了今天,这个头衔被 AI 拿走了。 Brobst 说:“当你的期望过度膨胀时,最终结果只会是失败。当技术被设置了不恰当的预期,就会跌落到幻灭的低谷”。
Brobst 继续说道:“我们现在所看到的 Hadoop 就正在经历这样的一个过程。Hadoop 正处于幻灭的低谷。‘放弃它吧,它已经不管用了!’其实它之所以不管用,是因为我们期望它能够完成所有的事情。对于这样不切实际的期望,除了失望之外,没有其他可能性”。
Brobst 说,虽然人们一直在 Hadoop 上挣扎,但这并不意味着 Hadoop 没有价值。相反,它意味着组织和用户应该要重新设置他们的期望,并问问自己它应该用在什么地方会更好。
他说:“Hadoop 和大数据终将走出 Gartner 炒作周期的幻灭低谷,然后进入生产力高原。这不是一个大数据战略,而是一个数据战略……它将成为生态系统的一部分,但不会解决所有问题”。
另外,InfoQ 在两年前策划过“Hadoop 十年”的迷你书,迷你书以 Hadoop 十年发展为主线,系统梳理了 Hadoop 这十年的变化以及技术圈的生态状况。
有一起学大数据的可以加群大数据资料分享群834325294,这是大数据学习交流的地方,不管你是小白还是大牛,小编都欢迎,不定期分享干货,包括我整理的一份适合大数据零基础学习大数据进阶资料。